In our “Engineering Energizers” Q&A series, we explore the pioneering work of Salesforce engineering leaders. Today, we highlight Srini Krishnamoorthy, Vice President of Software Engineering at Salesforce and the leader of Data Cloud’s Storage and Metadata Team. Srini’s team developed Zero Copy, a feature that transforms how Salesforce interacts with external data sources, enabling real-time analysis and decision-making without the need for traditional data migration.
Learn how Srini’s team tackled intricate technical challenges to achieve seamless data integration, ensured consistent data synchronization across platforms, and scaled the system to meet the demands of Salesforce’s most data-intensive customers.
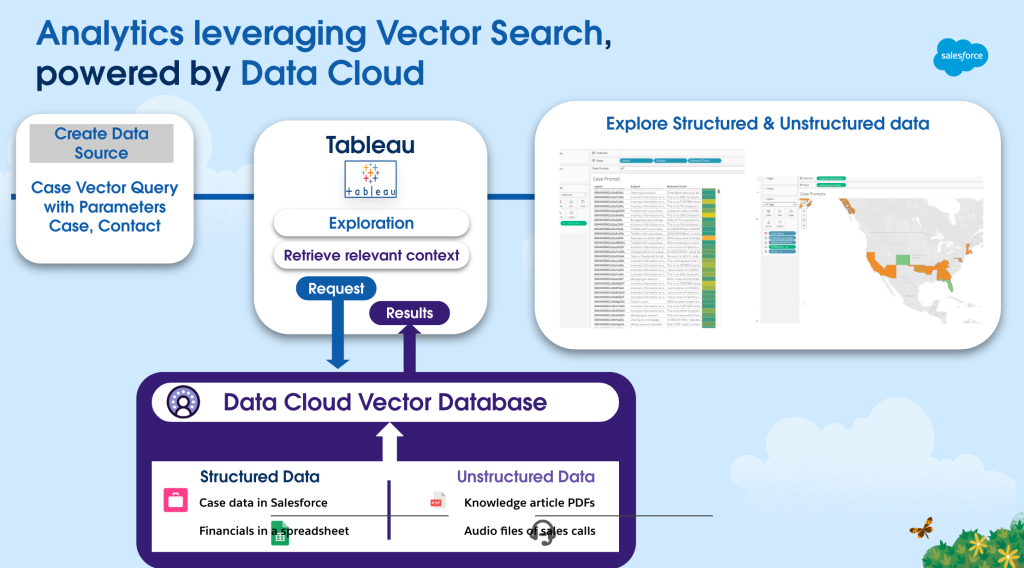
What is Zero Copy and what is its purpose within the Data Cloud ecosystem?
Zero Copy is a foundational feature of Data Cloud, designed to address the challenge of accessing data from external systems without requiring complex and costly data migrations. Historically, companies had to duplicate or move external data into Salesforce for analysis, resulting in inefficiencies and delays.
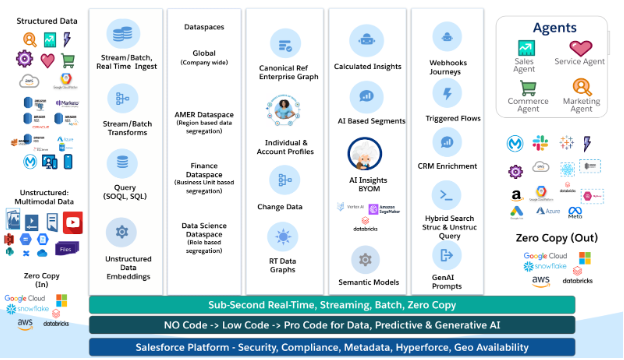
Depiction of Data Cloud components and how Zero Copy fits into Data Cloud’s overall architecture.
With Zero Copy, Salesforce can query data directly from external sources such as Snowflake and Databricks, eliminating the need for data duplication. This capability empowers customers to access and analyze data in real time, ensuring they can maximize the value of their external data investments without incurring additional overhead.
As a key component of the Data Cloud ecosystem, Zero Copy helps to break down data silos and ensures that customer data is always up-to-date and readily available for analysis. This supports Data Cloud’s mission to deliver unified and actionable insights, enabling businesses to make informed decisions swiftly and effectively.
How does Zero Copy support Data Cloud?
Zero Copy significantly boosts Data Cloud’s ability to unify and analyze customer data from diverse sources. By facilitating live querying, caching, and real-time data integration, Zero Copy enables Data Cloud to provide a comprehensive 360-degree view of the customer, even when data is stored in external platforms like Snowflake, Databricks, Google BigQuery or AWS Redshift.
In just the past six months, Zero Copy has allowed Data Cloud to query over 4 trillion records from external systems without moving any data. This capability not only reduces the time and cost associated with traditional ETL processes but also ensures that Data Cloud can deliver real-time insights and seamless data integration, meeting the demands of our most data-intensive customers.

Month over month growth in the number of records queried from external systems through Zero Copy data federation.

Month over month growth in the number of records accessed from Data Cloud through Zero Copy data sharing.
Zero Copy also facilitates bidirectional access, allowing external systems to query Data Cloud data on demand without the need for data duplication. Over the past six months, Zero Copy has enabled external systems to query over 250 billion records from Data Cloud seamlessly, without moving any data.
What were some of the key technical challenges your team encountered while developing Zero Copy?
One of the primary challenges was designing a system that could abstract the data’s origin, whether it was stored natively within Salesforce or in external platforms like Snowflake or Databricks, without burdening the user with these complexities.
To address this, our team developed a metadata management layer that acts as the central point for determining where the data resides and how queries are executed. When a query is made, the system first consults the metadata layer to identify the data source. Then, Zero Copy decides whether to process the query internally or push it down to the external system.
Here’s how it works step-by-step:
- Metadata Layer Management: The system references its metadata management layer, which contains information on where the data is stored (e.g., Snowflake, Databricks).
- Query Pushdown: Based on the data’s location, Zero Copy determines whether to process the query within Salesforce or push it down to the external system. For example, if the data resides in Snowflake, the system utilizes Snowflake’s compute capabilities to filter and aggregate the data before pulling it back into Salesforce.
- Data Retrieval and Processing: Once the external system processes the query, Zero Copy retrieves only the necessary data, minimizing data transfer and reducing latency.
This step-by-step decision-making process enables Zero Copy to handle diverse data sources seamlessly. It ensures that customers can access their external data in real time without needing to duplicate or migrate it, which was a significant challenge for the team to overcome.
How does customer feedback influence Zero Copy’s development and help address scalability challenges?
Customer feedback has played a pivotal role in shaping Zero Copy’s development, particularly in terms of scalability. Initially, we anticipated that most customers would handle tens of millions of rows of data. However, soon after launch, we realized that customers needed to work with hundreds of millions or even billions of rows.
This demand prompted us to invest heavily in scaling Zero Copy’s capabilities, resulting in innovations like file federation and query pushdown. For instance, based on customer feedback, we enhanced the system to support over a billion rows in a single query. We invested in enhancing our query pushdown, where queries are processed at the source (e.g., Snowflake) to filter and aggregate data before returning only the necessary results to Salesforce.
Early adopter customers from various industries tested these features in real-world scenarios, and their feedback has been invaluable in refining the system and ensuring it meets their performance requirements. These enhancements not only bolster Zero Copy’s scalability but also ensure that Data Cloud delivers unified, real-time insights across disparate data sources.
What was the toughest problem your team solved creatively while building Zero Copy?
One of the most challenging issues we faced was maintaining data consistency and synchronization across systems while enabling real-time querying. To address this, we created our “bidirectional data abstraction” model. This model allows Salesforce to not only read from external systems like Snowflake and Databricks but also share back insights gained within Salesforce to these external platforms in real time, without copying over data.
This approach means that if a customer performs a segmentation analysis or creates a derived insight within Salesforce, they can push those results back to Snowflake without having to extract and re-import the data. The challenge lay in ensuring data consistency and synchronization between systems. For instance, when dealing with over 500 million rows in a live dataset, any inconsistencies or delays in synchronization could lead to data mismatches and inaccuracies.
To overcome this, we developed an intelligent metadata tracking system that logs, tracks, and reconciles every read and write operation across systems, maintaining a consistent view of the data at all times. This level of innovation sets Zero Copy apart, significantly enhancing Data Cloud’s ability to deliver seamless data integration and real-time analytics for our customers.
Learn More
- For a deep dive into the Zero Copy feature, read this article.
- Learn Data Cloud’s secret for scaling massive data volumes in this blog.
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.