In our “Engineering Energizers” Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we meet Nilesh Salpe, a key engineer developing Salesforce’s AI Metadata Service (AIMS), which provides tenant-specific configuration for AI inferences across Salesforce for AI applications like Agentforce via AI Gateway service (a centralized service to serve AI requests).
Discover how Nilesh’s team designed a multi-layered caching system to eliminate a 400ms latency bottleneck, protected AI inference from backend outages, and balanced data freshness with resilience, achieving sub-millisecond performance without impacting downstream client teams.
What is your team’s core mission within Salesforce’s AI infrastructure, and what systems depend on the AI Metadata Service?
The team delivers highly available, scalable infrastructure to power AI workflows. This includes services like model management, orchestration, and the AIMS, which stores tenant-specific configuration for every AI inference. Given Salesforce’s multi-cloud, multi-tenant architecture, each tenant might use different providers, such as OpenAI (ChatGPT) or Salesforce-hosted internal models, with unique tuning parameters. These details are crucial for every inference call.
All AI (including Agentforce) traffic passes via AI Gateway service through the AIMS to fetch the necessary metadata. Without this service, these systems would not know how to route requests or apply tenant-specific context. Although these configurations rarely change, they are essential for every call, making the service a critical dependency in the AI stack. The service’s latency and availability directly affect the end-user experience.
Our goal is to abstract complexity, reduce operational overhead, and enable AI teams to deploy seamlessly in a fast-evolving ecosystem.
What performance and reliability bottlenecks forced your team to reduce AI inference latency at scale?
Our team faced significant performance and reliability bottlenecks in the AI inference request flow, primarily due to how metadata was retrieved. Each inference request required fetching configuration and metadata from the AIMS, which depended heavily on a shared backend database and multiple downstream services like the CDP Admin Service.
This design introduced multiple issues:
- High Latency: Metadata retrieval contributed ~400 ms P90 latency per request, significantly impacting the overall end-to-end latency, which reached 15,000 ms P90.
- Noisy Neighbor Problem: AIMS shared its database with the other CDP services, leading to resource contention. High usage by other services often degraded AIMS performance.
- Reliability Risks: The system had a single point of failure — if the database degraded, restarted, or was under vertical scaling operations, all inference requests were impacted. In some scenarios, this could even lead to full service outages.
- Inefficient Design: Despite metadata being largely static, it was retrieved on every inference call, making the system inefficient and fragile under scale.
To overcome these challenges, we implemented caching at multiple levels:
- A local cache in the AIMS Client (AI Gateway) for immediate access to metadata.
- A service-level cache within the AIMS to avoid unnecessary database and downstream service calls.
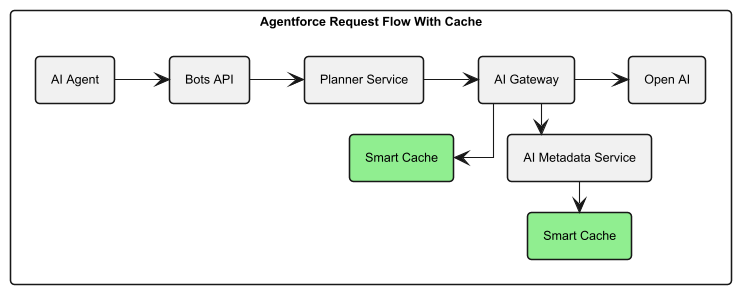
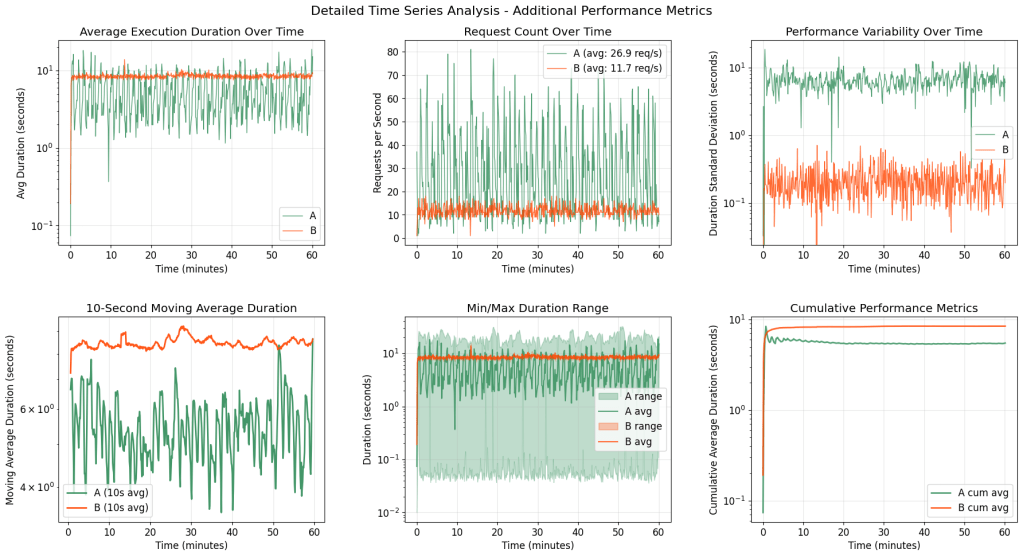
End-to-End Agentforce request flow (green boxes indicate SmartCache layers)
Because metadata changes infrequently, caching proved to be a highly effective strategy. Once caches were warmed:
- Metadata access latency dropped from 400 ms to just a few milliseconds
- End-to-end request latency improved from 15,000 ms to 11,000 ms P90 — a 27% reduction
- System reliability improved by removing the critical dependency on real-time AIMS reads for every inference
This multi-layer caching approach not only reduced latency at scale but also minimized system fragility, improved cost-efficiency, and eliminated a major single point of failure in our inference pipeline.
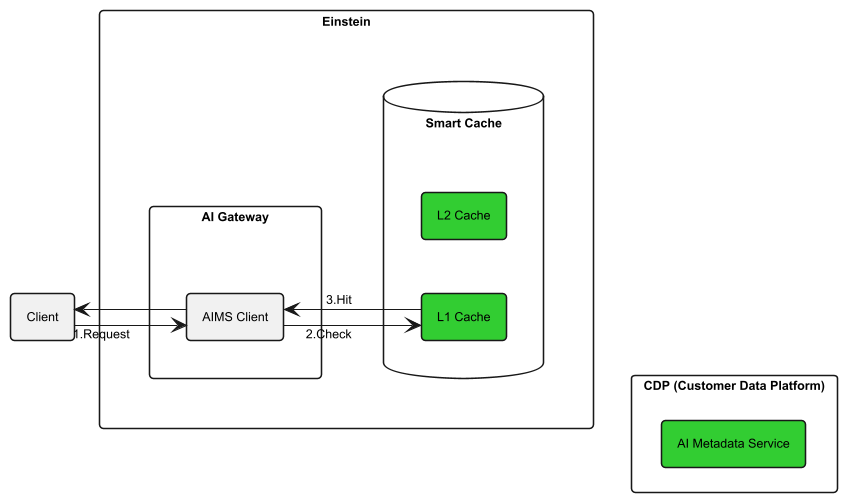
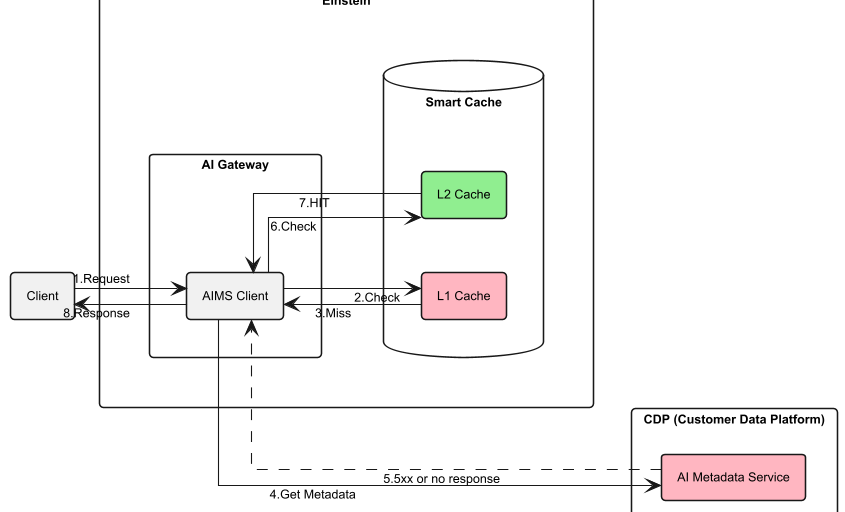
Low-latency scenario: AIMS Client L1 cache serving metadata.

Availability scenario: L2 Cache ensures continuity during AIMS outage for AIMS client.
What system reliability issues led to the design of a second caching layer for Salesforce’s AI Metadata Service?
A major production incident revealed a critical reliability gap in our architecture. During a database outage — caused by resource exhaustion (CPU, RAM, IOPS, disk space, and connection limits) — metadata fetches across the AI platform were disrupted for ~ 30 minutes, halting inference workflows and highlighting that latency wasn’t the only concern; resilience was equally critical.
Our backend database, which is shared with other systems, was vulnerable to unpredictable load, “noisy neighbor” effects, and other degradation triggers such as:
- Region or data center-level failures
- Failovers during upgrades or maintenance
- Poorly optimized queries, unoptimized schemas, deadlocks etc
While our existing L1 cache handled low-latency responses, it wasn’t sufficient to maintain continuity during full service or database outages.
To close this resilience gap, we introduced an L2 cache — designed to store longer-lived metadata and configuration data. Since most configurations change infrequently, the L2 cache could safely serve stale but valid responses during backend failures, ensuring inference flows remained functional without client-side impact.
This approach enabled graceful degradation, turning what could have been a outage into uninterrupted service and significantly improving the reliability of our AI platform.
What caching tradeoffs did your team face when balancing latency, data freshness, and AI system resilience?
Our biggest challenge was balancing data freshness with fault tolerance. Model preferences might remain static for weeks, but trust attributes can update frequently, making a one-size-fits-all cache TTL too risky.
To address this, we made TTLs configurable per use case. Clients could set expiration windows for both L1 and L2 caches based on their tolerance for stale data, preserving flexibility while protecting core behaviors.
Another risk was serving outdated data during extended outages. We mitigated this by implementing background refresh logic and observability hooks. These features allowed us to monitor cache age, invalidate stale entries, and pre-warm caches.
To ensure consistent behavior across services, we standardized on Salesforce’s Scone framework. We introduced SmartCacheable (reactive and non-reactive) annotations, enabling teams to adopt caching without writing custom logic. This streamlined adoption and enforced shared guardrails for consistency and expiry.
What specific latency improvements did you achieve with smart caching — and how did you validate those gains across services like AI Gateway?
Client side caching slashed configuration fetch latency by over 98%. Before the change, each call added about 400ms. Post-rollout, the client-side L1 cache reduced this to sub-millisecond, and the server-side L2 cache responded in just 15ms when L1 expired. This significantly boosted performance across all inference paths.
For services like AI applications and Agentforce, where AI calls are chained, faster metadata lookups led to quicker agent responses and enhanced overall responsiveness.
To measure the impact, we implemented end-to-end telemetry. Metrics now track L1 and L2 hit ratios, latency buckets, and downstream performance. Alerts are triggered if cache usage patterns shift, such as a sudden increase in L2 usage, which could indicate backend issues.
Collaborating with the performance team, we integrated these metrics and observed clear reductions in response times and service-wide improvements in responsiveness. Caching not only reduced latency but also ensured AI workflows operated at their intended speed.
How has system availability improved since deploying the second cache layer — and what failure scenarios are you now able to prevent?
After implementing the L2 cache, system availability improved to 65% even during full backend outages, such as database failures that would have previously resulted in a complete service disruption. The L2 cache now acts as a resilience buffer, allowing AI inference calls to continue running smoothly by serving safe, cached responses. Without this layer, a database failure would have completely halted inference flow

How L2 cache protected AIMS during database outage.
Proactive alerting has also been integrated: if services shift to L2 cache usage, a PagerDuty alert is triggered, signaling potential issues in the service or DB layer before these become critical. This shift from reactive to preventative operations has been game-changing.
All behavior is tracked in centralized dashboards, including L1 vs L2 usage, cache expiration patterns, stale data thresholds, and incident saves. These metrics demonstrate how caching has enhanced resilience and prevented user-facing issues.

Availability maintained via L2 cache hits during outage window.
For instance, during a recent database connection timeout, both the AIMS and the customer-facing Agentforce service remained stable thanks to the L2 cache. The database team was alerted, infrastructure was scaled up, and the issue was resolved without any customer impact. This kind of operational resilience is now a core part of the system architecture.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.