

Looking for signals in the initialization of encrypted communication channels is not a new concept. There are many examples of fingerprinting both unencrypted and encrypted protocols such as TLS. However somewhat surprisingly, no open source scalable fingerprinting method has been developed for one of our most common and relied upon encrypted protocols SSH — an integral component of the internet. Enter, the HASSH.
HASSH is a network fingerprinting standard invented within the Detection Cloud team at Salesforce. It can be used to help identify specific Client and Server SSH implementations. These fingerprints can be easily stored, searched and shared in the form of a standard string of summary text, a hassh for the Client and hasshServer for the Server.
We have Open Sourced HASSH and it’s available here: https://github.com/salesforce/hassh
What problems does HASSH help solve?
SSH is the de facto secure communication channel in use on the internet, yet there is no framework to help determine the “bona fides” of the SSH components themselves.
Gaining a greater insight into the observable nature of SSH clients and servers opens up a few really interesting possibilities. To get a sense of some problems that HASSH aims to help solve, consider these potential use cases:
- HASSH can be deployed in highly controlled and well understood environments, where it may be desirable to create an alert or even block any client with a hassh fingerprint outside of a known “good set”.
- It is possible to detect, control and investigate brute force or Cred Stuffing password attempts at a higher level of granularity than IP Source — which may be impacted by NAT or botnet-like behaviour. The hassh will be a feature of the specific Client software implementation being used, even if the IP is NATed such that it is shared by many other SSH clients.
- Consider covert exfiltration of data — where data is sent outbound within the components of the Client algorithm sets. In a scenario similar to the more commonly known “DNS exfil”, a specially coded SSH Client can send data outbound to a less trusted environment within an endless series of SSH_MSG_KEXINIT packets. These packets are discrete attempted but incomplete connections which means they are unlogged and may not be detected even by volume aggregation alerting as the connection never occurred. These packets would be sent to an SSH server controlled by a bad actor who then records, decodes and reconstitutes these pieces of data into their original form. Until now such attempts — much less the content of the clear text packets — are not likely to logged even by mature packet analyzers or on end point systems. Detection of this style of exfiltration can now be performed easily by using anomaly detection or alerting on SSH Clients with multiple distinct hassh values.
- The method can be used by itself or to augment other contextual indicators to detect Recon and Lateral movement attempts used in exploit kits. An example might be if the hassh of a connection is known to belong to an exploit kit module and this hassh has been detected on the internal network mapping out networks or moving laterally by connecting to adjacent networks or bastion hosts.
- Augmentation of Client application controls in less trusted environments is possible, for example one could use hassh to contribute towards blocking Clients from connecting to an SSH server because that Client hassh is outside of an approved “known good” set of hassh values. Such contribution would be used alongside higher layer controls. As an example if a private key (passworded or passwordless) from an orchestration system is somehow compromised, then any connections to servers using that key, but which does NOT have the legitimate hassh of the orchestration system — this can be alerted on.
- HASSH contributes towards establishing Non Repudiation in a Forensic context. Connection attempts can now be attributed with greater granularity than only by IPSource. The hassh will be a feature of the specific Client software implementation being used, even if the IP is NAT’ed such that it is shared by other SSH clients.
- HASSH can assist in detection of Deceptive Applications. For example a hasshServer known to belong to the SSH honeypot server installation (like Cowrie or Kippo), but is purporting to be a common OpenSSH server. Depending on the environment, even more general anomaly based alerting can occur when a Server Identification string does not match with a known good hasshServer for that Server.
- Detection of devices with hassh known to belong to IOT embedded systems is trivial and accurate with HASSH. Examples may include cameras, mics, keyloggers and wiretaps that could be easily be hidden from view and communicating quietly over encrypted channels back to a control server. Apart from these malicious use cases, it may interest organizations to be aware of the prevalence of IOT devices in their networks.
- HASSH can be used to monitor or even shun/RST Client or Server applications that are unpatched, or unapproved. Along these same lines, it could be used to passively identify devices for which there may be current security advisory or high impact exploits and that need to be contained.
How does HASSH work?
hassh and hasshServer fingerprints are MD5 hashes constructed from a specific selected set of algorithms that are supported and prefered by various SSH Applications.
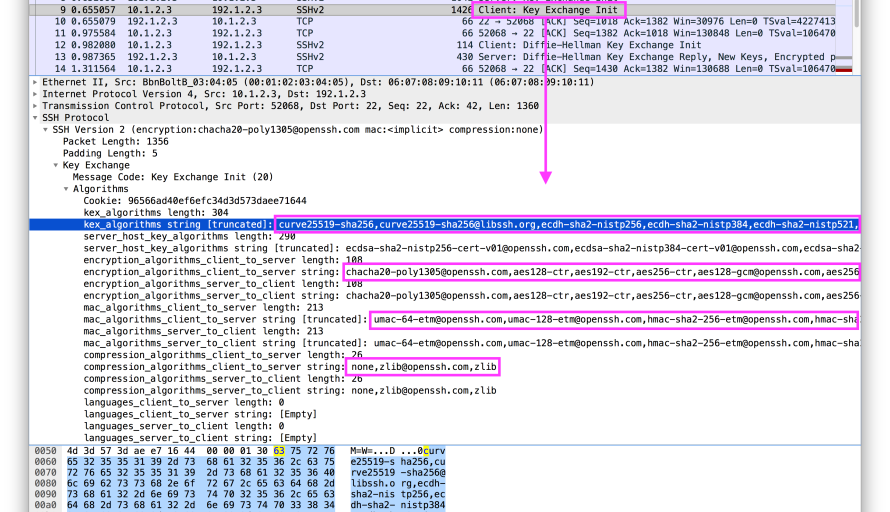
These algorithms are exchanged after the initial TCP three-way handshake as clear-text packets known as “SSH_MSG_KEXINIT” messages. This negotiation forms an integral and required component of the setup of the final encrypted SSH channels. These initial packets also include Server and Client Identification strings, which can be thought of as analogous to User-Agents, except parts of these strings (like the Protocol Version number) are used programmatically. These strings are important to document alongside the hassh and hasshServer as they are important context and can indicate deception, so our code also logs these fields separately for reference.

The existence and ordering of the algorithms in the SSH_MSG_KEXINIT packets is unique enough such that it can be used as a fingerprint to help identify the underlying applications, regardless of higher level ostensible identifiers such as Client and Server Identification strings. It is this uniqueness in low level algorithms that HASSH leverages.


Example of HASSH in action
For a “Cyberduck” SFTP client, more specifically SSH-2.0-Cyberduck/6.7.1.28683 (Mac OS X/10.13.6) (x86_64) , the set of supported algorithms seen in the SSH_MSG_KEXINIT packets is as follows:
Key Exchange methods
curve25519-sha256@libssh.org,diffie-hellman-group-exchange-sha256,ecdh-sha2-nistp521,ecdh-sha2-nistp384,ecdh-sha2-nistp256,diffie-hellman-group-exchange-sha1,diffie-hellman-group1-sha1,diffie-hellman-group14-sha1,diffie-hellman-group14-sha256,diffie-hellman-group15-sha512,diffie-hellman-group16-sha512,diffie-hellman-group17-sha512,diffie-hellman-group18-sha512,diffie-hellman-group14-sha256@ssh.com,diffie-hellman-group15-sha256,diffie-hellman-group15-sha256@ssh.com,diffie-hellman-group15-sha384@ssh.com,diffie-hellman-group16-sha256,diffie-hellman-group16-sha384@ssh.com,diffie-hellman-group16-sha512@ssh.com,diffie-hellman-group18-sha512@ssh.com
Encryption
aes128-cbc,aes128-ctr,aes192-cbc,aes192-ctr,aes256-cbc,aes256-ctr,blowfish-cbc,blowfish-ctr,cast128-cbc,cast128-ctr,idea-cbc,idea-ctr,serpent128-cbc,serpent128-ctr,serpent192-cbc,serpent192-ctr,serpent256-cbc,serpent256-ctr,3des-cbc,3des-ctr,twofish128-cbc,twofish128-ctr,twofish192-cbc,twofish192-ctr,twofish256-cbc,twofish256-ctr,twofish-cbc,arcfour,arcfour128,arcfour256
Message Auth
hmac-sha1,hmac-sha1–96,hmac-md5,hmac-md5–96,hmac-sha2–256,hmac-sha2–512
Compression
zlib@openssh.com,zlib,none
Concatenating these algorithms together with a delimiter of “;” gives the hasshAlgorithms, which can be useful to record for detailed analysis.
curve25519-sha256@libssh.org,diffie-hellman-group-exchange-sha256,ecdh-sha2-nistp521,ecdh-sha2-nistp384,ecdh-sha2-nistp256,diffie-hellman-group-exchange-sha1,diffie-hellman-group1-sha1,diffie-hellman-group14-sha1,diffie-hellman-group14-sha256,diffie-hellman-group15-sha512,diffie-hellman-group16-sha512,diffie-hellman-group17-sha512,diffie-hellman-group18-sha512,diffie-hellman-group14-sha256@ssh.com,diffie-hellman-group15-sha256,diffie-hellman-group15-sha256@ssh.com,diffie-hellman-group15-sha384@ssh.com,diffie-hellman-group16-sha256,diffie-hellman-group16-sha384@ssh.com,diffie-hellman-group16-sha512@ssh.com,diffie-hellman-group18-sha512@ssh.com;aes128-cbc,aes128-ctr,aes192-cbc,aes192-ctr,aes256-cbc,aes256-ctr,blowfish-cbc,blowfish-ctr,cast128-cbc,cast128-ctr,idea-cbc,idea-ctr,serpent128-cbc,serpent128-ctr,serpent192-cbc,serpent192-ctr,serpent256-cbc,serpent256-ctr,3des-cbc,3des-ctr,twofish128-cbc,twofish128-ctr,twofish192-cbc,twofish192-ctr,twofish256-cbc,twofish256-ctr,twofish-cbc,arcfour,arcfour128,arcfour256;hmac-sha1,hmac-sha1–96,hmac-md5,hmac-md5–96,hmac-sha2–256,hmac-sha2–512;zlib@openssh.com,zlib,none
Finally, the hassh is simply an MD5 hash of hasshAlgorithms. Examples:
8a8ae540028bf433cd68356c1b9e8d5b CyberDuck Version 6.7.1 (28683)b5752e36ba6c5979a575e43178908adf SSH-2.0-paramiko_2.4.1 (E.g. used by Metasploit exploit kit modules)16f898dd8ed8279e1055350b4e20666c SSH-2.0-dropbear_2012.55 (IOT)06046964c022c6407d15a27b12a6a4fb SSH-2.0-OpenSSH_7.6de30354b88bae4c2810426614e1b6976 SSH-2.0-Renci.SshNet.SshClient.0.0.1 (Powershell, E.g used by Empire Exploit kit)fafc45381bfde997b6305c4e1600f1bf SSH-2.0-Ruby/Net::SSH_5.0.2 x86_64-linux (Ruby, E.g. used by Metasploit exploit kit modules)
Similarly, here are some examples of hasshServer:
c1c596caaeb93c566b8ecf3cae9b5a9e SSH-2.0-dropbear_2016.74d93f46d063c4382b6232a4d77db532b2 SSH-2.0-dropbear_2016.722dd9a9b3dbebfaeec8b8aabd689e75d2 SSH-2.0-AWSCodeCommit696e7f84ac571fdf8fa5073e64ee2dc8 SSH-2.0-FTP
Is there a list of hassh and hasshServer values I can use?
Technically, a list of values (though not necessarily a good one) can easily be made just by running HASSH and documenting the values and the purported Client/Server Identifier strings. However, this shouldn’t be trusted at face value without confirmation that client/server is indeed what it says it is. One way to solve this issue in an authoritative manner is by generating a series of connections by the various clients you are interested in and documenting the hassh these produce. We have provided a script to do this, and as a demonstration it currently supports 49 different version of OpenSSH, Python’s paramiko and Dropbear embedded clients.
It is also very important to note the hassh values aren’t necessarily global in nature, they can be very specific to your own environment. For example perhaps your clients and servers are run with very specific lists/order of algorithms — this may be unique to your environment, in which case this may make detection of non matching clients a great use case for HASSH.
The key point here is that when storing hassh, hasshServer and Identifier Strings, it is important to record the source of the data, as this is important in context of confidence and situational awareness.
Was the Language field used in the HASSH?
Interestingly, within the SSH_MSG_KEXINIT packets there is a field for both the Client and Server to specify the preferred Language. The RFC states that this field is not to be populated unless it is known to be required by the sending party. To date we have not seen anything other than empty Language fields, and since it is more a human layer function it was not included. Even so, this field is logged by our Python implementation, with provision for support within the bro script. This way the field can be tracked and can also be used in conjunction with the hassh at any stage if that is important to a specific implementation.
Why were the SSH Host key algorithms left out?
This had us stumped for a little while. We noticed that a client would have one set of SSH host key algorithms in SSH_MSG_KEXINIT packets, then it would change to another set for reasons unknown. This of course changed the hassh value and seemed to be polluting the analysis.
At first we couldn’t replicate it easily, but then realized what happens:
- Some SSH clients (not by any means all, but some like OpenSSH) when first connecting to a SSH server use a default list of key algorithms. The client doesn’t know this server yet…
- Once the connection is established, the client populates its known_hosts with the key of this server, including the algorithm of the Server host key.
- On subsequent connections, the client sends a slightly different list of algorithms, this time using the algorithm that it knows the server uses — as being the first in the prefered list.
This makes sense, and we were happy to solve the case of the mysteriously changing hassh. However since this list of host key algorithms is a more function of the history of the client’s knowledge of the server rather than a function of the client itself, it was not included in the hassh and hasshServer composition. It also was helpful that there seemed to be more than enough entropy in the other four fields we use in the hassh. However the list of host algorithms is still captured by our scripts, as this an important datapoint to determine if this is the client’s first, or subsequent connection to this server.
Why was MD5 used, and not a stronger hash?
Of all things, this had us torn. The notion of using a digest algorithm that is long known to have collisions seemed wrong. For this reason, we changed to the more robust SHA-256 for a short time; however during analysis the 64 character length of the SHA-256 was just too long, particularly when looking for many at once, or on a dashboard. It seemed the longer length was adding complexity when we were aiming for simplicity, and wasn’t solving a real problem in return. In the end, we made an assessment that MD5 hash collisions with this data type are not a real concern, so we made an about-turn and opted for the more compact 32 character MD5 hash. Time will tell !
What has HASSH seen so far?
Analysis continues and we’ll probably post about that later, but analysis of “Internet traffic noise” has broadly revealed the following:
- Examples of SSH Brute Force or “Cred Stuffing” attacks, sometimes using deception, perhaps to circumvent any controls or monitoring based on Client Identification string. For example an SSH connection that is known to have the hassh of default Golang Client, but is claiming to be a variety of Clients — anything from OpenSSH to Putty. This scanner can be seen simply cycling through these protocols one at a time. Detecting cred stuffing attacks over SSH is made more accurate with HASSH.
- The uniqueness of hassh seems to group families of software together and an gives indication that the same code base was used. For example many versions of WinSCP client have the same hassh as Putty. This is not surprising as they are in the same family of products, but it is an interesting point to note regarding a commonality of code bases in use as it could potentially go towards attribution in some scenarios.
- The Client Identification string is not always completely accurate in a granular sense, even for legitimate installations. Sub-versions of the same major version can have a different hassh, whilst the Client Identification String itself will remain unchanged, displaying the Major version and not the subversion/patch. This observation is useful as hassh can be leveraged to determine the specific granular sub-version, which is often important when mitigating vulnerabilities in various versions and patch levels.
Conclusion
HASSH should not be seen as a silver bullet, however we hope that it “moves the needle” on our understanding and visibility of the interactions between clients and servers of arguably one of our most critical protocols, SSH.
Be sure to check out our github repo, you can also contact me via email or @benreardon
References
RFC4253 The Secure Shell (SSH) Transport Layer Protocol
JA3 supporting TLS.
Credits:
The HASSH method was conceived and developed by Ben Reardon (@benreardon) within the Detection Cloud Team at Salesforce. Inspiration and significant contributions came from Adel Karimi (@0x4d31) and the JA3 crew: John B. Althouse, Jeff Atkinson, and Josh Atkins



