

Salesforce and its customers continue to generate and store more and more data, and the growth looks exponential or cubic rather than linear. Keeping ahead of that curve is the responsibility of many of our infrastructure teams, including several clever folks in our Storage Cloud.
The Storage Cloud is building on Kubernetes (for automated deployment, management, and scaling of our containerized applications) with local persistent storage to enable our high-performance workloads. This lets us scale out storage software services, both in our first party data centers and across other substrates, to keep pace with demand.
In this post, we describe the local persistent volume (local PV) lifecycle in our data centers. We talk about how we prepare our bare-metal servers, provision local PVs, and expose multiple storage types to stateful service owners.
We have a variety of options when it comes to bare-metal server hardware, provisioning software, and system-level configuration management. Instead of customizing these systems for a particular use case, we delay all local storage node preparation until after the hosts are up and connected to their Kubernetes control plane. Leveraging all that existing work and delaying Kubernetes local storage related tasks enables us to properly prepare the nodes and the local disks that we intend to expose using Kubernetes.
Good Daemons, Very Good Daemons
How do we do this? We deploy multiple daemonsets that are responsible for preparing the local disks and local PVs. A daemonset is a collection of Kubernetes pods (pod), one for each node in the cluster. This node preparation daemonset runs on each new node as it is added to the Kubernetes control plane. After completing preparation the local storage discovery daemonset finds the node, ultimately enabling local PVs to be provisioned.
Node Preparation by Magic
Quite a lot happens during node preparation. First, we evaluate the server and its function. Depending on the situation we might partition, repartition, clean, populate, mount, and unmount the local disks, partitions, and file systems. We also determine which local volumes should be exposed and the class of service (perhaps low latency) for each of these volumes. For example, we may choose to expose all the disks or only a few of the partitions. Similarly, we may choose which type of disks to expose (for example, solid state or hard disk). Local storage that belongs to the same class are organized under the same directories on a given node.
The node preparation pods automatically identify unprepared nodes — based on the labels on the node — and deploy on those nodes. More specifically, the node preparation pods specify the following affinity to labels:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: storage.salesforce.com/nodeprep
operator: DoesNotExist
What does this spec determine? The pods only run on nodes that don’t have the nodeprep label. Once the preparation is completed successfully, the node is labelled with the “nodeprep” label. This label causes the node preparation pod to exit the node, and the same label causes the local volume provisioner process to deploy on the nodes. The local PV provisioner discovers the volumes that the node preparation made available, and creates PV representations for them in Kubernetes. The local PV provisioner has the following node affinity to enable this reaction:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: storage.salesforce.com/nodeprep
operator: In
values:
- mounted
The daemonset scheduling capabilities of Kubernetes and the use of labels enable these elegant handoffs between processes running in phases on entire farms of nodes. Each step is automated, and governed by the state of each node as indicated by labels, or lack thereof, and node affinity constraints. We make use of, and actively contribute to, the open-source local PV provisioner that is part of the kubernetes-incubator/external-storage repository.
Magic Happens When the Cluster expands
As our clusters grows, we add new servers and now the real magic happens.
A new node is automatically detected by the nodeprep daemonset and a nodeprep pod is almost immediately deployed on that node. The node is prepared in a matter of seconds and labeled. It gets handed off to the local PV provisioner daemonset which makes the node’s storage resources available as PVs, as described above.
Pop Quiz
So, let’s talk some more about provisioning. In fact, let’s have a little pop quiz. Can you guess what the local PV provisioner does next?
- It places these PVs into the appropriate storageClasses.
- It gives them annotations that identify the node on which the related PV resides. (These objects are the representation of these disks within Kubernetes.)
Ok, yes this is a silly quiz. The answer is both. The result though is that the PVs can now be claimed by pods, via persistent volume claims (PVCs). In other words, the local storage (PV) is ready to be claimed by stateful services.
So, for example, an object storage system might want one of its pods to claim two 1-terabyte volumes on hard disks and one 500-gigabyte volume on a solid-state disk. The local storage feature in Kubernetes takes over and handles scheduling, by StorageClass for the different underlying disk types. Once this pod has been scheduled, it ensures that the local PVs are exposed to the container.
Safety in Numbers… er, Node Affinity
Any workload depending on a local PV will always be rescheduled to the same node, so that the same physical disks associated with its local PVs are available to it. We leverage the Kubernetes local persistent storage feature to run multiple distributed storage services in clusters.
The local PV provisioner also monitors the status of the PV once they are claimed. When Kubernetes releases these PVs, the provisioner takes on the task of wiping the volume, removing information that might have been left behind (think compliance!). Once the data has been removed, a new PV is again made available by the provisioner for consumption.
The full sequence looks like this:
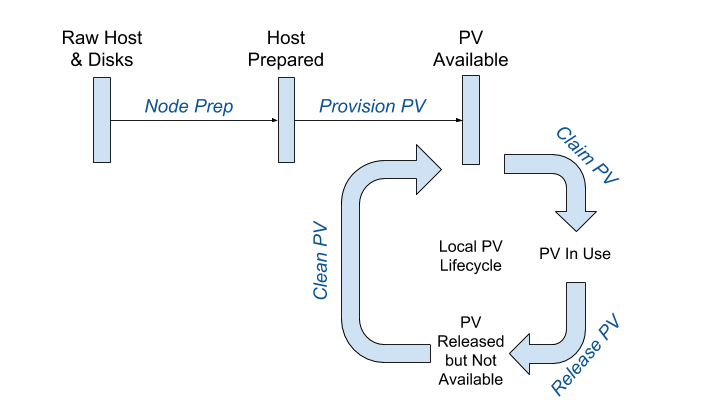
Blockage Ahead
The local PVs currently supported are file system-based volumes. In upcoming releases of Kubernetes, local volumes exposed as block devices will also be supported. This significant enhancement to local volumes will enable applications to require raw device access to volumes without the inefficiency of a file system layer.
This blog post was written by Ian Chakeres & Dhiraj Hegde, two of the primary contributors to the Kubernetes local storage feature at Salesforce. Edited by Peter Heald and James Ward.


