
With APIs becoming more complex and distributed, developers sometimes struggle to find the relevant logs when they need to investigate a specific issue. In the new Salesforce Commerce APIs (SCAPI), we created such an architecture of distributed systems and recognized this problem early. Our approach to mitigate it was the introduction of a correlation ID.
This ID is a unique identifier of the API request across systems and is commonly used for these scenarios. It has proven to be very helpful for internal developers as well as external users.
This blog post describes how a correlation ID can be leveraged to easily find logs for further investigation.
A quick overview of the SCAPI ecosystem
In order to understand the necessity of a correlation ID, let’s have a look at the architecture in place.

- Every HTTP request to these new REST APIs initially comes in through the CDN layer. Among other things, this layer is responsible for routing the request to the correct instance of the API layer.
- The API layer (e.g. Mulesoft) acts as an API middleware or gateway with applications handling the API requests. During processing, a request is made to the Commerce Cloud backend.
- The Commerce Cloud backend consists of services that generate and return a response.
Each component has access to the monitoring layer where the log events are aggregated.
The benefit of a correlation ID
When looking at the architecture diagram above, we can spot a few issues that a developer might face. The applications on the API layer and the Commerce Cloud backend both process the request, which involves writing a number of events into their respective log files. Since this processing can result in errors in each of the systems, it is often necessary to look at the different files in order to understand where an issue is located.
This is why the CDN layer contains a module that injects the correlation ID into the request. Since every request passes through this layer, this is the perfect place to handle this task. Although the CDN system already provides a header to identify requests, it is not guaranteed to be unique for this purpose. As a consequence, the module generates a new UUID and sends it with the HTTP request header x-correlation-id.
For the same requirement of uniqueness, the correlation ID cannot be set by clients. Any existing value in the header x-correlation-id will be overwritten with the newly generated ID. However, clients are of course free to use their own identifiers for internal purposes by sending them in a different custom header.
After the injection of the correlation ID, the request is routed to the API layer. The name x-correlation-id is beneficial here. It is commonly used in descriptions of correlation IDs and is, therefore, a de-facto industry standard. By following this convention, the Mulesoft API layer automatically uses the value from this header for its log events without requiring any changes to the deployed applications.
Eventually, the request is sent to the Commerce Cloud backend, which writes the identifier into its log files as well. When the response is generated, the correlation ID is returned to the client as an HTTP response header.
Different use cases for the same tool
The correlation ID has considerable benefits for both internal and external use cases.
Internally, developers may need to track a request chain in order to identify the nature of a specific issue. Without the same request ID, correlating the individual transactions or events must be done with other properties like timestamps, client identifiers, or a combination of those. However, due to processing time, timestamps might slightly differ across systems. Also, different timezones could be configured and shown in the log events. This makes such investigations lengthy and cumbersome, especially when the request volume is very high.
Externally, clients might notice irregularities in their requests and ask Commerce Cloud Support for help and advice. Without supplying a correlation ID in the support case, the support team would have to take the same difficult steps described above. Instead, they can now use the correlation ID and query their monitoring systems for all relevant logs. This tremendously accelerates the issue resolution, hence increasing client satisfaction.
How does it work?
Let’s have a look at an example. We try to update a product via the Products API and get a response with the 500 Internal Server Error status code. This is a server-side error that should not expose implementation details like a stack trace in the response body. We need to inspect the logs to find the cause of it.
The header section that is returned with the response will look like this:
HTTP/2 500
date: Mon, 29 Nov 2021 11:47:05 GMT
content-type: application/json; charset=UTF-8
content-length: 177
strict-transport-security: max-age=31536000; includeSubdomains;
x-correlation-id: 002df95f-3e2b-4553-97ac-bc241a26d8caIt contains the correlation ID under x-correlation-id. This value can now be used to find the related log events.
For instance, the logs from the applications on the API layer and from the Commerce Cloud backend are pushed to the monitoring layer of Salesforce. Because the correlation ID is used in different fields across systems, a query needs to combine those with the value from the request:
index=commercecloud-secure "message.activity.external"=002df95f-3e2b-4553-97ac-bc241a26d8ca OR "@metadata.correlationId"=002df95f-3e2b-4553-97ac-bc241a26d8caRunning this query will show results from all involved systems:
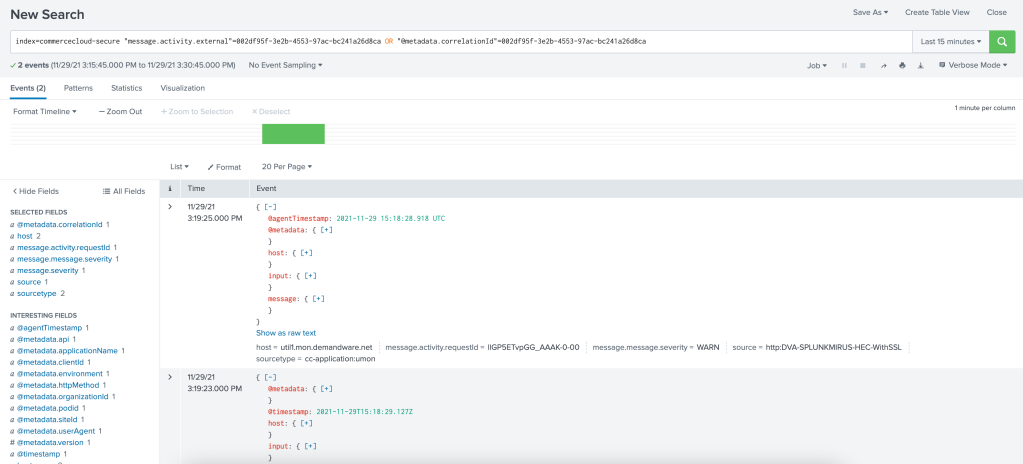
The field sourcetype shows two entries. The value cc-application:umon refers to the event on the Commerce Cloud backend, whereas cc.mercury:applogs is the event on the API layer.

Depending on the nature of the error, there could be more than two events. Opening an event will show the details to identify the cause:

Conclusion
As shown, the benefits of using a correlation ID are substantial. Keep in mind that the higher the number of connected systems is, the greater the value of such an identifier is. We encourage every reader to use the correlation ID as a tool in their own architecture. The effort of implementing it in new or existing systems is often justified by the help it provides.



