By Paladi Sandhya Madhuri, Rakesh Chhabra, Piyush Pruthi, Sumit Sahrawat, Ankit Jain, and Basaveshwar Hiremath.
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today’s edition features Paladi Sandhya Madhuri, a Senior Software Engineer on the Marketing Cloud Caching team, whose work involves evolving the platform’s core caching infrastructure to support high-volume, latency-sensitive workloads, including a live migration handling approximately 1.5 million cache events per second across over 50 applications.
Explore how the team executed a zero-downtime migration under live production traffic, preserving application behavior while changing the underlying cache engine, managing hot-key pressure from Redis at scale, and validating stable performance and reliability by sustaining end-to-end P50 latency near 1 millisecond and P99 latency around 20 milliseconds throughout the transition.
What is your team’s mission migrating Marketing Cloud’s core caching infrastructure from Memcached to Redis Cluster?
The team embarked on a mission to modernize the Marketing Cloud’s core caching layer. Their goal was to maintain availability, security, and performance at scale, which was a significant undertaking.
The existing Memcached-based system, while supporting a vast application ecosystem, presented challenges with its lack of native replication and built-in user authentication, making it difficult to meet evolving uptime, security, and maintenance demands. The absence of replication meant that a failure of a Memcached node required rebuilding the entire cache, leading to increased latency and significant load on the underlying databases. Introducing replicas ensured that a warm standby was always available, enabling faster failover and minimizing performance impact. This approach also strengthened the high-availability strategy during planned maintenance activities such as Redis patching, operating system upgrades, and in scenarios involving hardware failures.
Redis Cluster offered a direct solution to these constraints. It provides intrinsic primary–replica replication for seamless failover, native authentication and ACLs for stronger data-layer security, and predictable sub-millisecond performance with horizontal scaling through sharding. This migration also aligned the caching tier with broader infrastructure modernization efforts, such as the move to RHEL 9, allowing several platform initiatives to advance concurrently.
A crucial aspect of this mission was avoiding disruption. The team committed to executing the migration without requiring application code integration changes, without any user-visible impact, and without downtime. This was all while supporting approximately 1.5 million cache events per second across more than 50 services, emphasizing that behavioral parity and operational control were as vital as the underlying technology shift itself.
What constraints shaped your zero-downtime migration strategy for a live caching tier handling roughly 1.5 million requests per second across more than 50 applications?
The defining challenge for this migration was that it had to occur entirely under live production traffic. This meant no service interruptions and no changes required from the upstream application teams. Considering that dozens of services shared cache infrastructure and some of them even shared cache keys, even minor inconsistencies could lead to correctness issues, cache misses, or cascading latency spikes.
To facilitate a safe and incremental cutover, the team introduced a Dynamic Cache Router within the data access layer. This was paired with several complementary mechanisms:
- Percentage-based routing, allowing deterministic traffic shifts between Memcache and Redis without redeployments.
- Double-writes during warm-up, ensuring long-lived keys were populated in Redis before read traffic shifted.
- Service grouping by key ownership and criticality, preventing split-brain behavior across services sharing cache keys.
Short-lived keys relied on existing cache-aside logic for reactive warm-up. This combined with centralized configuration and real-time propagation of routing changes, allowed the team to transition the full production workload with zero downtime. Throughout this process, they maintained stable cache hit rates and predictable latency.
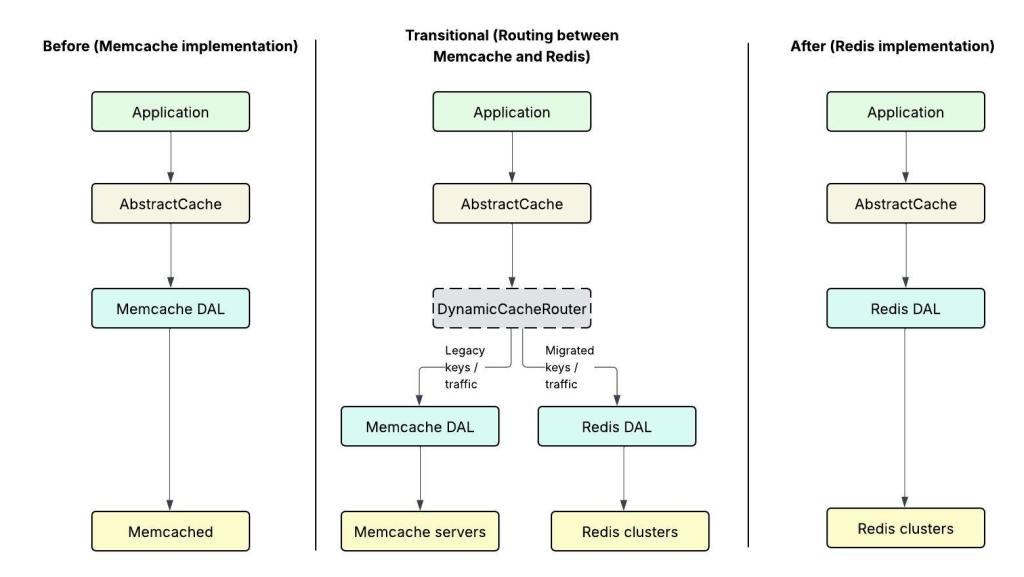
Caching DAL migration: From initial to transitional to final state.
What functional parity constraints emerged from differences in TTL semantics and key-handling behavior between Memcached and Redis?
Maintaining functional parity introduced subtle but high-risk challenges, particularly in two areas:
- Time-to-Live (TTL) semantics, including differences in how zero, negative, and short-duration TTLs are interpreted between Memcached and Redis and the shift from second- to millisecond-level precision.
- Key-handling behavior, especially for keys containing spaces or non-standard formatting relied on by existing instrumentation.
The team meticulously analyzed TTL usage across all consuming services, building a comprehensive matrix to capture real production ranges and edge cases. Dashboards and alerts were crucial for surfacing non-standard TTL patterns, prompting the team to work directly with service owners to understand the intent behind those values. This analysis informed a compatibility layer that normalized TTL interpretation, ensuring Redis DAL (Data Access Layer) behavior exactly matched existing application expectations.
Key handling required similar care. The compatibility layer validated and normalized keys to preserve legacy behavior without forcing upstream changes. By enforcing strict behavioral equivalence in the data access layer, the migration remained invisible to applications while maintaining correctness at scale.
During the migration, the team identified opportunities to strengthen caching best practices without breaking existing integrations. This resulted in clearer guidelines around cache usage, including recommended payload size limits, reasonable TTLs to avoid excessive write churn, and improved instrumentation to observe key sizes and access patterns. Enhanced visibility into data volume and write behavior enabled teams to proactively optimize cache usage while preserving full backward compatibility for existing applications.
What hot-key performance constraints did Redis Cluster’s single-threaded shard model introduce?
Redis Cluster processes commands on a single thread per shard. This means heavily accessed keys can saturate a single CPU core, creating localized performance bottlenecks. Under high request rates, these “hot-key” patterns can drive shard-level CPU spikes, which in turn threaten latency and overall cluster stability.
A hot-key detection capability was built in Memcache to identify potential hot keys before migration. This was evaluated by building traffic analysis tool on Memcache and Redis. The tools periodically scanned for keys exceeding a defined access-frequency threshold and exported the findings to Splunk for analysis.
To address this more systematically going forward, the team is implementing proactive hot-key detection directly within the Redis data access layer. A locally running probabilistic model based on a Count-Min Sketch will continuously track key access frequencies. Keys exceeding predefined thresholds will be flagged, and global Redis counters will be used to validate the behavior under real production traffic before mitigation is applied.
Mitigation efforts primarily focused on application-level changes. Identified hot keys were refactored to employ hybrid caching patterns. This involved combining local in-memory caches, backed by Redis itself, to dramatically reduce the pressure on individual shards. Additionally, read replicas served as a short-term measure to distribute the load until the necessary code changes could be fully deployed. Together, these strategic approaches effectively stabilized shard CPU utilization, allowing Redis Cluster to reliably sustain production traffic.
What traffic-routing constraints guided your design of a dynamic cache router for percentage-based cutover between Memcached and Redis?
Traffic routing presented a challenge: it needed to offer fine-grained control while simultaneously preserving consistency for shared cache keys across more than 50 services. Services that shared keys absolutely had to migrate together. This was crucial to prevent split-brain behavior or the dreaded stale reads, making precise coordination and determinism utterly essential.
The team responded by grouping services into migration cohorts. These cohorts were carefully determined based on factors like traffic volume, business criticality, and key ownership. The Dynamic Cache Router then applied the same CRC32 hashing algorithm that Redis Cluster uses internally. This ensured that routing decisions consistently aligned with shard ownership and remained stable even as cutover percentages were adjusted.
A centralized configuration manager was put in place to propagate routing updates across the entire fleet in real time. This system allowed the enabled percentage for each group to be gradually increased, moving from zero all the way to full cutover. This design offered several key advantages: it enabled controlled experimentation, facilitated precise cache-miss management, and allowed for rapid rollbacks, all without the inconvenience of application restarts or redeployments.
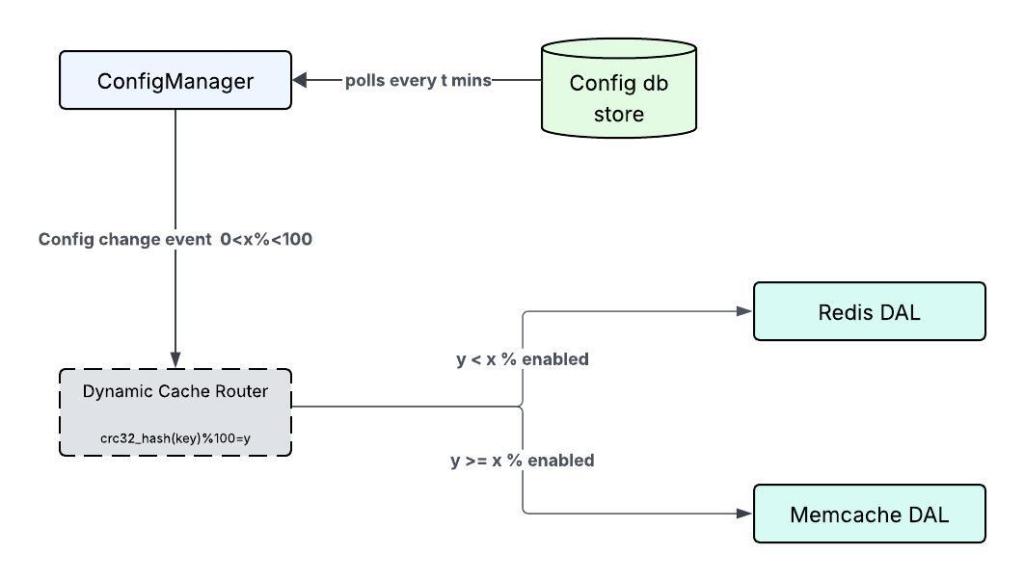
DCR Routing logic.
What validation constraints guided how you proved Redis Cluster could sustain target latency and stable cache hit ratios under production load?
Validation required proving more than just average performance. It demanded demonstrating sustained tail latency and cache efficiency under authentic production conditions. Synthetic benchmarks simply fell short here; they consistently fail to capture the nuances of real access patterns, TTL distributions, and crucial replica-read behavior.
To overcome this, the team constructed production-faithful load tests. These tests incorporated actual key and value sizes, observed TTL distributions, and realistic traffic mixes. Long-running soak tests were particularly insightful, surfacing issues like memory growth, connection pool pressure, or the subtle effects of garbage collection within the data access layer. These are the kinds of problems that can gradually degrade tail latency over time.
During the migration itself, cache hit and miss metrics were meticulously compared in parallel between Memcached and Redis. This was done while double-writes and a gradual read cutover process were actively in place. This rigorous validation definitively confirmed that Redis sustained end-to-end P50 latency around 1 millisecond and P99 latency near 20 milliseconds from the data access layer, all while maintaining stable hit ratios, before the full shift of production traffic occurred.
What’s next in this migration journey?
As the migration advances, the next phase focuses on scaling read throughput and isolating load hotspots to improve overall cluster stability. A key initiative is the segregation of read and write traffic, where all write operations are directed to primary nodes, while read replicas are leveraged to serve GET traffic. This separation ensures that increasing read volume does not contend with write workloads, allowing primary nodes to remain write-optimized while reducing latency and increasing aggregate read capacity.
Equally important is the introduction of an adaptive throttling mechanism aimed at hot keys. Rather than applying static or cluster-wide limits, the system identifies keys that generate disproportionate traffic and selectively throttles requests targeting those keys. This prevents individual shards from becoming overloaded, protects the rest of the cluster from cascading failures, and helps maintain predictable tail latencies under peak load.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.