In our “Engineering Energizers” Q&A series, we explore the paths of engineering leaders who have attained significant accomplishments in their respective fields. Today, we spotlight Claire Cheng, Vice President of Data Science & Engineering and leader of the Einstein Foundation team at Salesforce. Claire’s team enhances customer service with the Retrieval Augmented Generation (RAG) system integrated within Data Cloud, transforming unstructured text into searchable formats for efficient information retrieval and generation.
Explore the technical hurdles that Claire’s team encountered and the continuous improvements they are implementing based on user feedback.
What is your team’s mission?
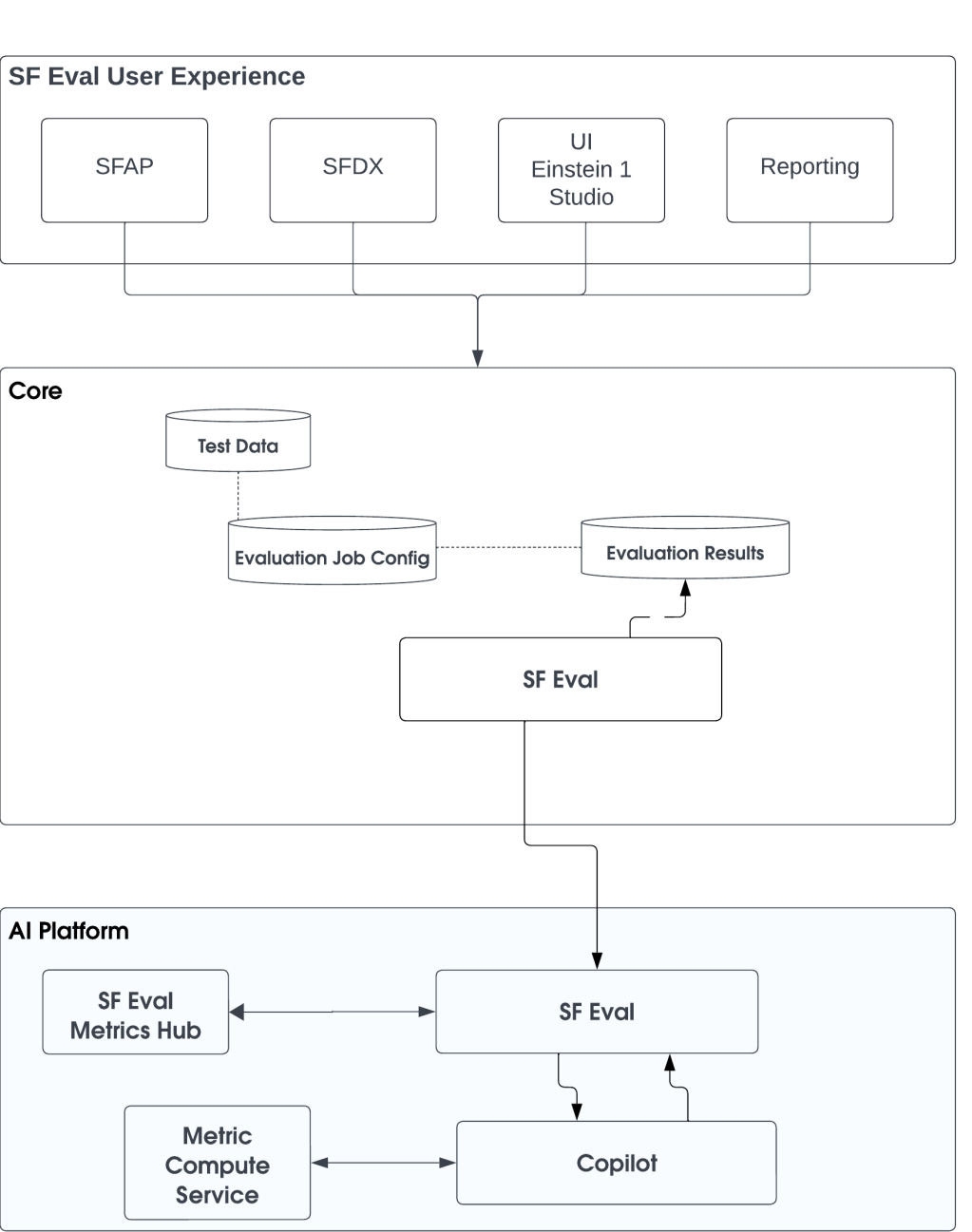
The team is dedicated to developing generative AI foundational capabilities that enhance Salesforce’s industry-leading AI CRM through AI modeling and services, cloud-based generative AI applications, and copilots. A key focus of our efforts is to improve customer experiences by integrating RAG with Data Cloud. This integration transforms unstructured text into searchable insights, leveraging Data Cloud’s robust framework for data ingestion, transformation, and indexing.
By processing raw data into actionable knowledge and information, RAG enables swift and efficient retrieval of relevant information during customer interactions. This not only enhances the customer experience but also bolsters the generative AI’s ability to provide more relevant and accurate responses by incorporating additional grounding context. The team is committed to continuously refining this integration and developing further enhancements to create a more comprehensive, scalable, and measurable modular RAG system.
Can you share an example of how RAG works in practice?
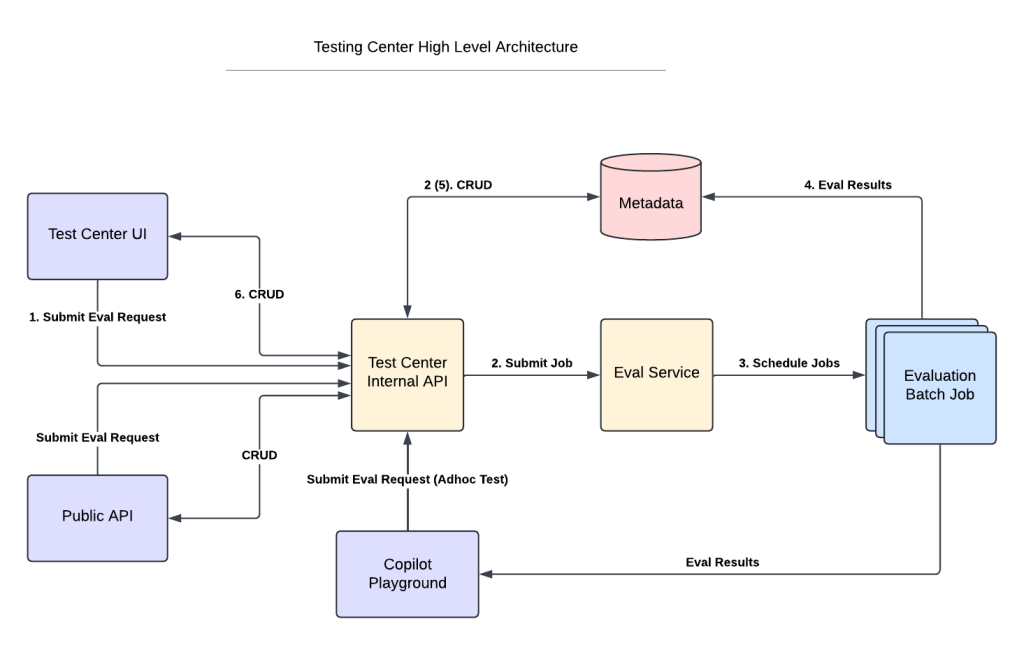
For example, if a retail customer asks about a return policy, RAG can automatically formulate one or multiple precise queries based on user’s question and the context, retrieve relevant knowledge from Data Cloud, ensemble and compress retrieved contents, and instruct the large language model (LLM) to generate a coherent response. This accelerates response times while ensuring accuracy and relevance.
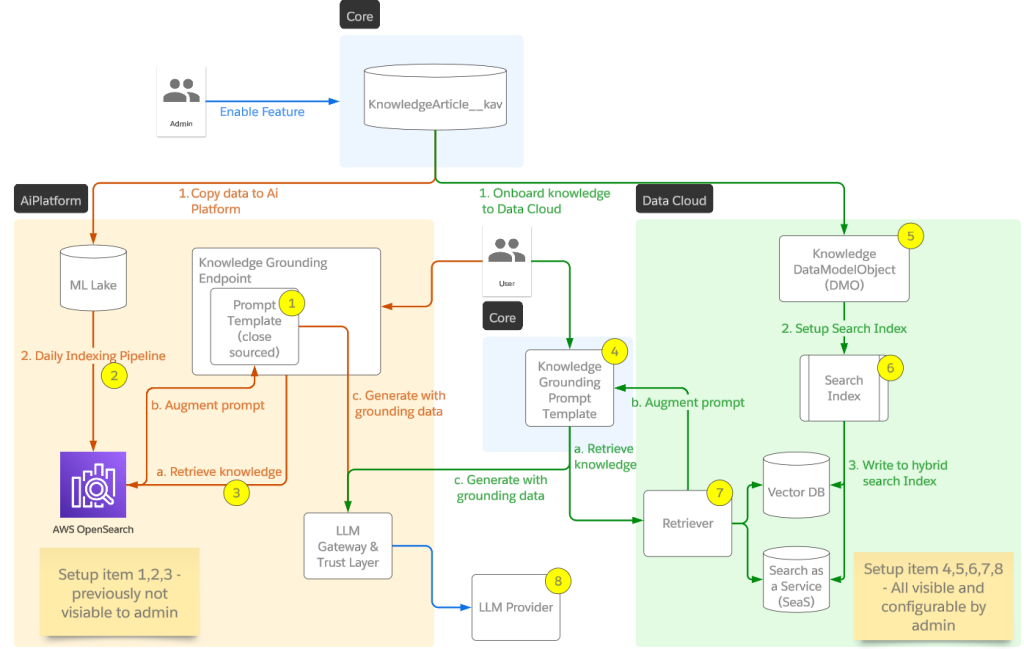
RAG’s integration into Data Cloud has introduced greater customization opportunities for information retrieval, allowing users to tailor how data is ingested, transformed, and utilized. Additionally, retrievers are exposed natively in Prompt Builder, enabling users to configure the query objects and requirements within the prompt engineering process. This transforms RAG from a closed system into a transparent and configurable feature within Salesforce’s ecosystem.
RAG on Data Cloud enhanced quality and customizability at scale.
What were the main challenges your team encountered while integrating and customizing RAG for use with Data Cloud?
Integrating and customizing RAG for use with Data Cloud involved several significant challenges, primarily centered around adapting the system for enhanced data compatibility and improving AI processing capabilities. Initially, the transition required us to transform RAG from a closed system built for Service GPT to a more open and configurable system in Data Cloud. This adaptation was crucial to handle a broader range of input data sources and to give users more control over data processing.
To achieve this, we enhanced our data ingestion and transformation processes, which not only provided greater flexibility but also ensured that RAG could effectively communicate with Data Cloud’s infrastructure. We also developed new adapters to translate Data Cloud’s data formats into forms usable by our AI models, addressing compatibility issues.
Furthermore, we focused on bringing more AI to the steps of data understanding and preprocessing across diverse data types and structures in Data Cloud. These enhancements in preprocessing (such as chunk optimization, augmented indexing, etc.) were essential to maintain the system’s performance and accuracy, ensuring that RAG could still retrieve relevant and accurate information under the new framework. These adaptations were key to successfully integrating RAG with Data Cloud, allowing the system to operate efficiently in its new environment.
During the customization of RAG with Data Cloud, were there any unexpected issues?
During the customization of RAG for Data Cloud, one unexpected issue that arose was the scale of data processing. Data Cloud handles a vast amount of data, and optimizing RAG to process this efficiently without sacrificing performance was a significant challenge. To address this, we employed a strategy of extensive testing and iterative improvements. Our team undertook a significant redesign of the data processing pipeline, enabling inline AI model inference, and tweaked the AI algorithms to better handle large volumes of data.
With the iterative approach, we were able to gradually find the optimal balance between performance and accuracy, ensuring that RAG could effectively function within the robust framework of Data Cloud.
Can you discuss any user feedback or operational challenges that emerged after deploying RAG with Data Cloud?
Following the deployment of RAG on Data Cloud, we embraced the opportunity to refine the system based on user feedback. Users expressed appreciation for the enhanced transparency and control provided by the Data Cloud integration but also highlighted the need for a more user-friendly configuration process. This feedback was invaluable as it drove our commitment to making the system accessible to all users, regardless of their expertise in data or AI.
In response, our team dedicated efforts to enhance the user experience by developing more intuitive interfaces and improving the documentation. These enhancements aimed to simplify the onboarding process and enable users to leverage the full capabilities of RAG more effectively. We were excited about these ongoing improvements and remained committed to continuously evolving the system to meet the needs of our users.
Additionally, we are exploring the development of automated tools that can assist users in setting up, testing, and managing their RAG configurations and monitoring RAG performance more easily. This initiative is part of our ongoing effort to make RAG not only a powerful tool but also accessible and user-friendly for a broader range of users.
Learn More
- Hungry for more Data Cloud stories? Read this blog to learn Data Cloud’s secret formula for processing one quadrillion records monthly.
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.