By Shan Appajodu and Ravi Boyapati.
For years, software engineering viewed code review as a bounded, human-scalable activity. Pull requests grew gradually, and reviewers relied on local context. File-by-file diffs were enough to reason about changes.
This model fractured when AI-assisted coding tools altered the economics of code creation faster than review workflows could adapt. At Salesforce, internal signals made this shift impossible to ignore. Code volume increased by approximately 30% and pull requests regularly expanded beyond 20 files and 1,000 lines of change. Review latency rose quarter over quarter. More concerning, review time for the largest pull requests began to plateau — or even decline. This indicated that reviewers were no longer meaningfully engaging with changes. The sustainable maintenance of our core values — trust, safety, and technical rigor — was becoming increasingly difficult to guarantee at scale.
Can’t we just use AI to review the code? While it might be tempting to see that as an easy answer, it alone is not sufficient.
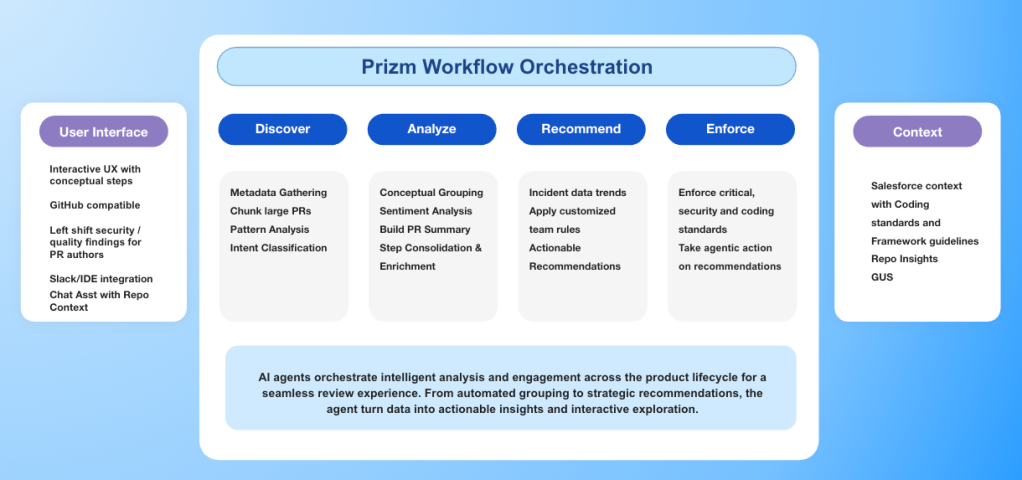
Explore how Salesforce Engineering responded by re-architecting code review as a system, internally implemented as Prizm. While Prizm left shifts code reviews by providing feedback in the flow of work within the IDE and PR itself with suggestions to fix the issues, it also solves for much beyond just AI-based review. Ultimately, it is designed to preserve developer intent, maintain a secure chain of trust, and scale human judgment under AI-amplified load.
When Review Stops Scaling, Trust Breaks First
The warning signs were clear. AI-assisted development reduced time-to-code and accelerated work item closure. However, pull request cycle times moved in the opposite direction. Senior reviewers daily context-switched across multiple large, AI-assisted changesets. This increased cognitive overhead and reduced effective analysis.
Large pull requests have always carried risk. Even before AI, oversized changes often resulted in superficial review. AI intensified this pattern by generating more code per task across unrelated files and architectural layers. Reviewers navigated linear diffs that obscured the conceptual structure of change.
The deeper issue was not isolated code quality. It was the erosion of Salesforce’s second-pair-of-eyes guarantee. When review capacity cannot keep pace with submission volume, the human-in-the-loop model degrades. Vulnerabilities and architectural regressions slip through, not because of negligence, but because the workflow no longer supports effective reasoning.
Why the File-by-File Review Model Failed Under AI Load
Traditional pull request review assumes reviewers can reconstruct intent by scanning diffs sequentially. This assumption holds when changes are small and incremental. However, under AI-generated load, it breaks down in predictable ways:
- Loss of conceptual coherence: AI-generated pull requests often span backend logic, configuration, tests, and user-facing components. They do not preserve the narrative structure. Reviewers must infer purpose from disconnected fragments, increasing the likelihood of missing critical interactions.
- Non-linear growth in cognitive load: As pull request size increases, reviewers spend more time navigating files than reasoning about behavior. Context switching replaces evaluation, making review mechanical rather than analytical.
- Inversion of review incentives: When the effort for thorough review exceeds perceived value, reviewers default to surface-level validation or approval without full comprehension. This represents a systems failure, not an individual one. The workflow no longer upholds its design guarantees.
- Absence of proactive risk augmentation: In a manual-only model, the reviewer is the sole filter for both trivial syntax and complex architectural flaws. Without AI-assisted feedback to proactively surface potential pitfalls or suggest areas for improvement, reviewers lack the “second set of eyes” needed to navigate high-volume changes. This leaves the human element unaugmented, making it harder to maintain deep rigor as the scale of contributions increases.
These failure modes made it clear that increasing review throughput alone would not suffice. The review model itself required a fundamental change.
Reconstructing Intent Instead of Reviewing Diffs
The core challenge was enabling a system to understand what developers were trying to accomplish, not just what lines changed. Developers author code with a conceptual model, such as refactoring authentication or introducing a new API. Traditional tooling discards that structure, presenting reviewers with isolated diffs detached from purpose. As pull request size grows, reviewers must reverse-engineer intent from noise.
The redesigned review system centers on intent reconstruction through iterative reasoning. Instead of treating diffs as flat text, it preserves structural boundaries — files, functions, and modules — during analysis. Token-aware chunking ensures logical units remain intact, preventing semantic fragmentation.
Higher-order abstractions are built progressively. Broad conceptual groupings are identified first, then refined through semantic consolidation. A graph-based merge phase analyzes dependencies, file overlap, and conceptual similarity. This allows related changes, such as backend logic and corresponding user interface updates, to be reviewed together even when they span disparate areas of the codebase. This approach restores alignment between how code is written and how it is reviewed.
Context as a First-Class System Dependency
Intent alone is insufficient without context. Diffs cannot convey historical decisions, acceptance criteria, or architectural conventions. The re-architected review system assumes meaningful evaluation requires unified context. This context is drawn from work items, previous pull requests, historical defects, and codebase patterns. Aggregating this information required ingesting structured and unstructured data, reasoning over it semantically, and surfacing only what was relevant to evaluation.
This capability emerged from broader context-engineering efforts. These efforts treat context as a shared substrate across the development lifecycle. Planning informs coding, coding informs review, and review is enriched by signals from prior phases. By the time the new review system was built, much of this infrastructure existed. The remaining work focused on filtering and shaping context for review-specific use cases.
The result is progressive disclosure. Reviewers receive context incrementally. This highlights architectural decisions, security-sensitive changes, and elevated risk areas, allowing attention to be spent where it matters most.
Preserving the Chain of Trust at Scale
At scale, the primary risk of AI-generated code is not uniformly poor quality, but diminished scrutiny. The new review architecture reinforces human judgment. It assumes roles typically held by senior reviewers. The system applies Salesforce-specific domain rules, references historical defects, and evaluates changes through security, quality, and architectural lenses.
Potential vulnerabilities are surfaced with precise file- and line-level references, accompanied by remediation guidance. Design risks are presented alongside assessments of change severity. The system integrates directly with existing GitHub workflows. Comments and approvals remain bidirectional, preserving established processes. Transparency is maintained through reasoning traces that explain why issues were flagged. This allows reviewers to validate conclusions rather than accept them blindly.
Early adoption by teams in Salesforce demonstrated that semantic review can scale when embedded directly into developer workflows. Summaries and conceptual groupings appear in pull request descriptions, while actionable recommendations surface as inline comments. This reduces friction without sacrificing rigor.
Designing for Scale Without Blocking Developers
Deep semantic analysis is computationally expensive. For large pull requests, full analysis, which includes grouping, recommendations, and security checks, can take up to five minutes. Performing this work synchronously would be unacceptable.
The system executes analysis asynchronously when a pull request is created. Results are persisted and served instantly. This allows thousands of developers to access insights without added latency. This architectural decision was foundational to scaling review across Salesforce’s engineering organization.
The same validation capabilities can extend beyond pull requests, supporting earlier feedback during development or later enforcement during release processes.
Left Shift Feedback
As we scale, Prizm takes a two-pronged approach. First, we shift feedback left by delivering AI-driven insights directly within the IDE and the pull request. This allows developers to catch issues early in the development cycle while providing a rich, context-aware experience for peer reviewers.
Prizm also monitors production for defects and incidents, identifying patterns that should have been caught earlier to continuously reinforce our training — making every subsequent review smarter than the last
A Retrospective on Review in the AI Era
This re-architecture represents a retrospective response to a structural shift in software development. AI changed the cost of producing code, which invalidated long-standing assumptions about review capacity and human cognition. The response was not to automate judgment. Instead, it was to rebuild review as a system aligned with how developers actually reason about change.
By reconstructing intent, unifying context, and scaling review without removing humans from the loop, this approach restores the guarantees code review was always meant to provide. In an environment where code is abundant and attention is scarce, review must evolve beyond diff inspection. It must become a first-class engineering system, one capable of maintaining trust under AI-driven scale.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.