Written by Pawan Agarwal and Peiheng Hu
In our “Engineering Energizers” Q&A series, we explore the transformative journeys of Salesforce engineering leaders who are spearheading significant advancements in their fields. Today, we meet Pawan Agarwal, Senior Director of Software Engineering, who leads the Einstein AI Platform team — a team dedicated to enhancing the performance and capabilities of large language models (LLMs).
Read on to learn about the initial challenges Pawan’s team faced with LLM latency and throughput, their comprehensive evaluation of tools leading to the adoption of Amazon SageMaker, and the subsequent performance enhancements achieved.
What is your team’s mission?
Our AI Platform team is committed to enhancing the performance and capabilities of AI models, with a particular focus on LLMs. These models are designed to advance state-of-the-art natural language processing capabilities for various business applications. Our mission is to continuously refine these LLMs and AI models by integrating state-of-the-art solutions and collaborating with leading technology providers, including open-source communities and public cloud services like AWS. This ensures that our customers receive the most advanced AI technology available.
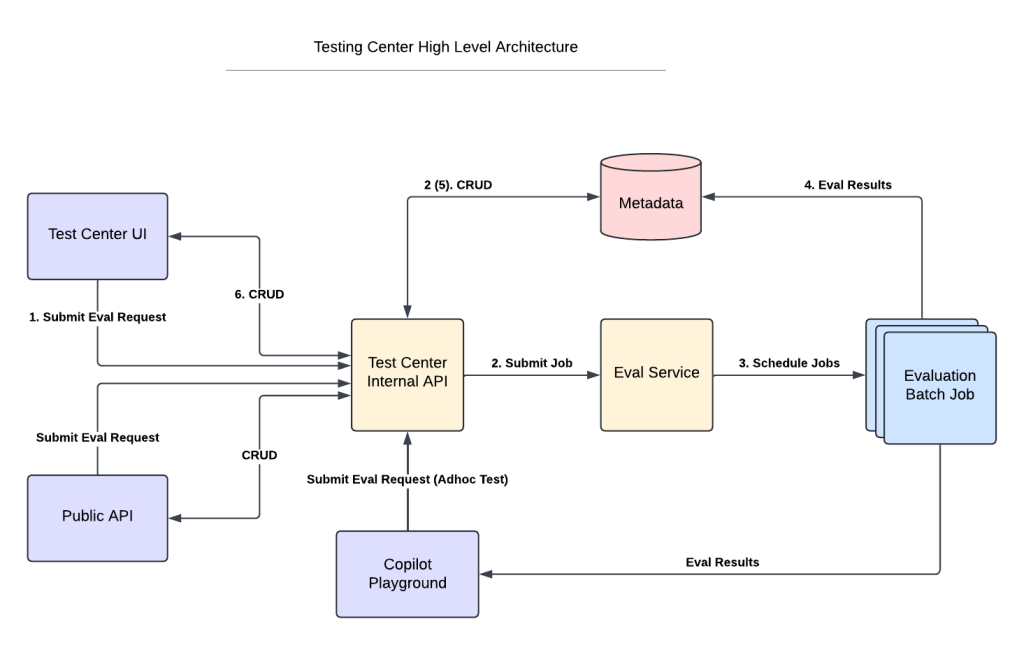
Can you describe the initial challenges your team faced with Einstein for Developers‘ LLM in terms of latency and throughput?
Initially, our team faced significant challenges, which were particularly pronounced when managing large volumes of data and multiple concurrent requests. As a result, we experienced slower response times and limited scalability, which negatively affected the overall user experience and system efficiency.
Pawan explains what makes Salesforce Engineering culture unique.
How did your team conclude that Amazon SageMaker was the best solution for your performance issues?
We conducted a comprehensive evaluation of various tools and services, including open-source options and paid solutions like NVIDIA Triton hosting, as well as emerging startups offering hosting solutions such as Run.AI and Mosaic AI. After assessing these options, we found that Amazon SageMaker provided the best access to GPUs, scalability, flexibility, and performance optimizations for a wide range of scenarios, particularly in addressing our challenges with latency and throughput.
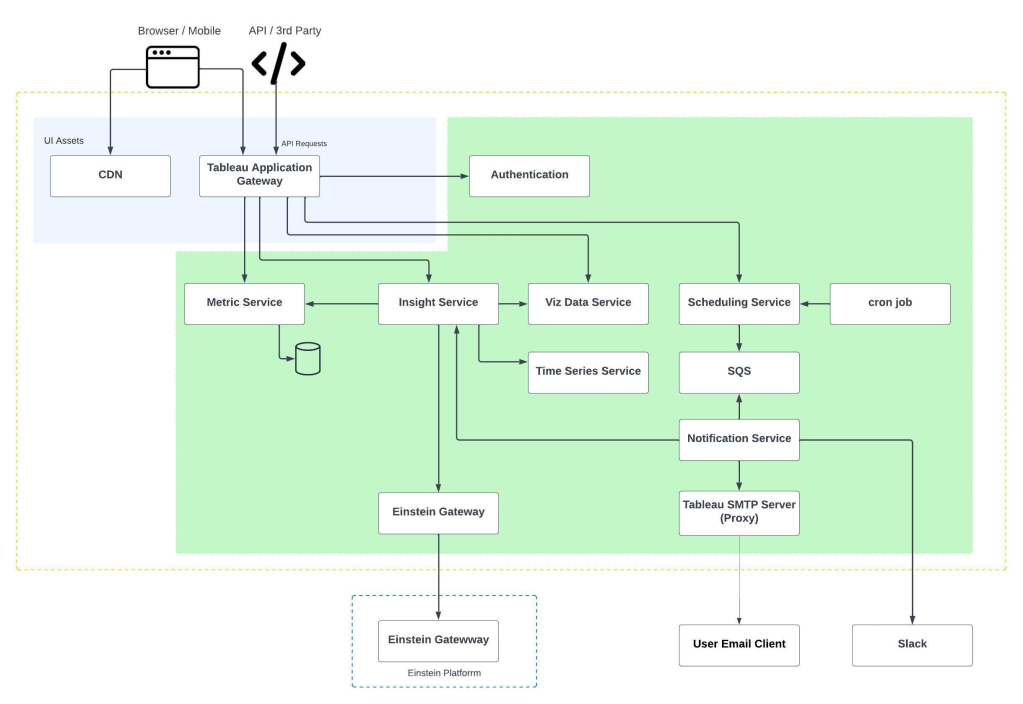
What were the specific features of Amazon SageMaker that the team utilized to tackle the latency issues in the LLM?
The team utilized several specific features:
- Multiple Serving Engines: SageMaker supports various serving engines like DeepSpeed, Hugging Face TGI, vLLM, and NVIDIA’s FasterTransformer and TensorRT LLM, which allows the team to experiment with and select the most efficient engine for reducing latency. This flexibility is crucial as LLM latency heavily depends on the performance of the inferencing engines.
- Advanced Batching Strategies: SageMaker enables different batching strategies, which group multiple requests together before they hit the model. That optimizes the use of GPU resources and balances throughput with latency, ultimately reducing the latter.
- Efficient Routing Strategy: With the capability to handle multiple model instances across several GPUs, SageMaker’s routing strategy ensures that traffic is evenly and efficiently distributed to model instances, preventing any single instance from becoming a bottleneck.
- Access to High-End GPUs: SageMaker provides easy access to top-end GPU instances, which are essential for running LLMs efficiently. This is particularly valuable given the current market shortages of high-end GPUs. The platform also supports auto-scaling of these GPUs to meet demand without manual intervention.
- Rapid Iteration and Deployment: While not directly related to latency, the ability to quickly test and deploy changes using SageMaker notebooks helps in reducing the overall development cycle, which can indirectly impact latency by accelerating the implementation of performance improvements.
These features collectively help in optimizing the performance of LLMs by reducing latency and improving throughput, making Amazon SageMaker a robust solution for managing and deploying large-scale machine learning models.
Can you provide an example of how Amazon SageMaker significantly enhanced the throughput of the LLM?
Einstein for Developers’ LLM, a 7 billion parameter model, was struggling with performance. Initially, it could only handle six requests per minute, with each request taking over 30 seconds to process. This was far from efficient and scalable. However, after integrating SageMaker along with NVIDIA’s FasterTransformer engine, there was a significant improvement. The system now handles around 400 requests per minute with a reduced latency of approximately seven seconds per request, each containing about 512 tokens.
This enhancement was a major breakthrough, demonstrating how SageMaker’s capabilities were instrumental in optimizing the throughput of the LLM.

Latency and throughput changes with different techniques for Codegen1 and Codegen2.5 models.
What was the main challenge your team faced when integrating Amazon SageMaker into their existing workflow?
The primary challenge was enhancing the SageMaker platform to include specific functionalities that were essential for our projects. For instance, we needed robust support for NVIDIA’s FasterTransformer to optimize our model performance. Through a productive collaboration with the SageMaker team, we successfully integrated this support, which initially was not available.
Additionally, we identified an opportunity to improve resource efficiency by hosting multiple large language models on a single GPU instance. Our feedback led to the development of the Inference Component feature, which now allows us and other SageMaker users to utilize GPU resources more effectively. These enhancements were crucial in tailoring the platform to our specific needs and have significantly benefited our workflow.
How did the team evaluate the improvements in LLM performance before and after optimization with SageMaker?
To assess the performance of the large language models (LLMs), we focused on two key metrics: throughput and latency.
- Throughput is measured by the number of tokens an LLM can generate per second.
- Latency is determined by the time it takes to generate these tokens for individual requests.
We conducted extensive performance testing and benchmarking to track these metrics. Before using SageMaker, our models had a lower token-per-second rate and higher latencies. With SageMaker optimization, we observed significant improvements in both throughput and latency, which also led to a reduction in the cost to serve, ultimately saving a considerable amount of money. This cost efficiency is another crucial measure of performance enhancement.
Pawan shares what keeps him at Salesforce.
What key lessons were learned from optimizing models in Amazon SageMaker for future projects?
- Stay Updated: It’s crucial to keep up with the latest inferencing engines and optimization techniques as these advancements significantly influence model optimization.
- Tailor Optimization Strategies: Employ model-specific optimization strategies like batching and quantization with careful handling and coordination, as each model may require a tailored approach.
- Implement Cost-Effective Model Hosting: Focus on optimizing the allocation of limited GPU resources to control expenses. Techniques such as virtualization can be used to host multiple models on a single GPU, reducing costs.
- Keep Pace with Innovations: The field of model inferencing is rapidly evolving with technologies like SageMaker, JumpStart, and Bedrock. Developing strategies for adopting and integrating these technologies is imperative for future optimization efforts.
Learn More
- Hungry for more Einstein stories? Check out how how the Einstein team developed a blueprint for creating the new, unified AI platform from siloed legacy stacks in this blog.
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.