Top 3 Data Science Applications for Cloud Infrastructure Operations
For nearly 20 years, Salesforce has been a pioneering force in the cloud software industry, enabling customers around the world to ditch costly on-premise enterprise software solutions for simple pay-as-you go SaaS platforms. The “no software” model has fueled tremendous customer success and, consequently, tremendous cloud infrastructure growth at Salesforce. To maintain customer trust and to support high availability for a variety of enterprise use cases, Salesforce has invested in data centers around the world. This infrastructure expansion provides fertile ground for developing and advancing impactful data science methodologies that directly improve business operations and impact the bottom line.
While cloud infrastructure data science is not covered in the media as broadly as facial recognition nor autonomous vehicles, it’s an amazing example of how the development of data science techniques within an enterprise can be integrated into daily business operations. Our core CRM application, and the infrastructure that supports it, generate a massive amount of critical internal data that can be leveraged to understand how our customers consume cloud infrastructure resources around the world. The Infrastructure Data Science team’s job is to wrangle this data firehose and implement internal data science applications that provide insights to drive operational excellence, infrastructure cost savings and increase platform security.
Salesforce’s cloud infrastructure is multi-tenant, with many customers sharing the same infrastructure resources. Our cloud architecture also consists of many system tiers (application, database, storage, etc). Both of these factors create a complex technology stack that requires careful modeling across millions of time series at various aggregations. To successfully scale insights and optimize our expanding infrastructure footprint, three main data science use cases stand out within the cloud infrastructure data science world:
[1] Anomaly/Event/Change Point Detection
[2] Time Series Forecasting
[3] Clustering
Our team has made great strides in integrating these data science techniques into internal applications that support business operations while we continue to adopt new data science technologies that streamline our team’s workflow. In the following sections, we provide a quick overview of these data science use cases and their importance for cloud infrastructure operations.
[1] Anomaly/Event/Change Point Detection
Much of the data we process and leverage for our use cases are infrastructure and performance time series. Metrics such as latency, CPU Utilization %, customer traffic, storage growth, active users, and network traffic are critical to monitor over time. The time series for these metrics are extremely complex and can be monitored on an infinite number of time granularities (every minute, five minutes, hour, day, etc.) and aggregations (mean, median, P90, max, etc.). The ability to programmatically detect and surface concerning patterns across hundreds of thousands of critical time series is important for many stakeholders within Salesforce. The figure below demonstrates many of the time series features that we detect and surface to appropriate stakeholders.

Depending on the metrics, the times series features highlighted above are used to measure impact of application release regressions, improve forecasting algorithms, inform capacity planning decisions, and alert performance engineering teams on important system changes. While these patterns are obvious by simple inspection, being able to detect anomalistic system behavior and trend changes across hundreds of thousands of time series is critical for capacity planning teams to ensure high availability of our products. The ability to detect and store these time series features provide the foundation of more advanced system insights, forecasts, and predictions.
[2] Time Series Forecasting
As mentioned above, much of the data we leverage is most useful as a time series. Similar to most internet applications, our infrastructure must support pronounced seasonality for all the use cases we support — CRM, Marketing, Commerce, and more — each with different seasonality patterns. CRM users largely produce demand on weekdays during business hours, whereas Marketing/Commerce Cloud customers produce high volumes of system traffic during holidays. Programmatically forecasting infrastructure demand and key system performance metrics with these complex time series characteristics is important for many internal teams we support at Salesforce. Below is an example of a complex time series that exhibits seasonality, trend, anomalies, and change points.
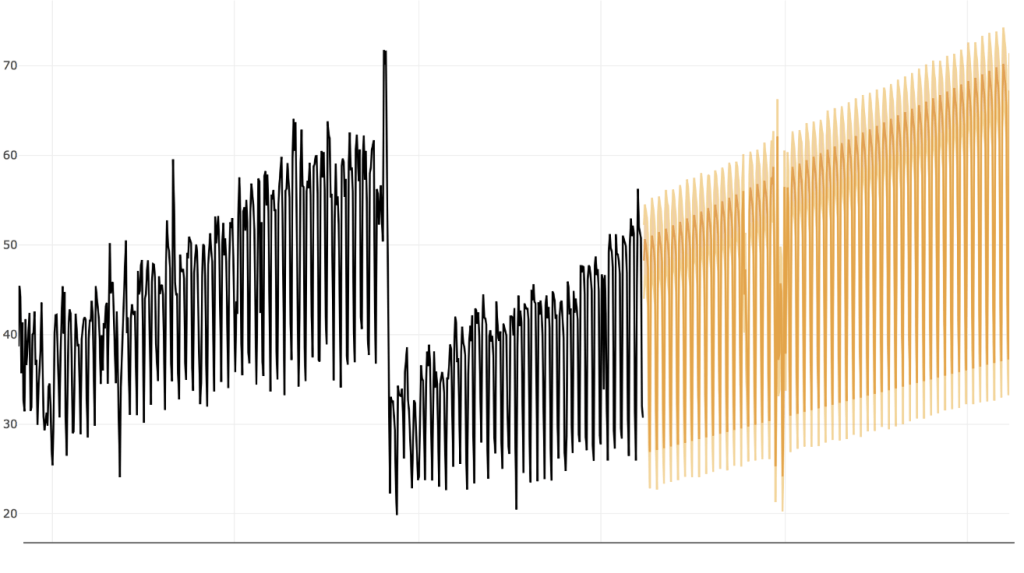
Developing algorithms to effective process and forecast massive numbers of time series is an important foundation for many of the internal applications that our team develops. The most obvious application of complex time series forecasting is for capacity planning, ensuring that we have right amount of capacity in the right place at the right time to support customer workloads. To algorithmically develop these time series, our team has created a forecasting package that removes outliers, detects change points, and performs optimal model selection. This forecasting package powers many internal use cases, which include calculating capacity time to live (TTL), producing individual customer demand forecasts, and powering many other complex time series forecasts.
[3] Clustering
Clustering also plays an important role in simplifying how we think about the hundreds of thousands of customers (and millions of users) that we support on our multi-tenant infrastructure everyday. As a platform, we enable our customers to develop heavily customized applications, which generate a wide variety of workload patterns on our infrastructure. For example, one customer might be extremely API heavy while another requires batch reporting workloads. The example below illustrates how our team might bucket customers into five workload clusters.
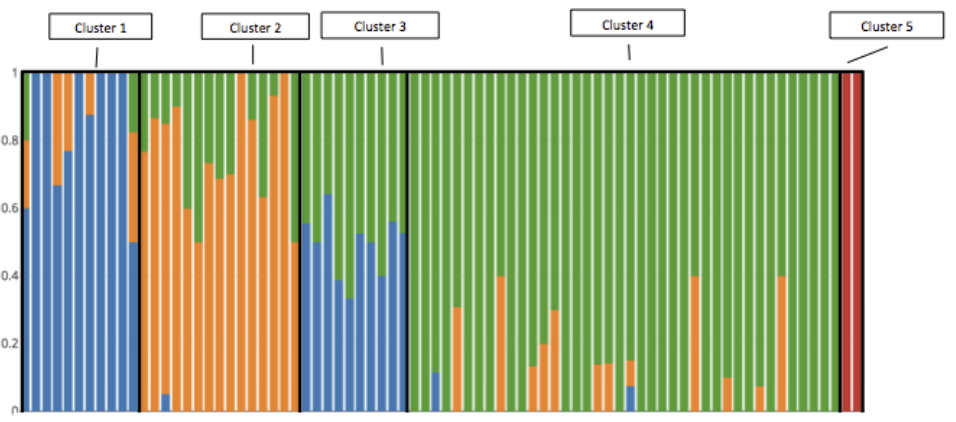
Quickly profiling various entities (customers, hardware systems, transaction types) based on a set of features informs many business decision related to infrastructure for stakeholders like customer centric engineering, finance strategy, and capacity optimization. Today, many of the clustering analyses are bespoke and tailored to support specific stakeholder requirements. However, our team plans to begin development of democratized customer clustering tools that allow business users to easily develop unique segmentations on their own. This will empower a growing number of internal stakeholders to better understand the wide array of customer implementations of the Salesforce cloud application.
The three data science use cases outlined above are currently in various stages of operationalized maturity, from fully automated internal data science applications to bespoke data science projects. However, our team continues to quickly iterate on tools, algorithms, and user feedback to ensure our internal applications are providing maximum value for cloud infrastructure decision makers at Salesforce. With the rapid infrastructure growth, comes the need to continually evaluate new data science methods to further provide intelligence at scale…stay tuned!
Huge shout out to the team for their amazing contributions!