very business needs to process data in a way that satisfies the overall mission and vision. As customer interaction with businesses now involves high-speed networks and APIs, decision-making should happen not in days or hours, but in seconds at worst. That is why batch processing data pipelines are now being replaced with streaming ones.
Decision-making is at the core of many data pipelines. An anomaly detection can be as simple as checking a measurement against a threshold and taking manual actions to investigate that, or as complex as analyzing a behavior with respect to historical data and detecting the underlying cause automatically.
In our case, we managed to transform a batch-processed, rule-engine-based, and non-automated anomaly detection system into a stream-processed, ML-based (but with rule-engine support), and automated one. From a business perspective, we achieved a decrease in the mean time to detect a problem with its cause from days to minutes. In this post, we will discuss the details of the system we built.
Rule Engines and Machine Learning Models
If we analyze the spectrum of decision-making options, rule engines and machine learning models will sit at the opposite ends. The reason for this is tied to their opposing characteristics as detailed in the following table:

Combining the advantages of these two systems into a blended approach requires various techniques such as:
- Batching: In case the decision-making process requires lots of CPU cycles and/or the data exchange occurs via a network, it would be wise to execute the logic once per multiple requests.
- Communication Protocol: Not every protocol is suited for all cases. A binary and streaming communication mechanism would be suited for remote executions.
- Synchronous/Asynchronous: As the number of cores are increasing more and more in almost all computer systems, benefiting from parallel tasks greatly improves system utilization and customer experience.
- Scalability: Horizontal scalability is quickly becoming a norm given the complexity and high cost of vertical scaling. The basic idea is to place the decision-making components behind a load-balancer and adjusting the number of components with the demand.
Our Approach
In this section, we would like to go over our particular design of an anomaly detector that is meant to support quick and simple rules, as well as evolving and complex decisions.
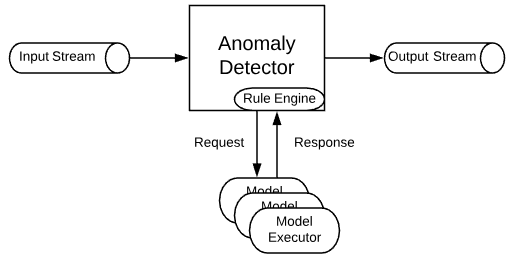
Rule Engine. A rule engine is a perfect fit for producing either true/false tested against a relatively simple condition. One example would be to test if CPU usage of a system is below 90%. Such a system could either be developed from scratch or be adapted from an open source/proprietary solution. We chose Apache Commons JEXL for this purpose. Apache Commons JEXL is an open-source implementation of the Java Expression Language. Unlike JBoss Drools or Groovy DSLs, Apache Commons JEXL is lightweight and interpreted, so it is an ideal rule engine. An overview of Apache Commons JEXL supported syntax is available at https://commons.apache.org/proper/commons-jexl/reference/syntax.html.
The following are features in Apache Commons JEXL supported by our anomaly detector
- Comments.
- Identifiers/Variables Access.
- Method Calls.
Machine Learning Models. Classifying a behavior into a category (such as anomalous or not) necessitates the analysis of historical data so as to create an evolving boundary between those categories. Instead of supporting a portion of the available machine learning models on the market, we developed a framework with plug and play support for the models. As long as a model can process an input and generates an output with predefined formats, the possibilities are endless. In our solution, we define the input and output schemas in JSON format. Batching, asynchronous execution, and gRPC communication support are all integrated to our framework for efficiency improvement.
No matter which type of anomaly detection component is preferred, the JSON schema we adapted for defining the component is the same:
{
"type": "object",
"title": "Anomaly Detector Policy",
"description": "A policy that specifies how a model should be served by the Anomaly Detector.",
"required": [
"model_name",
"model_doc",
"model_version",
"model_type",
"model_resource",
"model_configurations",
"target_metric",
"target_context"
],
"properties": {
"model_name": {
"$id": "#/properties/model_name",
"type": "string",
"title": "Model Name",
"description": "The name of the model for archival and debugging purposes.",
"examples": [
"62_us_ept"
]
},
"model_doc": {
"$id": "#/properties/model_doc",
"type": "string",
"title": "Model Documentation",
"description": "The documentation of the model for archival and debugging purposes.",
"examples": [
"N/A"
]
},
"model_version": {
"$id": "#/properties/model_version",
"type": "string",
"title": "Model Version",
"description": "The version of the model for archival and debugging purposes.",
"examples": [
"0.1.0"
]
},
"model_type": {
"$id": "#/properties/model_type",
"type": "string",
"title": "Model Type",
"description": "The type of model with which the Anomaly Detector must interface to serve the model.",
"examples": [
"rule"
]
},
"model_resource": {
"$id": "#/properties/model_resource",
"type": "string",
"title": "Model Resource",
"description": "An arbitrary string by which the Anomaly Detector resolves the actual model to serve.",
"examples": [
"m['ailtn.ept'] > 40"
]
},
"model_configurations": {
"$id": "#/properties/model_configurations",
"type": "object",
"title": "Model Configurations",
"description": "The configurations of the model with which the Anomaly Detector must use to configure the model."
},
"target_metric": {
"$id": "#/properties/target_metric",
"type": "string",
"title": "Target Metric",
"description": "The fully-derived metric name for which the Anomaly Detector must serve the model.",
"examples": [
"ailtn.ept"
]
},
"target_context": {
"$id": "#/properties/target_context",
"type": "object",
"title": "The Target_context Schema",
"description": "The context by which the Anomaly Detector must decide whether to serve the model."
}
}
}
This JSON schema can be used to validate Anomaly Detector Policies which were automatically generated or manually curated by using any JSON Schema validator implementation: https://json-schema.org/implementations.html.
For ease of viewing, the key information of this JSON schema is provided below.
- model_name — The name of the model for archival and debugging purposes.
- model_doc — The documentation of the model for archival and debugging purposes.
- model_version — The version of the model for archival and debugging purposes.
- model_type — The type of model with which the Anomaly Detector must interface to serve the model.
- model_resource — An arbitrary string by which the Anomaly Detector resolves the actual model to serve.
- model_configurations — The configurations of the model with which the Anomaly Detector must use to configure the model.
- target_metric — The fully-derived metric name for which the Anomaly Detector must serve the model.
- target_context — The context by which the Anomaly Detector must decide whether to serve the model.
Lessons Learned
- Fault tolerance and performance measurement. To avoid deteriorating customer experience and forming a huge pile of delayed requests, any automated decision making should be done within an enforced time boundary. A flexible and detailed performance measurement system should be capable of tracking response time metrics and supporting a fallback mechanism to ensure that errors are logged appropriately and other customers are unaffected
- Onboarding challenges of data scientists. Data scientists should be provided with clear and concise instructions about how to create and update their models to be consumable by the overall system. As the decision-making process lies at the heart of the system, crucial steps such as deployment, debugging, and monitoring processes should be well-established, tested, and automated.
- A/B testing support. No single strategy is perfect and the endeavor of looking for the best is an endless journey. Even if a rule engine or a machine learning model performs outstanding today, there is no guarantee that the same success will be achieved tomorrow or another one will not outperform. Being able to execute multiple strategies and aggregating the performance metrics of each will be invaluable to find the most promising one. Moving one step forward, a decision might be based on a weighted average of multiple strategies as well to balance the strength and weakness of each.
- Feedback loop. Either rule-based or machine-learning-based, customers need to have a way for rating the decisions made by the system. In return, the relevant component will benefit from this feedback by adapting its strategy. Similar to a living organism, the system will evolve as the definition of being normal changes.
Summary
Data-processing pipelines can have comprehensive reasoning capabilities with the help of machine learning models. Varying characteristics of these two major actors present a big challenge during integration but the benefits definitely outweigh the difficulties.
Note: this work was completed by Jacob Park.