
The Problem
At Salesforce, trust is our number one value. What this equates to is that our customers need to trust us; trust us to safeguard their data, trust that we will keep our services up and running, and trust that we will be there for them when they need us.
In the world of Software as a Service (SaaS), trust and availability have become synonymous. Availability represents that percentage of time and/or requests successfully handled.
Availability can be calculated as the number of successful requests divided by the number of total requests.
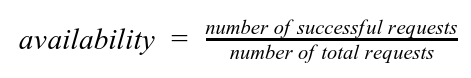
As a result, a few things become prevalent.
- In order have high availability, you must have low mean time to recovery (MTTR).
- In order to have low MTTR, you must have low mean time to detection (MTTD).
- How can we distinguish between server errors and client errors? Is our availability penalized for client errors?
- How do we calculate the availability of our service in regards to dependent services? Should our availability metrics show when a dependent service is down?
The Solution
In order to comprehensively tackle this issue, we implemented a three-pronged strategy for the Salesforce Commerce APIs: monitoring, continuous testing, and alerting. Additionally, availability is broken down into multiple categories to allow for pinpointing and tackling problematic areas.
Monitoring
At the core of this problem is the ability to observe what is happening in the system. For a given API call, we need to know:
- The overall latency
- The response code
- The latency and response codes for calls to any dependent services
For many service-based systems under load, the raw metrics exceed the capability of any realtime metrics database and the data has to be aggregated and downsampled. In our experience, aggregating and downsampling to 1 minute intervals and publishing the p95 and p99 is sufficient for catching most issues and keeping MTTD to a few minutes.
Additionally, the data needs to be tagged so that it can be queried and aggregated at a granular level. Since our services are multi-tenant, we often associate the following tags with the metric.

* Service name represents the type of service that will process the request.
This can be used to differentiate systems from their dependent systems.
With fine grained metrics in place, we now have the data on how the system and its interactions with external entities are behaving.
If one of our dependencies is throwing errors, we have the data to find and prove it. If one of our systems has a high latency, we have the data to find and prove it. If one of our tenants is having an issue, we have the data to find and prove it.
For example, let’s take a hypothetical service that we are building around searching for ecommerce products. For scalability and control, we have separated it into two isolated web applications: ingestion and search. This service uses a managed elastic search service as its data store, which we make requests through its REST API. Below are example queries used to measure the overall and internal latency and counts.

Continuous Tests
While we have the data to show what our customers are experiencing, we do not have the ability to infer what they are doing or even ensure they are doing it the way we want.
A customer may be repeatedly
- Calling us with an invalid token
- Asking for an invalid resource
- Specifying invalid data
This can make interpreting metrics difficult and make it difficult to track issues that arise around these types of errors. While we can protect ourselves using techniques such as rate limiting and circuit breaking, this doesn’t help us identify all errors that may be impacting customers (e.g. an expired SSL cert error).
One mechanism to aid in mitigating this is continuous testing. Continuous testing refers to running a set of tests, on a routine interval, against a test tenant, that exercise common flows through the system.
- Ability to write to a data store
- Ability to get / write to an external service
- In our ecommerce world, the ability to find a product, add it to a cart, and check out.
This is more than just a health check. It is ensuring the system is exercised and functioning as expected.
This data can be used as a source of truth. One of our problems, described above, is how to distinguish if client errors are a problem and if they should be included in our availability. In the case of continuous testing, we control the client. If we get a client error (4xx) back that we aren’t expecting, then the system is not functioning as expected, and we need to investigate and fix the problem.
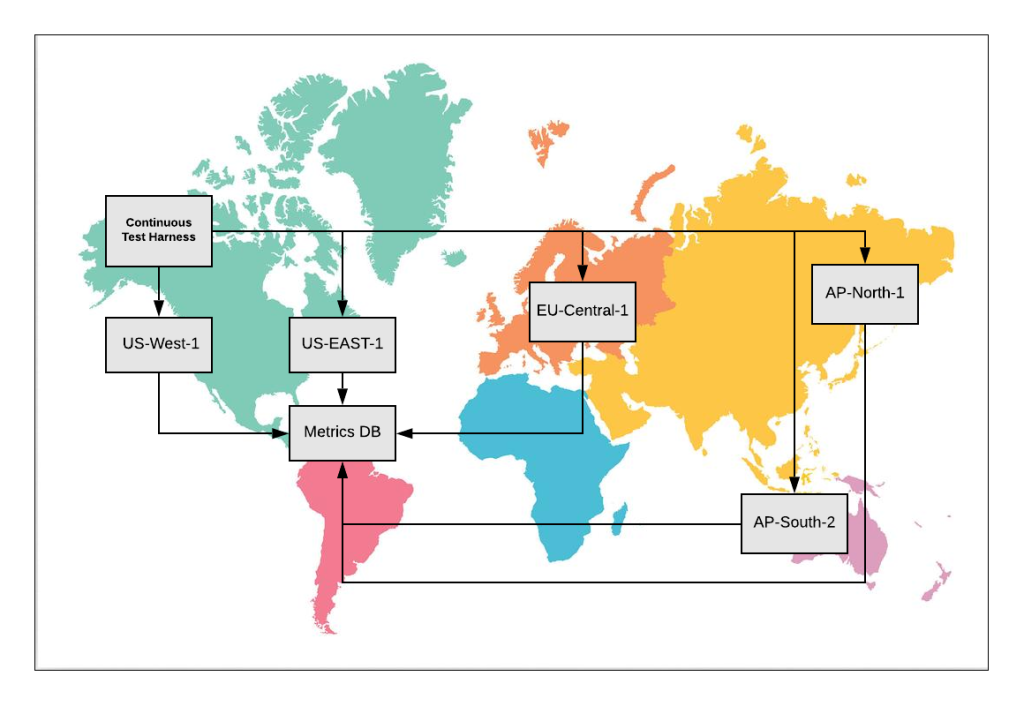
The above diagram depicts how one may set up multi-region deployments, exercise them with a continuous test harness, track the metrics, and compute availability and alerts.
Alerting
With both fine-grained monitoring and a source of truth in place, the next step is to enable alerting based on this data. This alerting is the core of what we use to drive our MTTD down.
The following alerts are used to to back this process.
- Excessive server errors (5xx) across all tenants
- Excessive p95 latency across all tenants
- Validation that continuous tests are running (metrics exist for the test tenant at least once per continuous test interval).
- Excessive server (5xx) and client errors (4xx) for our continuous test tenant
By incorporating our source of truth in our alerting, we are able to quickly detect errors from multiple paths within the system. Our MTTD becomes at most our continuous test interval.
Categories of Availability
With our monitoring and source of truth in place, we can now compute our availability numbers in a few different ways to get a better understanding of how our service is performing.

By breaking down availability into these four categories — general availability, service availability, synthetic availability, and synthetic service availability — we are able to pinpoint any weaknesses in the system and identify where to invest to make it more robust.
Qualification and Production Deployment Validation
A secondary use case of our continuous testing is to aid in our pre-production qualification and post-production validation.
We employ a policy where all changes must soak in our pre-production environment for at least 24 hours before being deployed. During that time period we automatically run a daily load, to establish and validate performance trends, and run our continuous tests on a regular interval.
When it comes time to deploy, if our performance is within the acceptable bounds of our baseline, and our continuous tests have been stable since the application was deployed, we consider the application qualified and ready to be deployed to production
Please note this is only a subset of the pre-production qualification process and does not spell out our practices for unit testing, integration testing, and static analysis, which should always be performed prior to deploying to a staging/pre-production environment.
Once the application is deployed to production, we immediately run our continuous test suite against it. If it fails or if one of the subsequent runs fail, we immediately know that we have caused a problem, and a rollback is warranted.
Additionally, we roll out to each of our product environments in a sequential manor, using the one with the least usage as the canary as a final risk reduction technique.
Approaches like this enable a quick MTTD with a rollback that will result in a quick MTTR. The faster we recover, the higher our availability is.
Conclusion
As service owners look towards increasing their availability and decreasing their MTTD and MTTR, fine-grained metrics, alerting, and continuous testing can play a major role. Having a source of truth and continuously exercising the service provide a robust way to ensure it is functioning properly and a method to quickly debug issues that may arise.
This approach also provides an easily extensible model to aid in managing multi-app, multi-region, multi-partition deployments.

The above graph is an example dashboard showing data at a high level across a series of applications. It includes the total calls, active tenants, overall availability including dependent systems, the availability excluding dependent systems, and the synthetic availability across just our continuous tests.

