In our “Engineering Energizers” Q&A series, we dive into the inspiring stories of engineering leaders who are pushing the boundaries of innovation and solving intricate technical challenges. Today, we shine a spotlight on Rama Raman, Director of Software Engineering at Salesforce, whose team is transforming scalable AI development by automating key processes in the machine learning lifecycle.
Explore how Rama’s team tackles the challenges of scaling AI services, ensuring seamless metadata consistency across systems, and maintaining robust data integrity in model storage.
What is your team’s mission?
Our team’s mission is to empower scalable AI development by creating automated systems for the training and deployment of both predictive and generative machine learning models. With thousands of models deployed across Salesforce organizations, our primary goal is to eliminate inefficiencies in the AI lifecycle, allowing teams to focus on innovation rather than infrastructure management. To achieve this, we build tools and services that streamline critical processes:
- Metadata Management: This ensures that model metadata like model name, model provider and credential information remain consistent, reducing latency and improving reliability.
- Version Control & Deployment: Through the ML Versioning Service (MVS), we provide lifecycle management of AI applications. This powers seamless application onboarding and roll out of updates, which is essential for maintaining the integrity of large-scale AI systems.
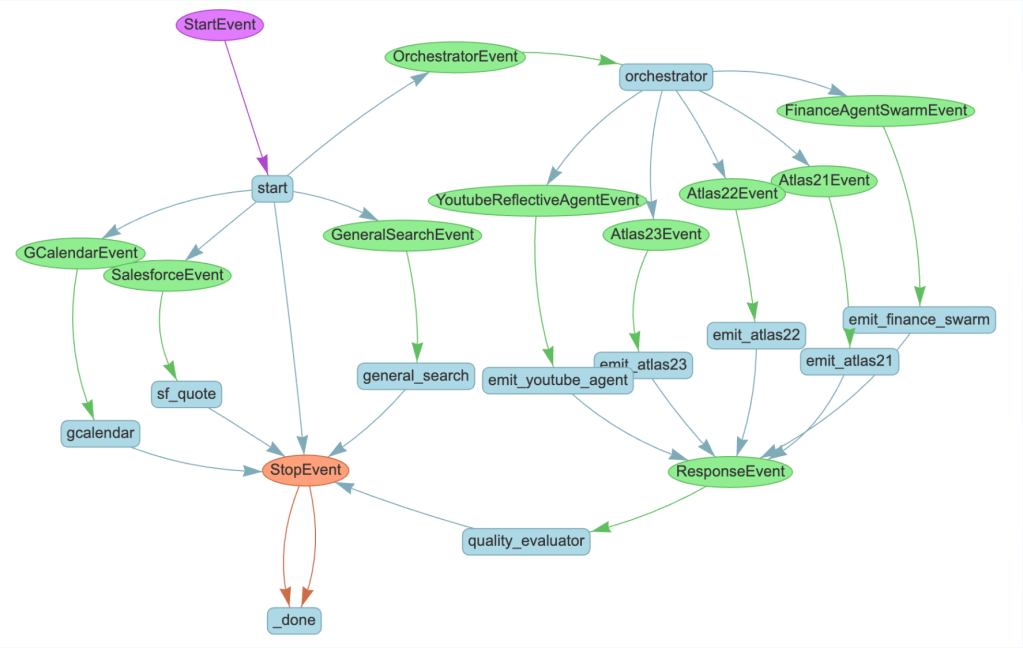
- Orchestration Engine: This workflow engine enables definition and execution of ML training flows and complex tasks such as data preparation, model training, and model deployment — ensuring smooth integration and reducing the manual effort required.
- Model Store: A repository responsible for ML model storage and lifecycles and serves as the bridge between training and inference.
By addressing these key issues, we provide a robust foundation for AI-driven solutions that can scale to meet the diverse needs of organizations.
Rama discusses the culture within Salesforce Engineering.
How has your team addressed the challenge of scaling services like MVS and Orchestration to handle high traffic volumes and database-heavy operations?
Scaling services such as the MVS and Orchestration becomes increasingly challenging as the demand for training rises with the expansion of predictive and generative use cases. MVS, responsible for handling application version roll outs, encountered database bottlenecks when deploying large customer loads. To address this, we introduced staggered deployment strategies, tuned our database, and optimized the queries — drastically reducing database delays while ensuring consistent performance even under peak traffic conditions. These changes allowed us to reduce deployment time for workloads as large as 140,000 customers from several days to just a few hours.
For Orchestration, ensuring the concurrent execution of workflows across thousands of nodes is a key priority to prevent execution delays. We designed the service to minimize resource consumption during and between flow stages by delegating tasks to dedicated services, such as the compute gateway, which handles the execution of training workloads. Extensive scalability testing allowed us to anticipate capacity needs, enabling proactive performance optimization. One of the system’s key accomplishments was its ability to manage up to 10,000 training workflows per minute with an SLA of 500 milliseconds. This high throughput achieved through parallel task execution and optimized resource management, ensures smooth operations even during peak demand.
These solutions have allowed us to process up to 1.5 million flows weekly while maintaining high reliability.

Flow execution count per week.
How do you ensure consistent metadata alignment across producers, consumers, and various scenarios to optimize latency for inferencing?
In all Agentforce flows, a Generative AI model is invoked. To provide the metadata required for these models at runtime with low latency and high resiliency, we rely on the AI Metadata Service (AIMS). Serving as the metadata source, AIMS ensures that application-related metadata and model related information is readily available with high throughput and low latency for both training and inference systems.
The service allows customers to define and manage the metadata required for their applications, providing dedicated APIs for their operations. To minimize latency for real-time inference requests, we implemented caching mechanisms that store frequently accessed data, drastically reducing access times. Additionally, we developed schema validation tools that automatically ensure metadata consistency before it is consumed by inference systems like Agentforce. With these changes, we are able to handle sustained peak query load of 90,000 queries per minute.
By combining robust tools with real-time synchronization across services, we maintain metadata alignment and support smooth model invocation across a variety of scenarios. This approach ensures that all stakeholders, from data scientists to operations teams, have access to the most accurate and consistent metadata, optimizing model performance and streamlining the deployment process.
What measures does your team take to ensure data integrity and maintain trust in services, particularly in model storage?
Maintaining data integrity and trust is critical for our operations, especially in the model store, which serves as the bridge between training and inference. To ensure this, we have implemented several stringent policies and security measures.
First, we enforce policies to prevent sensitive data, such as personally identifiable information (PII), from being included in stored models. Additionally, we adhere to strict data deletion policies to ensure GDPR compliance. These measures help us meet privacy regulations and minimize security risks.
To enhance security further, we employ multi-layered protection mechanisms. Role-based access controls (RBAC) restrict unauthorized access, ensuring that only authorized systems can access a specific customer’s data. Encryption is used to safeguard sensitive metadata, protecting it from unauthorized viewing or tampering.
Regular audits and penetration tests are conducted to reinforce these safeguards. These tests help us identify and address any vulnerabilities, ensuring that our systems remain reliable and secure for all users. Through these comprehensive measures, we maintain high standards of data integrity and trust in our services.

AI training platform microservice architecture.
How does your team ensure rapid deployment of customer changes while maintaining system reliability and avoiding bottlenecks?
Rapid deployment requires a careful balance between speed and reliability, especially in a distributed environment. MVS plays a pivotal role by providing seamless version tracking and ensuring updates can be deployed efficiently across thousands of organizations. Each update undergoes rigorous testing in sandbox environments to identify and resolve potential issues before they go live.
The Orchestration service complements this process by automating workflows and managing dependencies between tasks. For example, we have incorporated concurrency where customer flows are executed in parallel, which minimizes delays and speeds up the overall process. To further enhance reliability, we dynamically scale our infrastructure based on workload demands. During peak update windows, additional compute resources are allocated elastically to ensure smooth operations and prevent bottlenecks.
By combining these strategies, we maintain a robust deployment process that supports frequent updates without compromising system stability. This approach ensures that our services remain reliable and efficient, even as we rapidly deploy new features and improvements.
Rama clarifies a common misconception about working at Salesforce Engineering.
What strategies do you use to manage dependencies across services and prevent regressions when making updates?
Managing dependencies effectively requires clear communication and robust technical safeguards. We design each service with a modular architecture and well-defined interfaces, allowing them to operate independently while maintaining compatibility with interconnected systems.
We actively monitor our operational status using dashboards and metrics that trigger alerts whenever system performance deviates from optimal levels. This proactive approach enables us to consistently meet our service level agreements (SLAs).
Shared validation tests are a critical part of our strategy. These tests ensure that updates to one service do not introduce issues in others. Regression testing is another cornerstone of our approach. We run comprehensive test suites that simulate real-world interactions between services, such as AIMS metadata access, the orchestration workflows and the model store. These tests help us identify and address potential conflicts early in the development process, ensuring that updates do not break existing functionality.
Cross-team collaboration is equally vital. Regular meetings and clear communication channels foster alignment and a shared understanding of updates. This collaboration ensures that all teams are aware of changes and can work together to prevent and resolve any issues that may arise.
By combining rigorous testing with proactive communication, we minimize the risk of regressions and ensure the reliability of our services. This approach allows us to make updates confidently and efficiently, maintaining the integrity and performance of our interconnected systems.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.