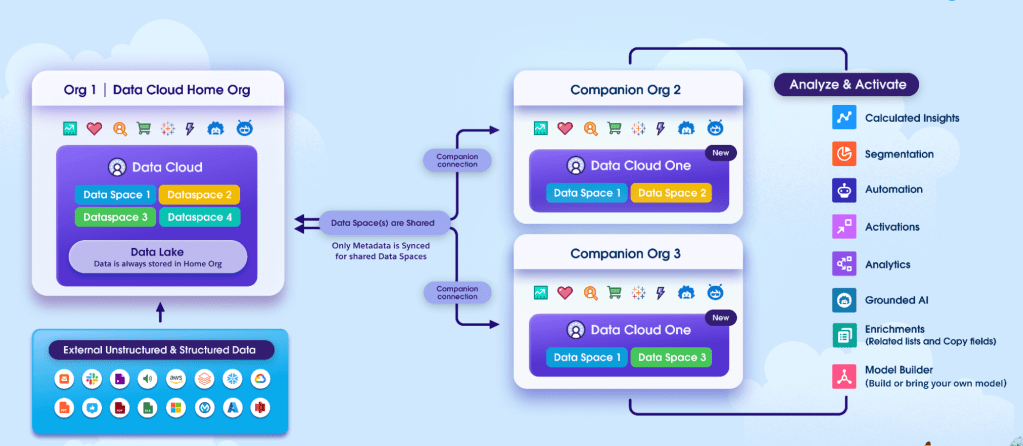
By Geeta Singh and Sai Bhava Teja Chinnangolla.
In our “Engineering Energizers” Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we feature Geeta Singh, Senior Manager of Software Engineering for Data 360. Geeta and her Data Actions team have developed vector search capabilities that transform unstructured data — such as documents, audio, and video files, which make up 80 to 90 percent of enterprise data—into actionable intelligence in near real-time.
Explore how they achieved a 51-fold reduction in costs by leveraging GPU acceleration, addressed Kafka throughput bottlenecks through top-k parameter optimization, and accelerated their development cycle by 60% using AI tools like Cursor, Claude, and Gemini.
What is your team’s mission building vector search in data actions for Data 360?
Our mission is to build a critical near real-time action layer for up to 90 percent of organizational data that has historically remained passive and unactionable. Organizations have vast amounts of unstructured data, including PDFs, presentations, meeting notes, contracts, and diagnostic reports etc. This data often sits passively in repositories, failing to generate triggers or enable business process automation. Unlocking its potential is no longer optional — it’s a competitive necessity.
Enterprise teams rely on powerful tools like Salesforce Flows, but these tools require triggers to function effectively. While significant innovation in Data 360 has focused on generative AI and Agentforce, these capabilities are primarily on-demand. Our goal is to bridge this gap by enabling proactive action on changes happening in unstructured data in near real-time, rather than waiting for users to initiate queries.
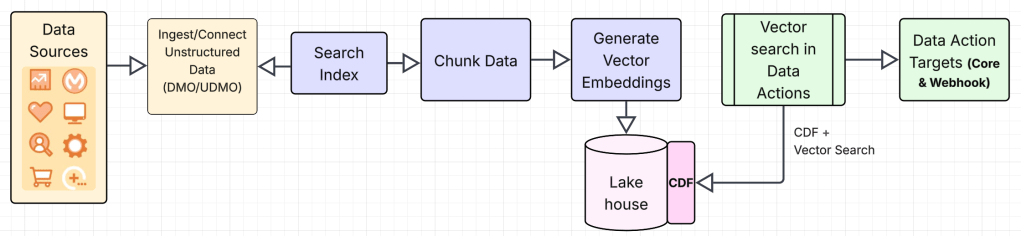
Vector Search in Data Actions: High Level View
What GPU acceleration challenges did your team face when indexing and analyzing terabytes of unstructured documents, audio, and video files at enterprise scale?
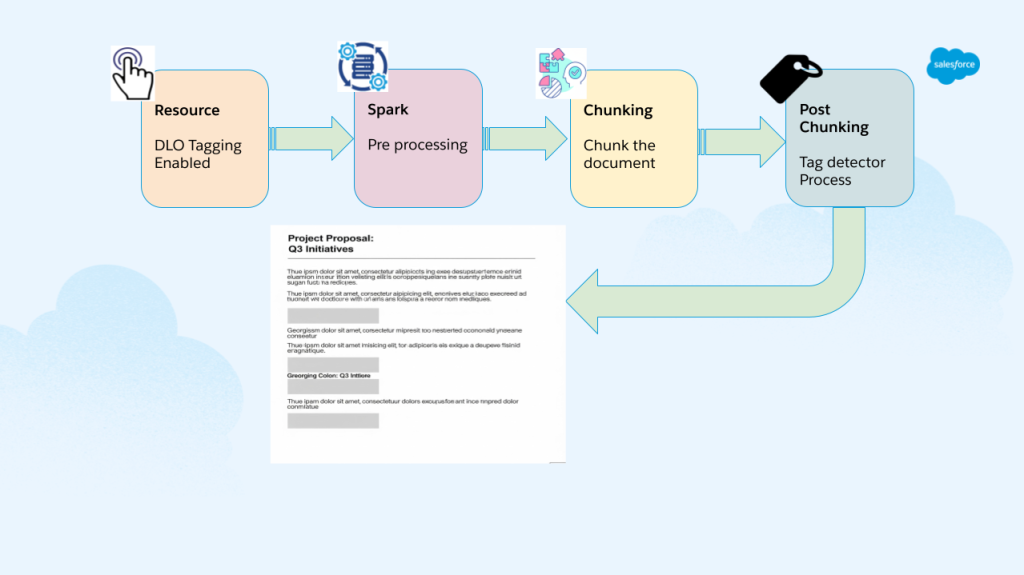
The primary challenge was moving beyond text documents to support process compute-intensive media files like audio and video files. Previously, Search Index only supported text-based documents like PDFs and presentations. Extending to media formats required a fundamentally different infrastructure. Behind the scenes, Search Index used Spark jobs that were strictly CPU-based, which proved extremely slow when processing audio and video files that required large transcription models to extract text.
To address this, we integrated GPU acceleration directly into the Spark environment using EMR on EKS and EC2 instances. The vectorization pipeline leverages Whisper models for audio transcription and E5 large models, SFR and Clop models for generating embeddings, with GPU acceleration being essential for handling these computationally intensive ML workloads. The results were dramatic:
- Transcription costs were reduced by 51 times compared to CPU processing.
- Analyzing 2.4 million vector embedding records from 10,000 documents and generating vector search results took under two minutes.
This performance leap was crucial because each input file can result in thousands of records. During performance testing, the Spark jobs maintained our committed P99 latency, even with the massive volume increase from single documents being broken down into millions of chunks requiring individual analysis.
What latency and performance bottlenecks emerged when delivering near real-time data actions on vectorized content across millions of document chunks?
The architecture faced a fundamental bottleneck: Kafka topics have a two-megabytes-per-second throughput limit. Vector search in Data Actions triggers an event for each input document, with payloads including detailed results like relevant document sections and their content. For example, in an audio conversation, the payload contains timestamps and transcript segments where keywords appear.
Each event payload can grow significantly, risking Kafka’s throughput limits when multiple events are produced simultaneously. To address this, we implemented:
- Top-k Parameter: Customers can specify interest in only the top 10 most relevant highest-scoring chunks in document references, reducing payload size
- Retry Mechanisms: Automatic retry logic handles temporary throughput constraints.
These optimizations ensure that only the most relevant information is transmitted, keeping throughput within limits while maintaining our SLA of near real-time delivery.

Sample Event Payload
What use case diversity challenges did your team overcome supporting real-time document processing across multiple industries?
The team faced the challenge of building a flexible architecture to handle diverse document types and use cases across industries without fragmenting the codebase. Each industry has unique document formats and extraction needs: real estate firms analyze house inspection reports for toxic materials, energy companies extract scorecards from RFP (request for proposal) documents, financial services parse CIBIL reports for credit scores and loan eligibility, and insurance companies process Docusign contracts for signing status.
To address this, we created a common document schema i.e. specific schema of DMOs (Data Model Objects) that the Search Index transforms all input types into, whether PDF, audio, or video enabling standardized output. This unified approach allows Data Actions to work seamlessly without handling format-specific logic for each industry.
We also exposed Connect APIs, enabling different clouds to programmatically configure the entire pipeline, including the data action, and data action target. Once an event is consumed, developers can use Apex and Prompt templates to orchestrate any downstream logic, making the solution extremely configurable for varied use cases. This allows Service Cloud, Revenue Cloud, and Industries Cloud to integrate vector search capabilities and trigger downstream business workflows without custom implementations for each use case.
How did AI development tools help improve development velocity and productivity?
The team faced major challenges in developing both the user interface and backend analysis within a single release cycle. Initially, we considered building standalone interfaces but opted to integrate natively within Salesforce Flows, which usually requires navigating a large, monolithic codebase that can take weeks or months to update. To speed things up, we used hybrid AI-assisted development strategy in several ways:
- Claude accelerated UI development, cutting the time from one to two months down to just two weeks.
- Cursor generated test automation scripts, unit tests, and functional tests, reducing a three-week task to just four days. Unit test generation became fully automated, with developers only needing to review the tests. Cursor also recommended specific packages over others due to security vulnerabilities, helping us proactively identify and address security issues.
- The team developed shared prompt rules to handle common AI hallucinations, ensuring these rules were automatically included in subsequent prompts.
- Gemini speed up documentation work, including release notes, customer-facing documents, and production runbooks, which now take hours instead of days.
These tools significantly improved our development velocity and efficiency.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.