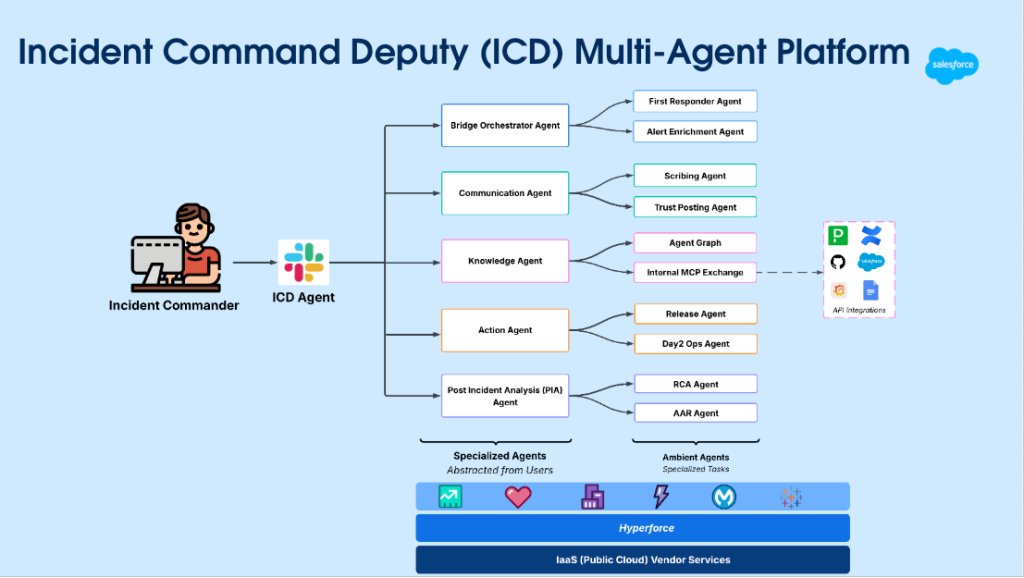
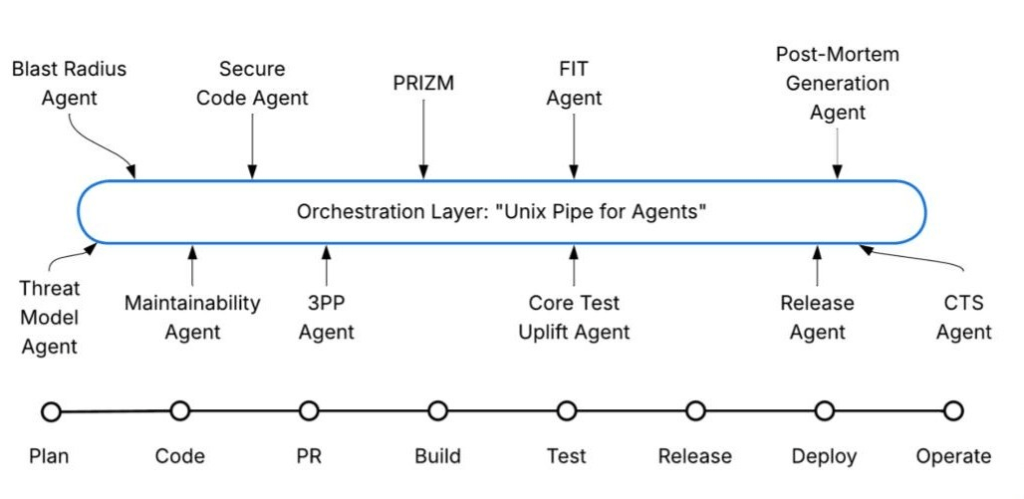
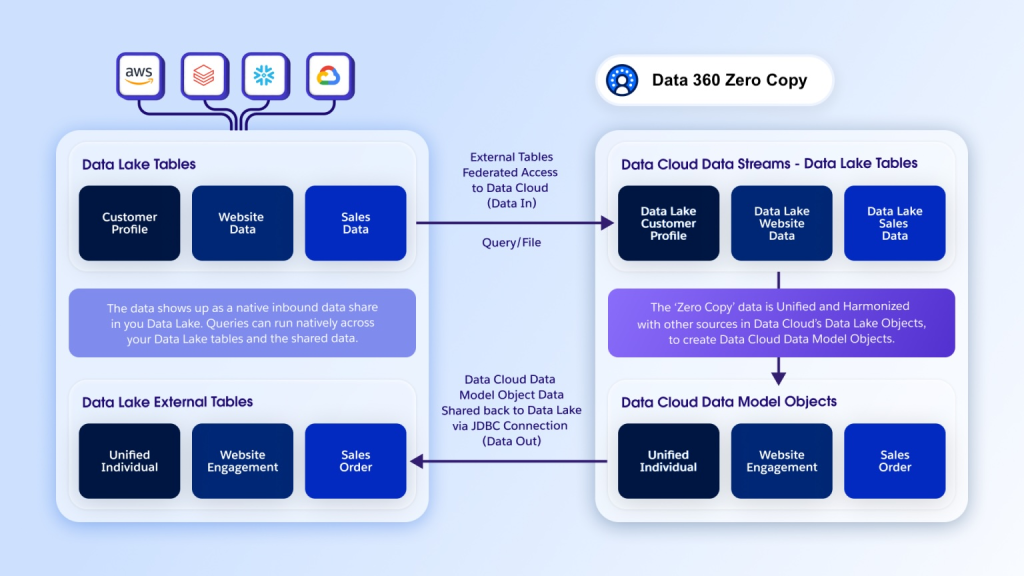
By Rakesh Nagaraju, Shweta Joshi, Guru Prasad, Renuka Prasad and Ashraya Raj Mathur.
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today we meet Shweta Joshi, Software Engineering Architect for the Engagement Agent, a generative-AI powered system automating personalized sales follow-ups and outreach across large lead volumes. Her team scales the architecture from a single-agent MVP into an enterprise-scale, horizontally scalable system supporting over 1 million monthly outreach actions across global sales and marketing operations.
Discover how the team re-architected the single-agent Engagement Agent into a dispatcher-orchestrated multi-agent system, evolving the platform as lead volumes grew dramatically with adoption and strengthening reliability by resolving retry storms, overload scenarios, and observability gaps.
What is your team’s mission supporting scalable and reliable AI-powered outreach workflows for large-volume sales and marketing operations?
We are evolving the foundational Engagement Agent MVP into a horizontally scalable, enterprise-ready platform. This delivers predictable, high-quality outreach across large and varied workloads. Organizations can automate personalized follow-ups and engagement sequences at scale, maintaining speed, accuracy, and compliance with provider and AI-level constraints.
As adoption increases, the architecture supports sustained throughput for significantly higher lead volumes. It will also remain fair, reliable, and responsive to time-sensitive engagements. This ensures customers transitioning from small pilots to global deployments experience consistent performance and linear scaling, with a platform capable of handling over 1 million monthly outreach actions across diverse sales and marketing environments.
To achieve this, the team is building the core execution framework necessary for safe, efficient operation at scale. Durable queuing, intelligent dispatching, quota enforcement, priority handling, and parallel execution across multiple Engagement Agents are essential components of this framework.
What architectural constraints shaped your shift from a single Engagement Agent MVP to a dispatcher-orchestrated multi-agent architecture with fairness, prioritization, and sustained throughput?
Our initial system, while a good starting point, showed some real limitations once it faced real-world demands. When a lot of work hit it all at once, directly assigning tasks caused bottlenecks, unpredictable delays, and interruptions. This meant urgent responses often had to jostle for attention with routine, larger tasks. Critically, resource-heavy workloads could monopolize our LLM gateway limits, leaving other essential processes in the lurch. Without any way to prioritize or ensure fair usage, the system’s performance could be inconsistent, potentially delaying crucial operations.
To tackle these issues, we introduced a persistent queue. Think of it as a smart waiting line that separates when tasks arrive from when they’re actually processed. This gives us a clear order for tasks and creates a natural buffer for those sudden surges in workload. Now, a dispatcher actively checks for high-priority tasks and spreads them across multiple Engagement Agents. This allows for parallel processing and helps us maintain a much more predictable flow of work.
We’ve also implemented some clever fairness algorithms, like Round-Robin, to ensure no single task or agent monopolizes resources. Before any task is sent off, our constraint engine verifies it adheres to all organizational and individual agent limits. The upshot? We now have a far more resilient and scalable system that keeps running smoothly, even when things get unexpectedly busy.
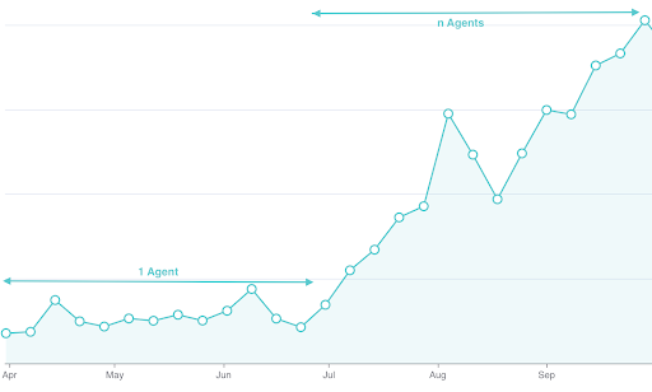
Scaling with a multi-agent, priority-aware architecture.
What scaling limits surfaced as outreach volumes grew toward million-record levels, and how did you evolve the system to overcome those boundaries?
Our system hit its limits as customer usage grew beyond the initial pilot stages. Email providers imposed strict caps, like Gmail’s approximately 2,000 messages daily and O365’s roughly 10,000. These created absolute ceilings, regardless of how much demand there was. This meant even large customer teams could not increase their output. Furthermore, the single Engagement Agent faced LLM rate-limit interruptions when processing batches larger than 40 leads. This restricted our throughput to about 15,000 leads per month, which fell short of enterprise expectations.
To overcome these constraints, the team adopted a phased “Crawl, Walk, Run, Fly” approach. During the Walk phase, we implemented channel-aware quotas. These quotas matched our sending behavior to each provider’s actual capacity. This significantly increased throughput for customers using high-capacity channels. In the Run phase, the persistent queue and dispatcher eliminated daily assignment ceilings and managed rate-limit variability. This allowed 20 agents to process up to 1.08 million messages monthly. Consequently, the Fly phase now investigates integrating Core MTA and Marketing Cloud. This will support marketing-scale workloads while preserving sender reputation and deliverability.
What reliability constraints emerged when workload spikes and single-agent overload caused unpredictable execution, and how did you redesign the platform for stable, burst-tolerant processing?
Our initial MVP design revealed significant reliability issues when faced with sudden increases in workload. Direct task assignment to a single agent meant that unexpected surges resulted in timeouts, processing issues, and a cascade of retry attempts. This created inconsistent throughput during peak periods, and routine tasks often delayed more urgent inbound responses. Without mechanisms to control or prioritize work, backlogs could grow indefinitely.
We addressed these limitations by implementing a dispatcher-mediated execution model. The persistent queue now absorbs workload bursts immediately, preventing system-wide failures. The dispatcher actively identifies and processes time-sensitive tasks by polling from priority buckets. Concurrently, the constraint engine confirms adherence to all AI and provider-level limits before any task is dispatched. This redesign, combined with multi-agent parallel execution, stabilizes throughput, safeguards urgent workflows, and maintains predictable performance, even during sharp and unexpected workload spikes.
What observability gaps made it difficult to see where high-value leads were getting stuck, and how did you build diagnostics for end-to-end visibility across the multi-agent workflow?
The initial MVP architecture offered limited visibility because task assignment and execution were confined within a single agent. This created processing inconsistencies that only manifested as timeouts or retries. Consequently, it became challenging to determine if interruptions originated from provider limits, AI rate pressure, or internal system delays. The problem worsened as instrumentation was fragmented across four distinct backend systems, preventing a unified view of the entire workflow.
We enhanced visibility by clearly separating intake and processing functions. The persistent queue and dispatcher established distinct diagnostic boundaries. This clarified the status of tasks, indicating whether they were waiting, running, or completed. We also developed a Trino-powered diagnostics pipeline, integrated with Cursor via the Trino MCP server. This enabled the correlation of telemetry across various systems, facilitated AI-assisted queries, and provided far greater accuracy in tracing behavior from input to execution. As a result, engineers can now identify root causes more rapidly and fine-tune performance more effectively across large-scale deployments.
What quota, prioritization, and fairness constraints shaped your design of channel-aware limits, priority tiers, and resource allocation across multiple agents?
Quota and fairness constraints significantly influenced the multi-agent design. Static, organization-wide caps artificially limited throughput, even on high-capacity channels. This meant organizations utilizing O365 could not achieve their full sending potential. Without a prioritization system, urgent inbound responses were delayed by less time-sensitive bulk tasks. Furthermore, in a multi-agent execution environment, shared-resource competition led to situations where certain agents consumed a disproportionate share of LLM gateway quotas.
We addressed these constraints with a layered design. Channel-aware quotas now align sending capacity with provider capabilities, allowing for significantly higher throughput where applicable. We implemented priority tiers (P0–P3) to ensure urgent tasks take precedence over routine operations. Fairness algorithms, such as Round-Robin and Least-Recently-Used, balance the workload across agents. The constraint engine enforces organization-level and per-agent guardrails before dispatch. This ensures equitable and predictable resource usage, even with highly variable real-world workloads.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.