By Idan Asher, Mendi Neymark, Shirel Vaiman, Dongwei Feng, and Neela Gouda.
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. This edition features Shirel Vaiman, Senior Manager, Software Engineering, whose Service Delivery team leads the platform engineering foundation for Data 360, delivering resilient infrastructure for hyperscale data workloads across Hyperforce.
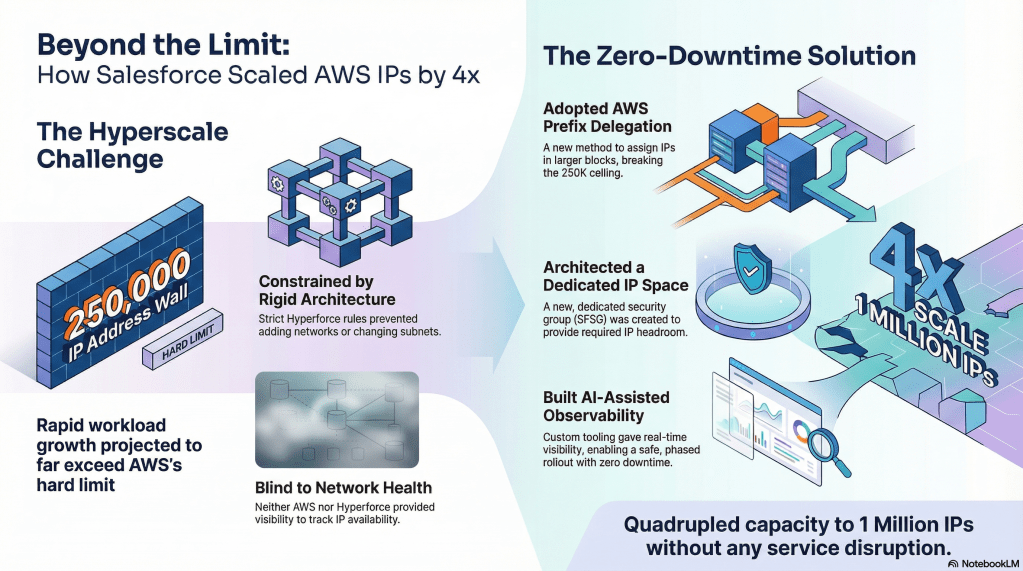
Explore how the team overcame AWS’s 250,000-IP NAU hard limit using prefix delegation, navigated Hyperforce’s architectural constraints, and introduced custom observability with AI-driven validation for a zero-downtime rollout of a new IP allocation model at massive scale.
What is your team’s mission supporting Data 360’s infrastructure and hyperscale reliability?
We establish the foundational infrastructure for Data 360, ensuring reliable, secure, and scalable operations. We manage networking, EKS clusters, service mesh, and critical Hyperforce integration points that power every Data 360 service. This involves implementing Hyperforce patterns, adapting AWS capabilities to a Salesforce-compliant model, and guaranteeing all compute and routing paths meet strict requirements for throughput, isolation, and lifecycle safety.
As Data 360 expanded, our mission evolved from maintaining reliability to enabling hyperscale growth. We prepared the platform for a significant increase in network capacity through deep architectural evaluation, cross-team coordination, and forward-looking design. Our responsibility became preventing infrastructure boundaries from limiting customer onboarding or data-processing workloads, necessitating new scaling constructs, enhanced observability, and robust tooling for safe operation across all environments.
What architectural constraints shaped Data 360’s path to supporting 100,000 tenants and expanded IP capacity?
Three core constraints defined the challenge:
- AWS NAU Limit: A 250,000 IP per VPC limit, significantly less than projected demand.
- Workload Growth: Increased Spark-driven data processing amplified IP allocations per tenant, stressing the network.
- Hyperforce Architectural Rules: Strict SFSG (Salesforce Security Group)-based IP allocation limits, immutable subnet structures, and no conventional AWS expansion paths meant all scaling occurred within existing Hyperforce constraints.
Hyperforce’s strict networking boundaries meant we could not simply increase CIDR blocks. Instead, we designed an approach aligning with the platform’s security, routing, and provisioning models. This transformed a simple scaling exercise into a deep architectural challenge: enabling large-scale growth without altering Hyperforce’s structural rules.
How did the team break the AWS 250,000-IP NAU limit and implement prefix delegation to reach the required scale?
Our big win for getting past AWS’s NAU limit was prefix delegation. But implementing it wasn’t a simple flip of a switch. This method assigns IPs in 16-address blocks, which is tricky to manage in active environments with running services, long-lived pods, and existing allocations. Without careful planning, we could have ended up with fragmentation or less usable capacity.
We actually collaborated with AWS to tailor prefix delegation for Hyperforce – an integration that was entirely new within Salesforce. Then, we partnered with our internal networking, Kubernetes, and provisioning teams to ensure it had full platform support. After Hyperforce enabled the capability, we carefully rolled it out in phases. This involved close collaboration with the Data 360 Compute Layer team who is responsible for the Spark workloads to ensure zero downtime and impact on our data pipelines, validating available ranges, monitoring allocation patterns, and confirming workload continuity for every cluster.
This controlled strategy allowed us to move past the 250,000-IP ceiling and reach the operational range we needed. We managed all this without altering VPC boundaries or causing any downtime, a feat many thought unattainable under the existing architectural constraints.
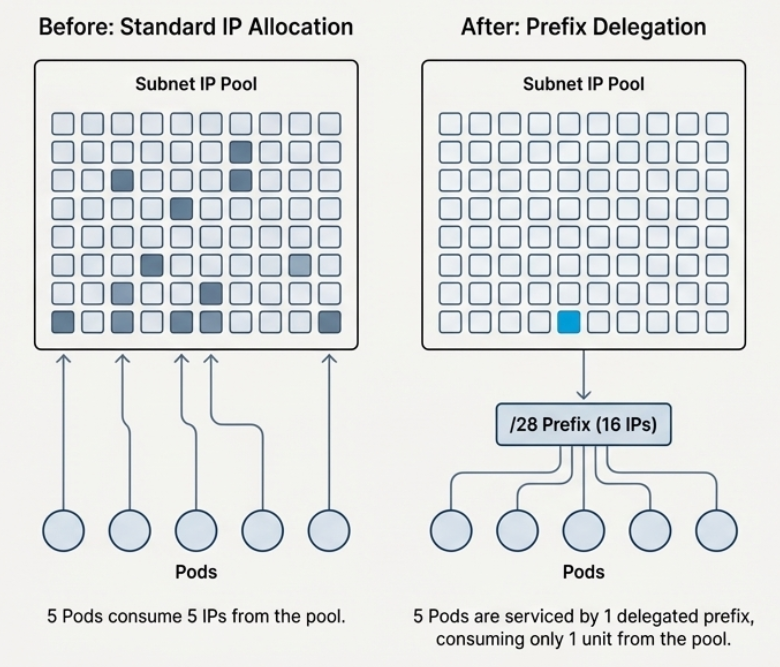
Using Prefix Delegation for 16x IP efficiency.
What observability and rollout validation challenges emerged when adopting AWS prefix delegation, and how did custom tooling and AI-driven validation ensure workload safety during migration?
Prefix delegation created new observability challenges. Neither AWS nor Hyperforce provided the necessary metrics for safe adoption. The gaps included:
- No visibility into fragmentation or the actual availability of contiguous 16-IP blocks.
- No delegation-aware metrics to distinguish usable space from unusable ranges.
- Only a single environment-level IP consumption graph, which was insufficient for validating a complex migration.
To address this, we built a custom observability model. This model mapped the full networking landscape—subnets, clusters, allocations, and fragmentation — in real time. AI tools accelerated the design and validation of this logic. They helped generate code and test functions, significantly reducing what would normally be weeks of development and validation into less than a day.
Armed with accurate visibility, we implemented a controlled, stepwise rollout. We migrated a cluster, validated fragmentation, confirmed workload behavior, and progressed incrementally. This approach ensured workload safety, protected tenant-facing latencies, and achieved a zero-downtime rollout while introducing a fundamentally new IP allocation model.
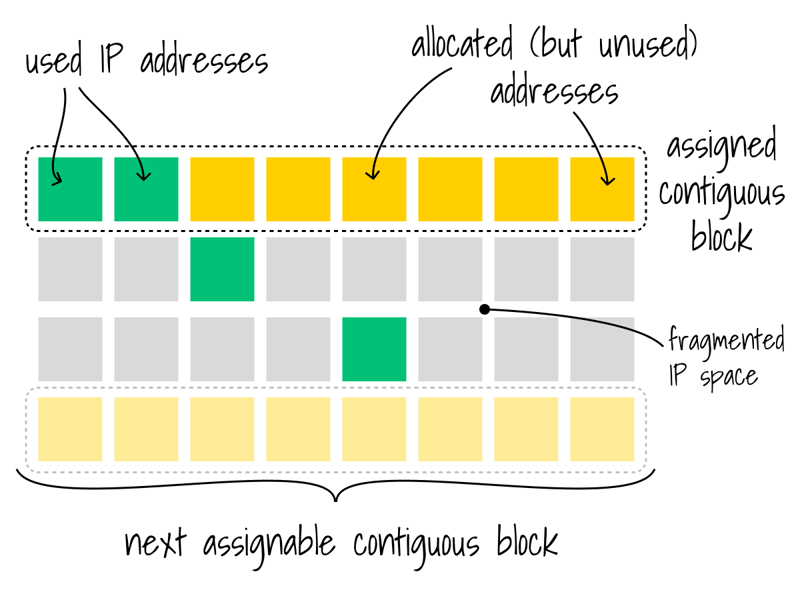
The challenge of enabling Prefix Delegation without fragmentation.
How did Hyperforce networking and SFSG boundaries influence your strategy for large-scale IP expansion?
Hyperforce imposed stringent rules on IP range allocation, sharing, and governance. These limitations directly influenced our solution and final strategy. We faced several key restrictions:
- SFSG Space Allocation: Each SFSG maintained a fixed IP capacity shared across teams, leaving Data 360 with minimal usable headroom.
- Immutable Subnet Design: Subnets, once created, resisted restructuring, removing traditional remediation options.
- No Multi-VPC Expansion: Hyperforce prohibited adding new VPCs or reshaping CIDR blocks for scaling purposes.
To overcome these constraints, we collaborated extensively with Hyperforce architecture, security, and public cloud platform teams. We designed a new, dedicated SFSG specifically for Data 360’s expansion requirements. This pattern, previously unused at this scale, enabled us to introduce additional IP capacity. It also remained fully compliant with Hyperforce’s routing and security primitives.
Combining prefix delegation with this dedicated SFSG established a scalable model for future growth. It also created a repeatable architectural pattern for other hyperscale workloads needing to extend beyond their default allocations.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.