
In our “Engineering Energizers” Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we feature Raghav Tanaji, a key member of the Model Serving team. Raghav and his team are revolutionizing generative AI at scale by integrating with Amazon Bedrock CMI, which simplifies infrastructure and accelerates model deployment.
Explore how they tackled long GPU onboarding delays, seamlessly integrated Bedrock without disrupting existing systems, and addressed critical reliability and security issues. Their efforts have reduced onboarding time by 75% and significantly boosted developer productivity with tools like Cursor.
What is the team’s mission — and how has generative AI reshaped priorities across model serving and infrastructure?
The Model Serving team drives the scalable, efficient, and reliable deployment of generative AI models for serving both internal teams and open-source foundational models. The primary mission is to abstract infrastructure complexity while supporting a diverse array of model types, including large language models (LLMs), multimodal, speech, and computer vision models. This platform ensures internal teams can focus on experimentation and delivery without the burden of determining the optimized inference software stack, capacity planning, hardware provisioning, or deployment logistics.
The rise of generative AI has transformed priorities in three significant ways. First, the variety and size of models requiring support have expanded, leading to the need for more custom and instruction-aligned LLM variants. Second, the demand for rapid iteration and lower latency across internal use cases has increased. Third, the standards for reliability and observability have been elevated. Currently, the platform serves 19 models across multiple environments, utilizing flexible routing and a shared abstraction layer that dynamically switches between hosting backends such as SageMaker and Bedrock.
What was the most painful bottleneck in onboarding custom models — and how did it slow down internal teams?
Prior to adopting Bedrock CMI, the process of onboarding models into production was a lengthy and cumbersome affair, often stretching over several weeks. Infrastructure bottlenecks and organizational inefficiencies were major hurdles. One of the most critical issues was the availability of GPU instances, especially for high-demand models like A100s and H100s. Securing the required capacity involved extensive planning cycles, with input from various stakeholders, ranging from SVPs to individual engineers. These planning sessions frequently had to consider worst-case traffic scenarios, resulting in expensive over-provisioning and underutilised resources.
Even once capacity was secured, teams faced the challenge of configuring instance types, container runtimes, and performance settings. Validation required multiple stages of benchmarking to meet stringent SLA targets, often adding several more weeks to the process. This significantly hindered experimentation and slowed developer velocity. On average, onboarding a model took six to eight weeks, which delayed feature timelines and discouraged teams from exploring smaller or more experimental AI projects.

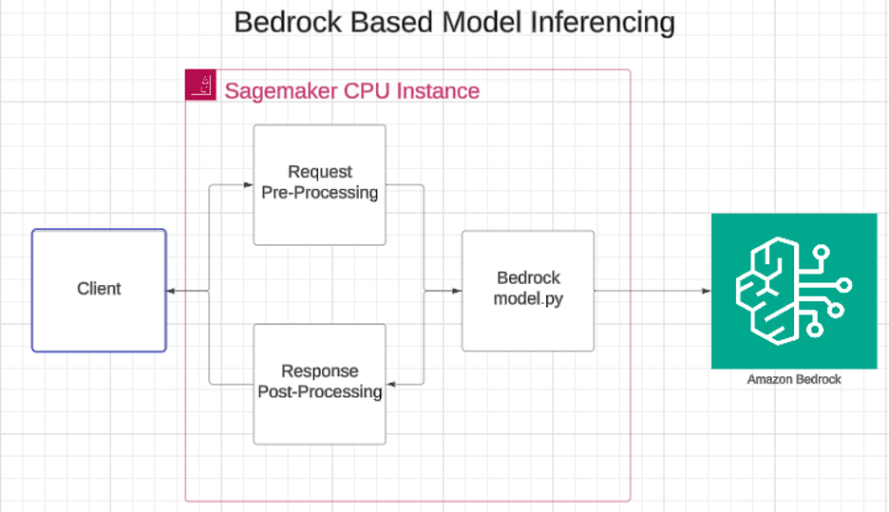
A look at Bedrock-based CMI inferencing.
How did Bedrock CMI help cut onboarding time and what changed in the deployment workflow?
Bedrock CMI streamlined model onboarding by eliminating infrastructure friction. As a fully managed, serverless platform, Bedrock removes the need to provision or tune GPU instances, reducing manual steps and speeding up production deployment. It also simplifies capacity planning and instance allocation, as model weights are uploaded directly to Bedrock, and the serving infrastructure is handled transparently.
This has cut onboarding time from six to eight weeks to just one to two weeks — a 75% reduction. Developer velocity has improved, allowing internal teams to test models earlier, discard underperforming ideas quickly, and integrate AI-powered features with minimal delay.
What technical hurdles were faced integrating Bedrock CMI into the existing stack — and how was architectural stability preserved?
Integrating Bedrock CMI into the model serving architecture demanded meticulous planning to ensure backward compatibility and prevent disruptions to existing prediction workflows. Internal product teams needed seamless access to models, regardless of whether those models were hosted on SageMaker or Bedrock.
To meet this requirement, SageMaker was configured as a thin pre/post-processing layer that forwards requests to Bedrock. One of the biggest technical hurdles in adopting Bedrock CMI is that it does not yet support executing custom pre- and post-processing logic natively. Previously, with the SageMaker approach, pre and post-processing were bundled inside the same container as the model weights, which often complicated integration and made performance tuning and debugging more difficult. To overcome this limitation, we now run pre- and post-processing separately on cost-effective CPU-based instances, such as ml.c6.xlarge, which handle tasks like token augmentation, custom data transformations, and response formatting. The additional network hop adds very minimal latency because both the SageMaker endpoint and the Bedrock CMI model are deployed within the same VPC, ensuring traffic remains internal and secure. The use of these inexpensive and readily available instances has provided both flexibility and cost savings. However, it’s important to note that Bedrock CMI still supports only certain model architectures, such as LLaMA and Mistral, and does not yet allow hosting of fully custom models with unique architectures or tokenizers, which remains a key consideration in our adoption plannings.
A key hurdle was Bedrock CMI’s initial lack of support for Qwen’s model architecture and custom tokenizer, which delayed our adoption of Salesforce Research models. Overcoming this required close collaboration with AWS. However, Bedrock CMI’s architectural support is steadily maturing, which should eventually allow most models to migrate to this framework.
Furthermore, Bedrock CMI was seamlessly integrated into the GitOps-based HAR deployer pipeline. This integration allowed internal teams to deploy Bedrock-hosted models using the same workflows already in place, ensuring a smooth and disruption-free process. The prediction service remained unchanged, and the system retained the ability to dynamically switch between SageMaker and Bedrock hosting.
What reliability, observability, or security gaps needed to be closed to trust Bedrock in production?
Before deploying Bedrock CMI in production, the team validated it against internal standards for security, reliability, and observability. One initial challenge was cross-account access—Bedrock lacked support for securely pulling model weights and metadata from Salesforce’s internal S3 model store. By collaborating closely with AWS, the team implemented scoped, temporary access that aligned with Salesforce’s IAM-based security model.
Another key concern was scaling behavior. The team conducted extensive tests to ensure Bedrock could scale from zero to multiple model copies without throttling or latency issues. Based on these tests, they provided AWS with recommendations to reduce cold-start impact.
To ensure reliability, Bedrock was integrated with Salesforce’s observability stack, including automated smoke testing via the Prediction Service and real-time metrics streaming into Grafana and Splunk. Error handling with retry logic was also implemented to gracefully recover from transient failures. These improvements ensured that Bedrock CMI met the high reliability standards required for production use.
How is the team using AI tools and infrastructure to be more productive and reduce operational overhead?
Bedrock CMI has dramatically increased the productivity of the Model Serving team by handling many infrastructure tasks. Since Bedrock is serverless and fully managed, the team no longer needs to deal with instance provisioning, scaling policies, or GPU lifecycle operations. This has eliminated the organizational overhead of GPU quota planning, which used to involve SVPs, VPs, and engineers. With Bedrock, these planning processes are no longer required, freeing up valuable time for experimentation and faster delivery.
Additionally, AI-powered tools like Cursor fine-tune inference configurations to optimize model performance. Cursor analyzes logs and runtime telemetry, suggesting targeted changes for batch sizes, token streaming, and concurrency limits. While valuable for manual tuning in environments like SageMaker, Bedrock simplifies deployment, automating many performance optimizations. For instance, migrating models such as ApexGuru to Bedrock the team observed a 50% reduction in latency and a 4× improvement in throughput. These results clearly show how AI infrastructure tools can significantly enhance engineering efficiency.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.



