By Gayathri Rajan and Gunesh Patil.
In our “Engineering Energizers” Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we meet Gayathri Rajan, Director of Software Engineering for the Agentforce Platform Testing team, who transformed AI quality testing for the organization.
Explore how her team overcame non-deterministic response validation obstacles, solved hour-long Data Cloud synchronization barriers, and eliminated UI testing limitations with innovative voice testing automation.
What is your team’s mission as it relates to AI quality testing across Einstein’s platform?
Our team faces unique challenges when testing non-deterministic AI responses, complex ecosystem integrations, and rapidly evolving features at a massive scale across Einstein products, including Agent Builder, Prompt Builder, and Data Cloud integration services. Serving as the final quality gateway, we ensure that reliable AI experiences are delivered to our customers.
Our mission is to empower the organization through comprehensive test frameworks, quality observability, automation infrastructure, and best practices that enable self-service quality across partner teams. Instead of creating dependencies, we focus on building scalable solutions that support the exponential growth of AI/ML products throughout the Einstein ecosystem.
With a deep, full-stack platform knowledge, our team acts as success engineers, accelerating the onboarding of new applications to Agentforce and swiftly diagnosing complex, multi-team integration issues. Without this solid quality foundation, unreliable AI features could reach customers, potentially damaging user experiences and our brand reputation. Our strategic role transforms quality from a constraint into a competitive advantage in the delivery of AI products.
What AI testing barriers were blocking quality validation — and how did dynamic assertions solve non-deterministic response challenges?
AI quality validation faced significant hurdles due to non-deterministic responses that traditional testing methods couldn’t manage. Voice capabilities, in particular, posed unique challenges because rigid pattern-matching failed to account for variations in dialects and voice-to-text conversions, leading to inconsistent results. Traditional approaches relied on exact keyword matching, but AI agents continuously evolve and produce different responses over time, often resulting in frequent test failures even when the behavior was functionally correct.
To overcome these barriers, we introduced dynamic assertion techniques that leverage AI evaluators using semantic similarity algorithms. These algorithms measure contextual relevance rather than exact matches, ensuring that the validation process remains robust and adaptable. Our LLM-based evaluation pipeline now compares actual agent responses to expected outputs using semantic understanding. Validation passes when the similarity scores meet predefined thresholds, effectively eliminating the rigid keyword prediction requirement. This approach allows teams to focus on specifying the intent behind responses rather than their exact wording, maintaining high accuracy standards while accommodating the continuous evolution of AI agents.

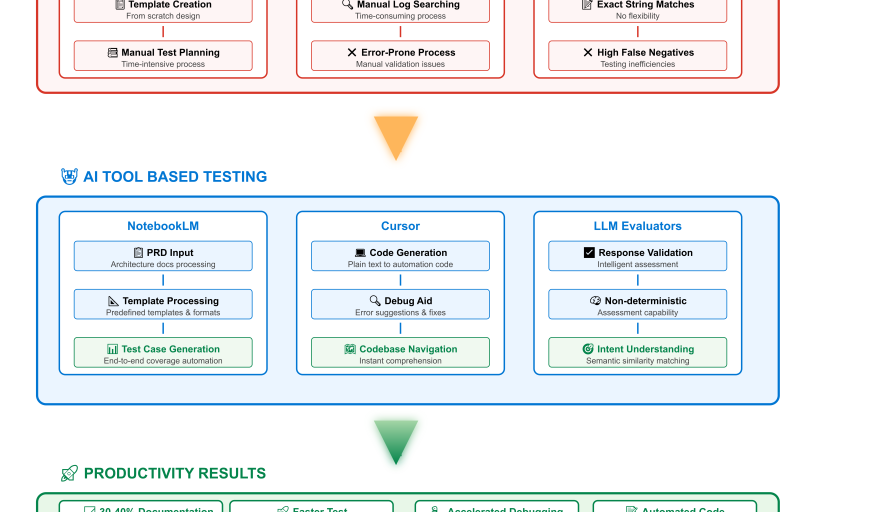
Productivity gains progression leveraging AI toolsets.
What Einstein platform integration complexity emerged — and how did decoupled validation solve Data Cloud synchronization barriers?
Testing across Einstein’s entire ecosystem uncovered critical infrastructure obstacles due to asynchronous data propagation between components like Agent Builder, Prompt Builder, and the Agents API, as well as Data Cloud. Data from operations often took over an hour to appear in Data Cloud DMO tables, which created significant constraints for end-to-end automation pipelines. Traditional wait-based strategies were impractical because quality monitoring services run on hourly job cadences.
To address these challenges, the team developed an innovative decoupled validation strategy using an N-minus-one validation architecture. This asynchronous validation system processes Data Cloud data from previous test execution cycles, eliminating the need to wait for current test run synchronization. Cron job schedulers are configured to run every 3-4 hours, with each cycle validating results from the previous cycle through automated data integrity checks. This approach not only eliminates hour-long delays but also ensures complete coverage and data consistency across all Einstein ecosystem components.
What scalability limitations prevented comprehensive AI feature testing — and how did voice testing automation eliminate UI constraints?
Monthly GA releases demanded comprehensive AI feature testing, which traditional UI-based methodologies couldn’t handle at scale. UI testing had several limitations: slow interactions that extended testing cycles, flaky dependencies that caused test instability, physical device requirements that limited parallel execution, and an inability to manage the complexity of voice testing across various dialects.
To overcome these challenges, the team implemented UI testing and an API-first testing approach using the LiveKit Python SDK with audio virtualization layers. This solution generates programmatic voice input through Python scripts, feeding audio files directly into LiveKit room configurations without the need for physical devices or browser UI interactions. The API virtualization layer eliminated slow UI interactions, removed flaky dependencies, enabled seamless integration with the FIT (Functional Integration Testing) infrastructure, and provided unlimited horizontal scalability. As a result, manual testing workflows that previously took three engineering days now complete in just one hour through automated pipelines.
What RAG validation accuracy obstacles emerged — and how did AI prompt engineering solve complex document evaluation challenges?
RAG validation encountered complex input processing issues with enterprise documentation, which often includes embedded images, infographics, multi-format tables, and cross-referenced content spanning up to 700-page technical manuals. Traditional evaluation methods struggled to handle distributed answers that required navigating between pages, referencing footnotes, and correlating citations, all of which demand human-like contextual understanding across document hierarchies.
To address these challenges, the team implemented systematic prompt engineering using Gemini with custom LLM (Large Language Model) prompt templates and defined user personas: technical expert, domain novice, and casual researcher. The AI prompt engineering system generates a diverse set of test scenarios: 50% complex questions that require deep document analysis, 10% out-of-context questions for negative testing, and 30-40% straightforward single-section answers. This approach significantly boosted productivity by reducing 4.5 days of manual analysis to just 2 hours of automated generation. It produced over 250 test scenarios across 20 documentation sets, resulting in more than a 1000% improvement in test data creation.
What engineering productivity barriers were hampering development velocity — and how did AI development tools transform workflow efficiency?
Development workflows were hindered by complex debugging, extensive manual documentation analysis, and repetitive coding tasks. Debugging voice projects required tracing single utterances through complex event chains in multi-layered logs, while creating test plans involved sifting through verbose PRDs and architecture documents for multiple Einstein service integrations.
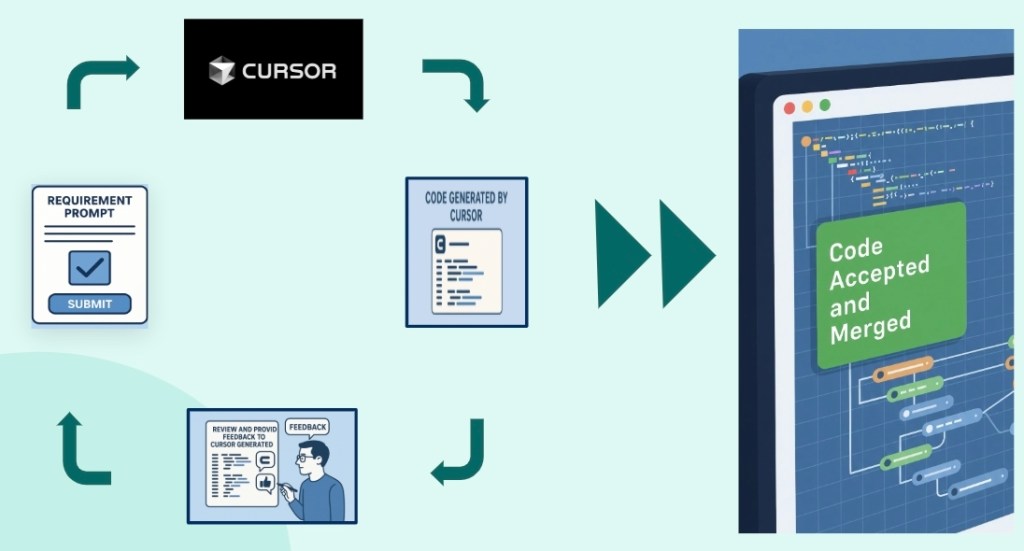
NotebookLM streamlined test case generation by processing PRDs, Agentforce architecture specs, and technical documentation using predefined templates. This reduced time by 30-40% and achieved 80-90% accuracy, needing minimal manual adjustments. Cursor improved debugging by enabling quick conversation flow tracing through VoiceCall-ID correlation, eliminating manual log searches. It also sped up development with intelligent code generation and automated error resolution suggestions.
By integrating these AI development tools, the team achieved:
- Reduced coding time and error rates
- Faster codebase understanding through instant technical summaries
- Intelligent debugging with automated root cause analysis
- Enhanced test coverage via logical scenario recommendations
This integration allows for faster test coverage expansion and lets engineering teams focus on high-value architectural innovation instead of repetitive maintenance tasks.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.