By Padma Aradhyula, Dongwei Feng, Siddharth Sharma, and Anuja Gore.
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we spotlight Padma Aradhyula, Senior Director of Software Engineering on the Data 360 Compute Fabric team, who manages a large-scale platform orchestrating four million Spark applications daily, with nearly 2 million of them on Kubernetes.
Explore how Padma’s team optimized infrastructure cost at global scale by evolving Kubernetes scheduler behavior to eliminate node fragmentation under bursty Spark workloads, redesigning placement logic to proactively consolidate executor pods onto fewer nodes and embedding efficiency directly into the scheduling layer to resolve the reliability tension created by reactive autoscaler-driven node churn.
What is your team’s mission in building and operating the Data 360 Compute Fabric platform at Salesforce scale?
Our mission is to provide a resilient, hyper-scale compute foundation that powers the entire Data 360 lifecycle — from ingestion and modeling to activation. By abstracting the complexities of massive-scale distributed processing, we enable a unified ELT-first approach that eliminates fragmented point solutions and provides high data availability across batch and streaming workloads.
To meet Salesforce’s rigorous data freshness guarantees, our team orchestrates millions of Spark jobs daily, processing petabytes of data across global Kubernetes fleets. At this magnitude, we view operational reliability and Cost-to-Serve (CTS) as a single, inseparable objective.
Scaling successfully means ensuring that efficiency never comes at the cost of stability. As part of a broader suite of infrastructure initiatives, we’ve recently prioritized intelligent resource placement and high-density bin-packing. This ensures we maximize utilization while maintaining the “five-nines” reliability required for our customers’ most critical data workloads.
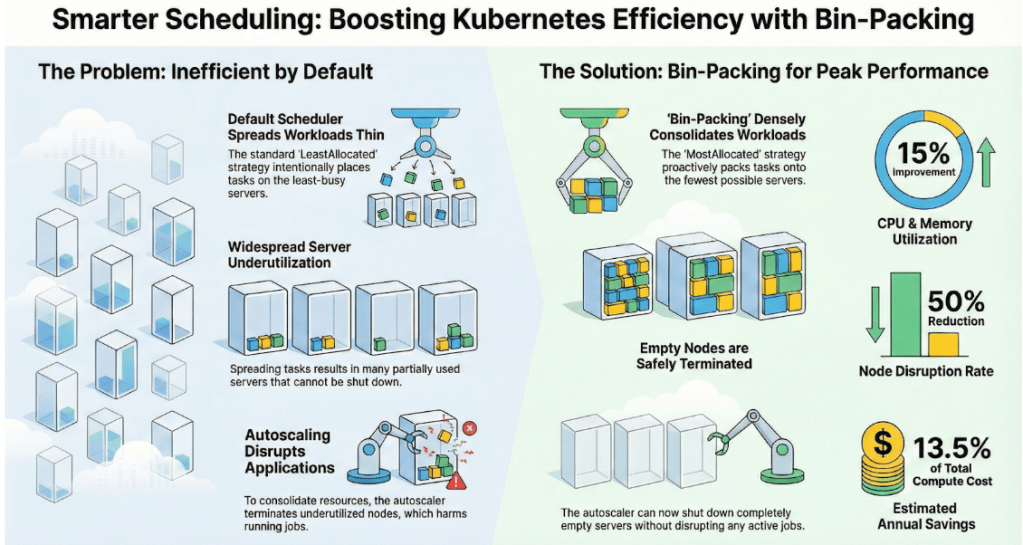
What architectural bottlenecks in the default Kubernetes scheduler placement logic led to node fragmentation and sub-optimal bin-packing for bursty Spark applications?
The primary architectural bottleneck stems from the default kube-scheduler scoring strategy, specifically LeastAllocated. While ideal for persistent microservices where high availability is prioritized through “spreading” (to minimize blast radius), this logic fails in a high-scale Spark environment for three core reasons:
1. Anti-Pattern: The “Scatter” Effect
By default, the scheduler seeks out nodes with the most free resources. In a bursty environment, when a large Spark job requests 100+ executors, the scheduler spreads them across the widest possible footprint. When these executors terminate — often non-deterministically due to Spark’s Dynamic Resource Allocation (DRA) — they leave behind nodes with 90% idle capacity but 10% active pods.
2. The Reactive Autoscaler Conflict (Karpenter)
To solve the idle capacity issue, we enabled Karpenter to consolidate the nodes. While Karpenter’s consolidation logic eventually attempts to “defrag” the cluster by moving pods, this is a reactive process. For Spark, this is often fatal; moving an executor means killing a running task, leading to job retries, extended runtimes, and stage failures. Hence, we had to tune down the consolidation thresholds to minimize pod disruption.
3. Lack of Workload Awareness
The default scheduler treats every pod as an independent unit. For example, it lacks the application awareness to recognize that 500 Spark pods belong to the same job and should ideally be co-located on the fewest possible nodes to facilitate efficient node reclamation once the job completes.
Padma highlights her team’s research projects.
What trade-offs emerged when autoscaler-driven consolidation was used to reclaim underutilized Kubernetes nodes for Spark workloads?
Using autoscaler-driven consolidation (like Karpenter’s) to reclaim fragmented capacity creates a direct conflict between CTS and job-level SLA stability. While consolidation identifies underutilized nodes, it relies on reactive eviction — terminating nodes and forcing active Spark executors to move.
These disruptions are particularly “expensive” for Spark. Evicting an executor mid-stage triggers task retries and the loss of local shuffle data, which can lead to cascading delays and extended job runtimes. We found that the compute cost of re-running failed stages often offset the 10%–15% gains in raw utilization.
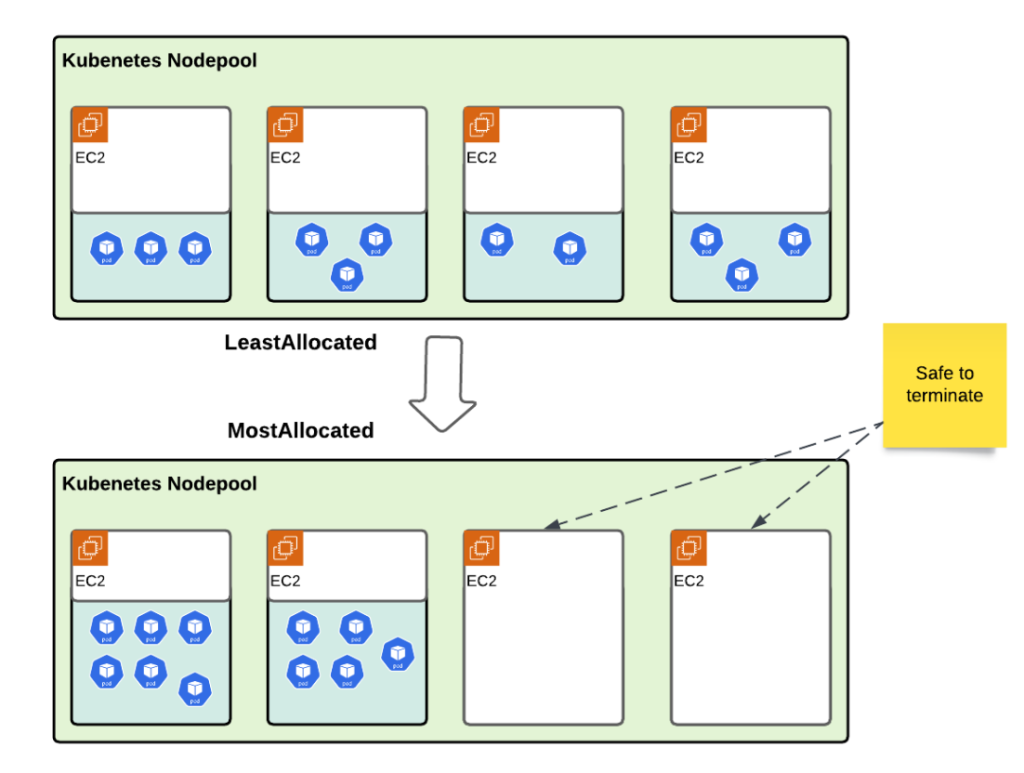
How was the Kubernetes custom scheduler redesigned to implement proactive, high-density bin-packing as a first-order placement primitive for Spark workloads?
Our team solved the above mentioned challenges with a default Kubernetes scheduler and Karpenter node consolidation, moving to a density-focused placement strategy. We introduced a custom scheduler that uses a MostAllocated approach to pack executors onto utilized nodes. This change eliminates fragmentation at the start and ensures the cluster behaves efficiently during workload spikes.
The transition to proactive bin-packing required a fundamental shift in the scheduler’s filtering and scoring phases. Our design prioritized “filling” existing nodes to their resource limits before allowing the provisioner to spin up new capacity.
To achieve this, the compute fabric team adopted the MostAllocated scoring strategy through the NodeResourcesFit plugin. This logic assigns the highest score to nodes that are already running workloads but still have available headroom. By “stacking” new Spark executors onto these nodes, we maximize the utilization of already-paid-for compute.
What validation challenges did the team address to ensure Kubernetes bin-packing improved efficiency without increasing workload disruption at scale?
The team monitored millions of daily Spark jobs to ensure higher utilization did not compromise stability. Results from the production rollout confirmed that the bin-packing scheduler improved resource efficiency while maintaining performance.
CPU and memory utilization rose by roughly 15% as workloads packed more densely onto active nodes. This shift led to a 13% reduction in compute infrastructure costs. These savings represent a significant impact on the annual budget for the Data 360 platform.
Reliability also improved during this transition. Autoscaling now terminates empty nodes instead of evicting active ones, which cut EC2 node disruption rates by 50%. Spark applications now benefit from fewer executor losses and more predictable runtimes. Proactive scheduling secures both cost efficiency and operational stability.
Padma shares what keeps her at Salesforce.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.