

At Salesforce we manage tons of data. Sometimes we need to migrate that data to different stores or transform it for different uses. In this post data engineers from the SalesforceIQ team will share their top four tips for massive data migration (billions of data records), based on lessons they’ve learned. Before we dive in, let’s meet the guides on our journey:
- Dengfeng Li is a Member of Technical Staff at Salesforce, specializing in Java/Scala and big data processing frameworks
- Zhidong Ke is a Senior Member of Technical Staff at Salesforce, specializing in distributed system and data processing in large scale
- Jeff David Lowe is a Senior Member of Technical Staff at Salesforce, specializing in big data processing and distributed systems with a passion for deep learning
- Kevin Terusaki is a Member of Technical Staff, who enjoys the technical challenges of big data processing
- Praveen Innamuri is a Senior Engineering Manager at Salesforce, specializing in building data platform, and distributed data processing apps.
On the SalesforceIQ team we utilize numerous datastores (e.g., Cassandra, Object Datastores, and NoSQL databases) which are used for a variety of analytics, Machine Learning, and of-course to persist our customer data. Each year, over billions of events are ingested and stored into our backend data stores. Sometimes new features or infrastructure changes require us to migrate massive amounts of data to different formats or storage systems.
As an example, at one point we stored activity data as a flat structure to avoid duplication when an activity involved across multiple customers. See Figure 2(a) below. However, we found it difficult to implement data retention policies and General Data Protection Regulation (GDPR) when storing data in a flat structure. For example, when we need to delete all activities for a specific customer in a particular month, we need to collect metadata, update the references from other databases, and then delete the activities only when no customer references it. But if we store customers’ activities in a hierarchical structure as shown in Figure2(b), we can more easily and efficiently find the activities to delete.
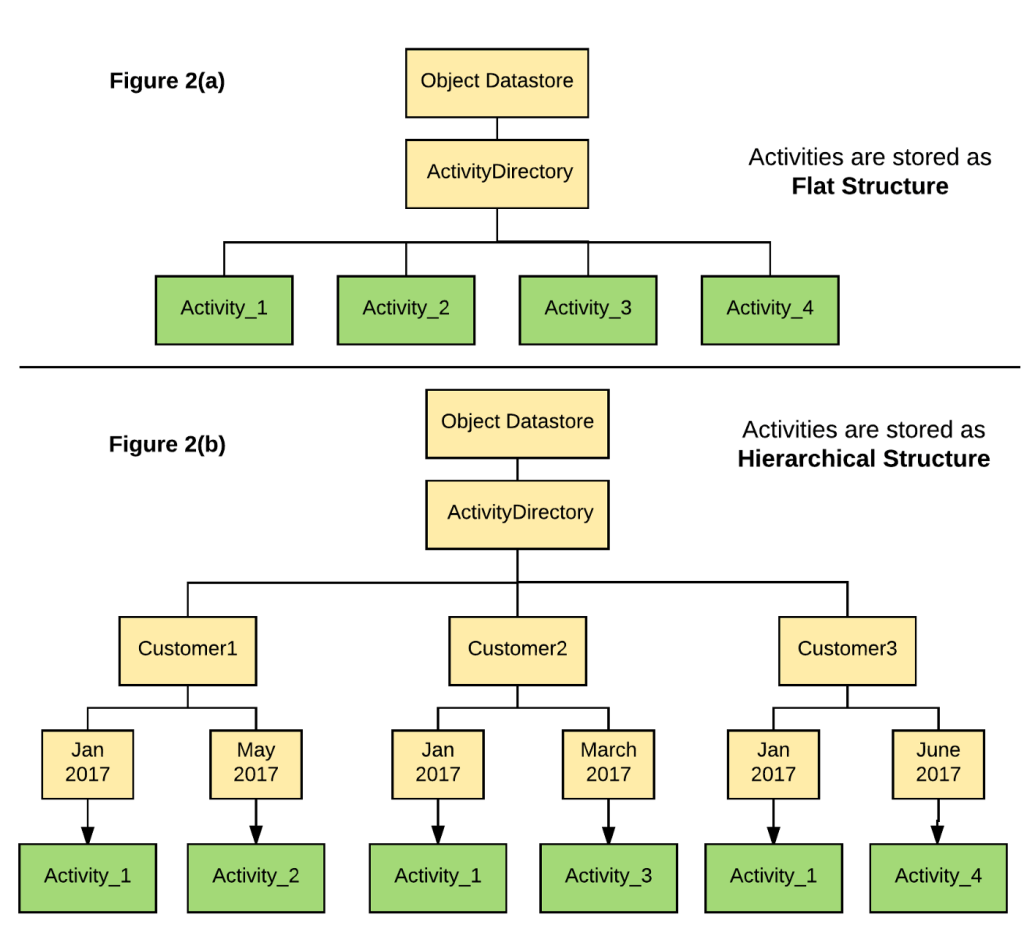
This example activity data structure change highlights the need for a safe and efficient way to migrate a massive amount of data. As we tackled this migration we learned that there are four key things you should consider when doing your own massive data migrations:
- Understand Your Data
- Estimate The Performance Impact
- Design Metadata and Validation
- Optimize Migration Jobs
Let’s dive into each of those.
1. Understand Your Data
To estimate needed resources (e.g. computation and labor) and a timeline for the migration, it is important to gain a comprehensive knowledge of the data you need to migrate.
What is the data volume?
Knowing the data volume will help you choose the right migration strategy. For example, if the migration data is less than several gigabytes (e.g. a small table in Cassandra), you may be able to keep things simple and submit a job that reads data sequentially. However, if the migration data is in the terabytes or petabytes, you’ll need to divide the migration job into small migration tasks that can run in parallel.
For our activity migration job, we divided it into small migration tasks at the customer level such that each migration task only migrates one month data of a single customer. We run our migration tasks using Apache Spark framework with hundreds of executors in parallel, which greatly reduces our migration time down to only several days.
Where is the data stored?
For a data migration job, it may need to retrieve data from different storage systems for data transformation purposes. Understanding what underlying systems will be involved and actively interacting with developers who have expertise in those systems will help to avoid pitfalls and improve performance.
How is the data stored?
If a data transformation is required in the data migration job, make sure you understand the schema and semantics of the data before writing any transformation functions. For example, if a migration reads a timestamp represented as a numeric value and compares it with another timestamp, you need to know what timezone is used and what granularity the numeric value is representing (e.g. millisecond, second, etc).
In our case the data is encrypted and can be only accessed by designated machines. If you have these constraints you will need to work with your security team to make sure your migration job can access/decrypt the data.
2. Estimate The Performance Impact
To maintain a healthy backend infrastructure, it is important to know how a migration job may impact production services. You should coordinate with your DevOps team because the migration will likely add significant load on the datastores. In our migration job, we have encountered a few challenges:
- Our cloud-based Object Datastore generally limits the request rate for PUT/LIST/DELETE operations. We worked with our DevOps team to allow for a temporary increase to this limit.
- Since our migration job sends billions more queries than normal to our Cassandra database, we needed to insure we didn’t impact the production performance. By adding caching to our migration job we were able to reduce the queries to a manageable level. Another option would be to schedule the migration jobs during off-peak hours.
3. Design Metadata and Validation
To ensure the integrity of customers’ data, we cannot tolerate any data loss through the migration progress and it is important to have a well-designed validation plan. To help us conduct validation, we first need to keep track of data that has been successfully migrated and data that encountered errors during the migration. However, simply logging migration information as plain text and validating by doing string searches, will be inefficient. It is highly recommended to store this information in a structured format (e.g. JSON) until the validation phase is finished.
We collect metadata as the migration runs and then perform a validation job in this way:
- Every time we start the migration job, it queries the Object Datastore to check if the customer (for a particular date) has already been migrated, as shown at Figure 3(a). If the metadata for a particular customer already exists, we know it has been migrated before, so we just skip this customer, otherwise our migration job spins a new migration job for the customer. In this case, the Object Datastore helps us keep the checkpoint for the state of each customer’s migration job.
- For each migrated activity, we write a migration record as metadata to the Object Datastore. To help detect any kinds of exceptions or failures during the validation phase, we keep the migration record atomic. This way we insure data integrity and leverage the validation job to catch any missing data.
- The migration task will keep the metadata in memory and only writes to the Object Datastore once it completes for this customer. We store the activityId, ownerId and the involved customerIds in the metadata and only write them on success, otherwise we log the error for debugging.
- Once the monthly job completes, we kick off the validation job as shown in Figure 3(b). This loads the metadata for a particular month, then aggregates by activityId to validate whether all involved customers have their own activity migrated. Finally, we log the successful activities per customer per month, and re-migrate those events which failed.

In our data migration job, we store the migration metadata as a Scala case class and aggregate all of them in the Object Datastore. The advantage of this approach is that we can easily develop Apache Spark jobs that can quickly load these large metadata files into our cluster and utilize data transformation operations provided by Spark (such as filter and group operations), to conduct the validation.
4. Optimize Migration Jobs
It is essential to optimize migration jobs to avoid introducing large overhead on backend infrastructure and so that it finishes within an acceptable timeframe. We took advantage of a few optimization techniques that you can also use.
Stream data migration
Migrating data via a streams can be more efficient than single item processing and large batches. Read data in a small fixed-size batches from the original data source, do data transformation in each migration task, and then emit the new data to the destination right away. This can help reduce memory overhead and avoid an out-of-memory issue when encountering unbalanced data.
For example, if you are migrating customers’ logs stored in Cassandra, you can use the primary key to fetch each log entry from Cassandra and do the migration. However, this approach produces too many queries. To optimize this you can use a partition key to fetch all log entries of a single customer within one day from Cassandra, and do the migration. However, in this approach you may load a large amount of logs into memory. So instead use micro-batching / streaming in Cassandra via the pagination feature to break the results into pages.
Divide and run in parallel
To speed up migration, it is important to divide a migration job into smaller tasks that can run in parallel. Task division at finer granularity can also help alleviate performance issues caused by unbalanced data. However, if the divided task is too trivial, the migration job will be inefficient because the initialization time for each task will be even longer than the actual task time.
For our migration job, we did some initial benchmark testing on small datasets and compared the performance to decide the granularity for the task. Initially, we looked at dividing the tasks into three granularities: (1) all data of one organization (contains multiple users) in one month, (2) all data of a single customer in one month and (3) one account of a single customer (i.e., a customer can potentially have multiple accounts) in one month. Our benchmark testing showed that granularity “all data of a single customer in one month” had the highest migration speed offering a nice balance between number of tasks and task size.
Cache queries or tables
When doing data transformations you may need to query the database in an abnormal way. For example, during data migration, we needed to query our NoSQL database with a key that is not indexed. In our NoSQL database, queries with non-indexed keys lead to full-table scan for each query. These full-table scans dramatically reduce your migration speed, and induces high CPU load for the database machines. One easy solution is to talk with the Ops team about indexing keys. If such indexing degrades production performance, you should consider caching the queries if it is repeatedly called or caching the table into memory.
During our migration job, we cached several tables in memory in Spark. This approach enables us to do data migrations with little impact on backend infrastructure.
Implement checkpointing whenever possible
If a migration job will be running for days or longer, it is important to implement a checkpointing mechanism in the migration job. When you encounter a service disruption (e.g. regular maintenance) on backend infrastructure, you may need to halt your job and restart your migration later. Having a checkpointing mechanism enables you to continue migration from the last checkpoint. Since we store metadata for validation purposes, we can also reuse the metadata for checkpointing.
Conclusion
We hope this helps you handle your massive data migrations! Let us know if you have any questions or need any help.



