In our “Engineering Energizers” Q&A series, we highlight the leaders behind transformative engineering innovations. Today, we feature Lily Xiao, Director of Software Engineering at Salesforce. Lily leads the development of Agentforce Data Library, an AI-powered retrieval system designed to revolutionize how enterprises access and use information. Her team leverages retrieval-augmented generation (RAG) to improve search accuracy, optimize data ingestion, and refine retrieval workflows, delivering intelligent responses.
Discover how Lily’s team optimized retrieval performance, enhanced AI accuracy, and built a secure, highly available system that scales across multiple Salesforce organizations while maintaining 99.99% uptime.
What is your team’s mission?
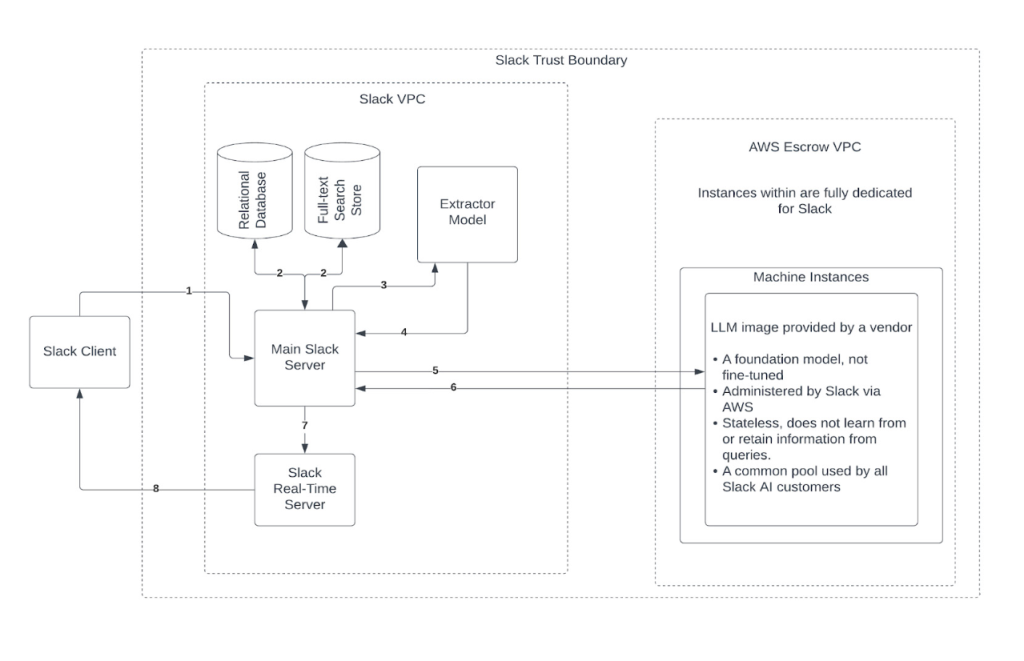
The team is dedicated to developing and optimizing Agentforce Data Library, a RAG system that powers AI-driven customer interactions at an enterprise scale. The entire retrieval pipeline, encompassing automated ingestion, structured indexing, and optimized retrieval workflows, ensures high-precision, low-latency responses.
Agentforce Data Library ingests a variety of data sources, including Salesforce knowledge articles, customer-uploaded files, and external web data. This data is normalized for structured indexing, allowing for seamless integration and retrieval.
To enhance performance, precomputed vector indices for fast lookups and retriever selection logic that prioritizes high-confidence sources have been implemented. Additionally, multi-modal retrieval capabilities are being developed, integrating image-based knowledge extraction using vector-based image indexing.
By continuously refining retrieval accuracy, scaling efficiency, and AI-driven search, the team ensures that Agentforce Data Library delivers accurate, reliable responses without the need for manual configuration overhead.
What was the most complex technical challenge after Agentforce Data Library’s launch?
After Agentforce Data Library’s GA launch, inconsistencies in retrieval performance were identified. Some queries executed quickly, while others experienced unexpected slowdowns, particularly under heavy workloads. In addition to latency variations, inefficiencies in retriever selection and unnecessary data fetching increased computational overhead.
To diagnose the root cause, distributed tracing and API profiling were implemented across the retrieval pipeline. This allowed for tracking query execution paths and measuring inefficiencies at each stage. The analysis revealed two major bottlenecks: retriever selection logic was issuing redundant Data Cloud queries, unnecessarily increasing processing time, and some retrieval steps were executed sequentially rather than in parallel, causing query slowdowns. Additionally, retrieval prioritization was not consistently favoring high-confidence sources, leading to inefficiencies in data fetching.
To address these issues, query pre-filtering was optimized to eliminate redundant lookups, retriever execution was restructured to minimize unnecessary fallback dependencies, and the scoring model for retriever prioritization was refined. These changes significantly improved retrieval consistency, making response times more predictable while reducing computational overhead.
Lily explains what keeps her at Salesforce.
How did your team eliminate AI hallucinations and improve accuracy in Agentforce Data Library?
AI hallucinations, where models generate plausible but incorrect responses, posed a significant challenge post-GA. These issues often arose from low-confidence retrievals, where the AI lacked sufficient grounding in high-quality knowledge sources.
To tackle this, the team implemented confidence-weighted retriever selection. Each retriever now produces a confidence score based on past retrieval accuracy, document credibility, and contextual relevance. The AI agent prioritizes high-confidence responses while deprioritizing ambiguous results.
Additionally, context-enriched indexing was introduced. This method embeds additional metadata into retrieved documents, allowing AI models to access structured context before generating responses. This prevents the LLM from fabricating answers based on partial or ambiguous data.
Another critical improvement was the introduction of stepwise query refinement. If a query yields low-confidence results, Agentforce Data Library re-runs an adjusted query, iteratively improving retrieval precision. These enhancements collectively resulted in a more reliable and accurate retrieval pipeline.
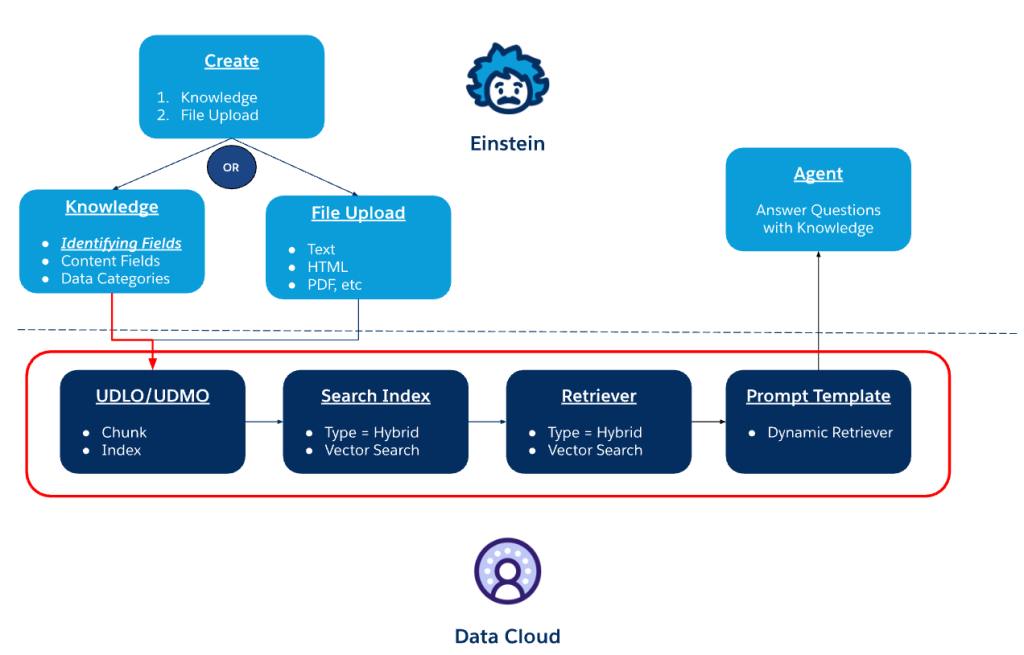
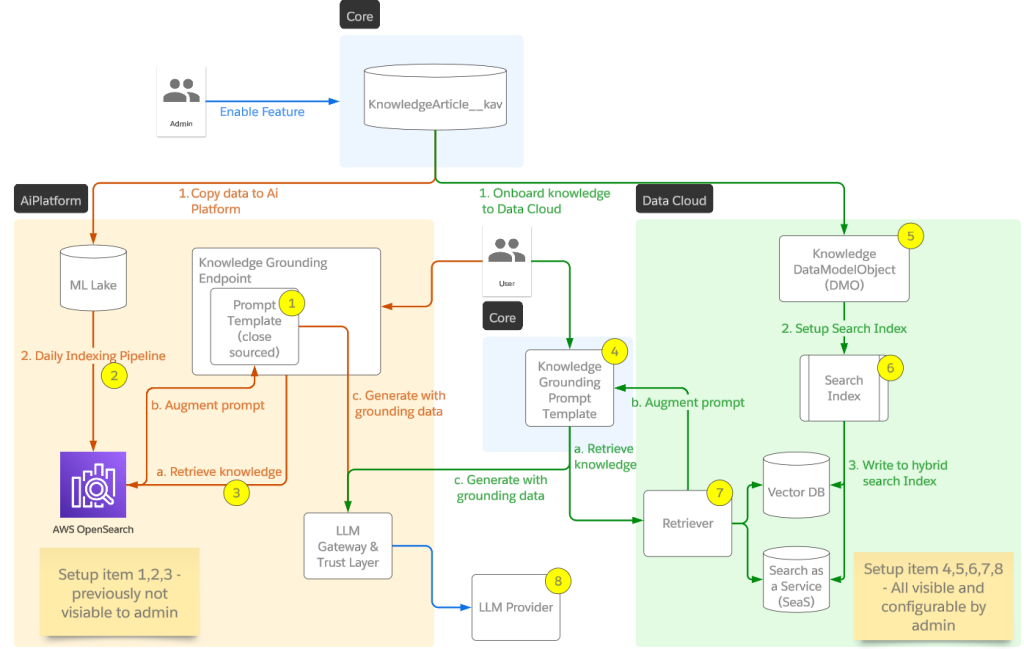
Component diagram for Agentforce Data Library configuration and runtime.
What were the biggest engineering challenges in integrating Agentforce Data Library with Salesforce CRM and multi-org businesses?
Seamless integration of Agentforce Data Library across multiple Salesforce orgs, each with distinct data security, permissions, and retrieval requirements, presented significant engineering challenges. One primary challenge was ensuring that sandbox environments could replicate production retrieval workflows, allowing enterprises to test AI-powered interactions without compromising data integrity.
To address this, a metadata replication system was built, enabling sandbox instances to automatically inherit retrieval configurations, document indexing rules, and security policies from production environments. This allowed organizations to validate retrieval workflows without the need for manual setup.
Another major challenge was cross-org data retrieval, where enterprises required a single AI-powered retrieval system to query knowledge across multiple Salesforce instances while maintaining org-specific security boundaries. This was solved by developing context-aware retrieval policies, ensuring that retrieval requests respect user authentication scopes, data-sharing agreements, and field-level security settings.
These innovations enabled large-scale AI retrieval workflows to function across complex multi-org environments while preserving data isolation and governance policies.
How does Agentforce Data Library maintain high availability while scaling for enterprise-wide adoption?
Ensuring that Agentforce Data Library supports enterprise-scale adoption with 99.99% uptime was a top priority. To achieve this, a distributed retrieval architecture was developed to guarantee high availability and fault tolerance.
The retrieval pipeline leverages asynchronous processing, enabling AI-driven retrieval tasks to execute without blocking other operations. Load balancing distributes retrieval workloads across multiple compute nodes, preventing any single node from becoming a bottleneck.
To proactively manage system health, real-time monitoring dashboards track retrieval success rates, latency metrics, and failure patterns. In the event of system degradation, automated failover mechanisms ensure that retrieval services are instantly redirected to healthy nodes.
These optimizations allow Agentforce Data Library to scale seamlessly across thousands of customer deployments while maintaining near-instantaneous retrieval speeds.
How does your team balance rapid feature development for Agentforce Data Library with security, trust, and long-term stability?
The team follows a progressive rollout strategy to ensure new retrieval features are introduced safely without disrupting existing workflows. Features first undergo internal testing and sandbox deployments. Next, these features are rolled out to early access customers via feature flags. Finally, once retrieval benchmarking confirms stability, the features are made available to all customers through general availability.
Security is a paramount concern and is enforced through end-to-end encryption at both the storage and retrieval layers. Automated static analysis and manual security reviews are conducted for any changes affecting retrieval logic, APIs, or authentication workflows.
To prevent regressions, retrieval benchmarking tests measure precision and recall before release. Real-time observability tooling tracks retrieval success rates and latency, triggering alerts if anomalies arise.
By combining staged rollouts, retrieval benchmarking, security enforcement, and version control, the team ensures that Agentforce Data Library evolves rapidly while maintaining reliability and trust.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.