Phoenix is a relational database with a SQL interface that uses HBase as its backing store. This combination allows it to leverage the flexibility and scalability of HBase, which is a distributed key-value store. Phoenix provides additional functionality on top of HBase, including SQL semantics, joins, and secondary indexing.
Secondary indexing, which enables efficient queries on non-primary key fields, is central in many use cases. At Salesforce, we saw this to be the case and recognized that some use cases demand a higher level of data consistency for secondary indexes than what was offered in Phoenix. We set out to redesign global secondary indexes to meet the strong data consistency demand.
Secondary Indexing in Phoenix
An HBase table can be viewed as a set of cells where each cell is identified by a key, which is composed of a row key, family name, column qualifier, and timestamp. A cell holds a value expressed using a byte array. So essentially, a cell is a key-value structure and HBase is a key-value store. A row is identified with a row key and is the set of cells with this row key. Rows in an HBase table are sorted by the row key of the table. Phoenix tables are backed by HBase tables, and the primary key of a Phoenix table maps to the row key of the underlying HBase table.
Although Phoenix directly leverages HBase row key indexing to provide primary key indexing for Phoenix tables, accessing a Phoenix table through a non-primary-key column requires scanning the entire table without having secondary indexing. For use cases where low latency is required when querying by a non-primary key field, having to scan through all the rows can be prohibitively slow and expensive.
Phoenix offers two types of secondary indexing, local and global. Local indexes are optimized for write performance and global indexes for read performance. As of this writing, at Salesforce we have deployed only global indexes for our use cases. In the following discussion, secondary indexing refers to global secondary indexing.
Phoenix implements global secondary indexing by pairing a base table (the table that holds the entire user data) with physically separate tables that are indexed on a different key. The base table is referred to as the data table and the table(s) used for secondary indexing is referred to as index tables. Thus, each index table is also backed by a separate HBase table, and the secondary key implemented by this Phoenix table maps to the row key of the HBase table, as shown in the following diagram.
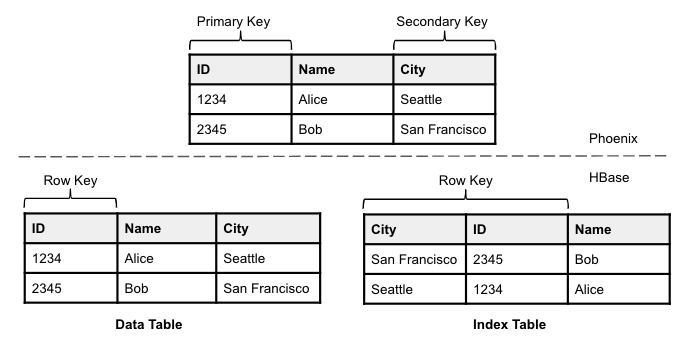
The row key of an index table is composed of the secondary key for the index table and the primary key for the data table, as shown in the diagram. Appending the primary key to the secondary key makes the row key unique and also provides a direct mapping from a secondary key to a primary key. Phoenix applications do not need to know these details as they do not interact with index tables directly. Phoenix is responsible for keeping an index table synchronized with the data table, and uses index tables to speed up queries on the data tables.
The Consistency Challenge
Creating a separate HBase table for each index table that is sorted by a secondary index key is not sufficient by itself to deliver strongly consistent global secondary indexing in Phoenix. The strong consistency here means that regardless of whether a query is served from a data table or index table, the same result is returned. Keeping the contents of physically separate tables always consistent, but still meeting performance and scalability expectations, is a challenging problem in distributed systems.
Strong consistency implies that Phoenix must update a data table and its index tables atomically in order to keep them consistent. HBase tables are divided horizontally by row key range into regions called table regions. Table regions are assigned to the nodes in the cluster, called region servers, and these serve data for reads and writes. Updating a table that has one or more global indexes requires updating multiple HBase table regions, which are likely distributed across more than one region server. This poses the challenge of maintaining consistency among these distributed table regions. For mutable tables, this challenge is even greater as we need to support inserting rows and also support updating existing rows. If updating an existing row results in modifying a secondary key, then we must also delete the existing index row with the old index row key, in addition to adding a new row with the new index row key. The table region for the new index row can be different from the table region for the old row. This means that deleting and updating index rows on the same index table may need to be handled on different HBase region servers responsible for these table regions.
At Salesforce, we designed our solution from the ground up to address this consistency challenge. We will explain the design gradually starting from a subset of the problem domain.
Immutable Uncovered Indexes
An index table where the secondary index keys are never modified will be called immutable. This is a weaker definition of immutability since it allows the data table columns to be overwritten, as long as the columns used for secondary indexes are not overwritten. This means when an index row is created for a given data table row, the row key for this index row stays valid until the data table row is deleted.
An index that is used only to map its secondary key to the primary key will be called uncovered. An uncovered index includes only the columns corresponding to the data table columns for the secondary and primary keys. An uncovered index implies that the index table by itself will not be used to serve user queries on the data table. The index will be used to identify data table rows affected by a given query and the rest of the column values will be picked up from the data table. In other words, an uncovered index never covers a query on its data table.
If we were to provide a strongly consistent global index solution for only immutable uncovered index use cases, we would provide a solution that is much simpler than the solution for all use cases. In order to design a simple solution, we take advantage of the fact that the data table is the source of truth, and an index table is used to only map secondary keys to the primary keys to eliminate full table scans. The correctness of such a solution is ensured if for every data table row, there exists an index row. Then our solution to update the data tables and their indexes in a consistent fashion would be a two-phase update approach, where we first insert the index table rows, and only if they are successful, then we update the data table rows. This is illustrated in the following diagram.
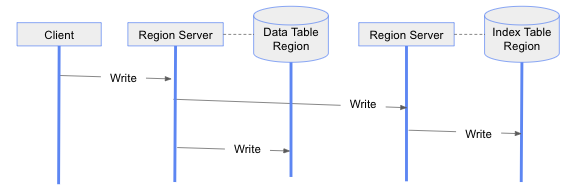
As mentioned earlier, applications do not need to know the details of the index tables and do not need to interact with them directly. Applications express their updates and query requests on their data tables without considering index tables. In the above diagram, an application through the Phoenix client updates a row on a data table. This update is done on the corresponding table region by the region server assigned to this table region. The region server first updates the index table before updating the data table region. To do that, it issues an RPC (Remote Procedure Call) to update the region server assigned for the index table region holding the corresponding index row key. The region server for the index table region very likely will be different than the region server for the data table region. Thus the update on the index table region needs to be done using an RPC. In our discussion, the exchanges between clients and servers and among servers are assumed to be done using RPCs.
Since the index tables are immutable, the secondary index columns of the data table are never modified in this case. This means that we do not need to delete existing index rows but simply insert new index rows when data table rows are updated. If the index table updates fail, then we simply abort the write transaction by not updating data table rows. This may leave some stale index rows. However, this does not pose a correctness issue as we do not use an index table as a source of truth. We always refer to the data table to serve queries, even if the index table covers a given query. The stale rows can be removed from index tables as part of a background cleanup process.
For deleting a data table row, we use a three-phase approach, as shown in the following diagram. In the first phase, we read the data table row to be deleted, and from the row key for the corresponding index table row. In the second phase, we delete the data table row. If successful, then we delete the index table row. Again, if this three-phase approach fails at the second or last phase, the data table row can be deleted, but the corresponding index row stays intact. However, again, this does not pose a correctness issue since we use an index table only to map index rows to data table rows. If the map points to a non-existent data table row, then we consider that the index table row is stale and should be ignored.
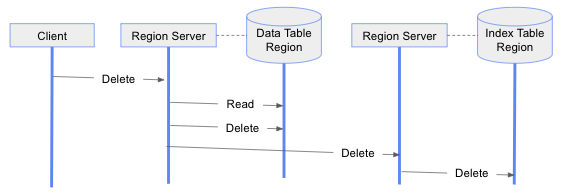
Stale index rows will be a side product of write operation failures. As such, the number of stale rows is expected to be a very small fraction of the number of successfully written rows. Their existence should not impact read performance significantly and the cleanup process for removing them should not need to be run frequently.
It is also worthwhile to note that if there are multiple index tables for a data table (in order to have multiple secondary index keys on this data table), the updates and deletes on these index tables can be done in parallel. All the index table rows can be updated in parallel in the first phase of the two-phase update, and similarly all the index rows can be deleted in parallel in the last phase of the three-phase delete.
Immutable Covered Indexes
Given that we have a solution for strongly consistent immutable uncovered indexes, we would like to extend it to covered immutable indexes. Here, a covered index means that a query can be served directly from the index table, if the index table covers the query. An index table covers a query if the index table includes all the columns that are necessary to serve this for this query. Covered index tables can include not only primary and secondary key columns but also any other data table columns to cover queries.
A strongly consistent covered index implies that a query should generate the same result whether it is served directly from the index table or data table. To extend the previous solution for covered indexes, but at the same time prevent returning inconsistent query results, we need to know if data table rows are updated successfully after index table rows were updated. We can achieve this by maintaining status information in every index row. To do that, we add a hidden index column to index tables to store the status information. When we do update an index table row as part of updating a data table row, this hidden column value is set to “unverified” initially. After successfully completing the data table row update, the hidden column value on the index row is set to “verified”. Maintaining status information for each index row (that is, “unverified”/“verified” status), and updating an index row in two phases, amounts to implementing a two-phase commit protocol to update the index row. This means that we complete data and index table updates in three phases, as shown below. In this three-phase update operation, the next phase is executed only after the current phase is successful. If this three-phase update operation fails to complete, we may leave some unverified index rows in the index tables.
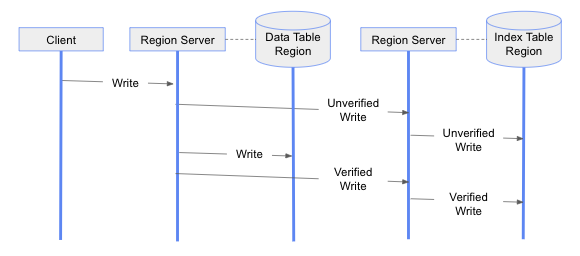
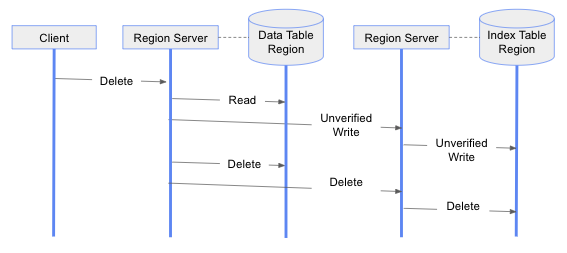
For deleting data table rows, we employ a four-phase approach. As in the previous solution, we start with retrieving the row to be deleted from the data table, and construct the index table row keys. In the second phase, we set the status of these index table rows to “unverified” to prepare them for deletion. In the third phase, we delete the data table row. At the last phase, we delete the index table row. This is shown in the following diagram. Again, we only move to the next phase if the current phase is successful. If this four-phase delete operation fails to complete, we may leave some unverified index rows in the index tables.
When we serve queries from index tables directly, we check if the index rows are verified. If an index row is unverified, then we repair this index row from the data table row. Given that unverified index rows exist primarily due to write operation failures, the index table rows will be almost always verified, and once in a while we need to do index row repairs.
The correctness of this solution is due to using a two-phase commit protocol for updating index tables, and using a read-repair approach to recover the index rows that did not successfully go through the two-phase commit update.
Mutable Indexes
Now that we have a strongly consistent immutable indexing solution, we can extend it for mutable indexes as presented in the second part of this blog.