In the “Engineering Energizers” Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we feature Manoj Vaitla, a senior engineer whose team developed an AI-powered Test Failure (TF) Triage Agent, transforming how developers manage test failures in Salesforce’s extensive testing environment.
Discover how his team addressed the daunting challenge of over 150,000 monthly test failures from a pool of 6 million daily tests and 78 billion test combinations, utilized AI tools like Cursor to create the solution in just six weeks, and achieved a 30% faster resolution time while building developer trust through incremental delivery and context-driven AI suggestions.
What is your team’s mission as it relates to quality engineering?
The mission of our Platform Quality Engineering team is to serve as the last line of defense before code ships to customers. We represent the testing phase of the software development lifecycle, focusing on quality analysis for every product that reaches our customers. Unlike individual scrum teams that test code in isolation, our team conducts comprehensive integration testing across different products.
One of the critical challenges we address is the common customer feedback: “Products work great individually, but when used together in workflows, they feel like they come from different companies.” Our team exists to catch integration bugs before they reach customers, as a single bug spillover can be incredibly costly, considering the engineering time required to fix it in production.
Beyond traditional testing, we are constantly seeking ways to automate engineering workflows and improve developer productivity. This is where the TF Triage Agent comes in. It represents our mission to transform a painful manual process that consumed significant engineering time into an AI-powered solution. The TF Triage Agent provides developers with concrete recommendations within seconds, streamlining the test failure resolution process and ensuring that our products work seamlessly together.
What specific AI and automation architecture challenges emerged when building an AI system to process 10 million daily tests with sub-30-second response times?
The most significant challenge was bridging the gap between massive volumes of noisy, unstructured error data and targeted solutions developers can trust. As of April 2025, our systems handle 6 million tests daily, across 78 billion test combinations, with 150,000 test failures per month and 27,000 changelists per day — illustrating the scale and complexity our team is responsible for validating. Traditional SQL database approaches are inadequate for handling the real-time analysis required for such a large volume of data.
To address this challenge, the implementation of a FAISS-based semantic search over indexed test history dumps enables fast, low-latency resolution matching. Robust parsing pipelines and contextual embedding of code snippets, along with error-stack-to-fix matching systems, were developed. These systems handle the vast amount of data while maintaining high accuracy.
The AI architecture required asynchronous, decoupled pipelines to support rapid triaging without slowing down CI/CD processes. By combining semantic search with LLM reasoning at the algorithmic level, intelligent processing of millions of data points is ensured. This approach provides developers with precise, specific guidance, avoiding the generic AI-generated suggestions that could erode trust.
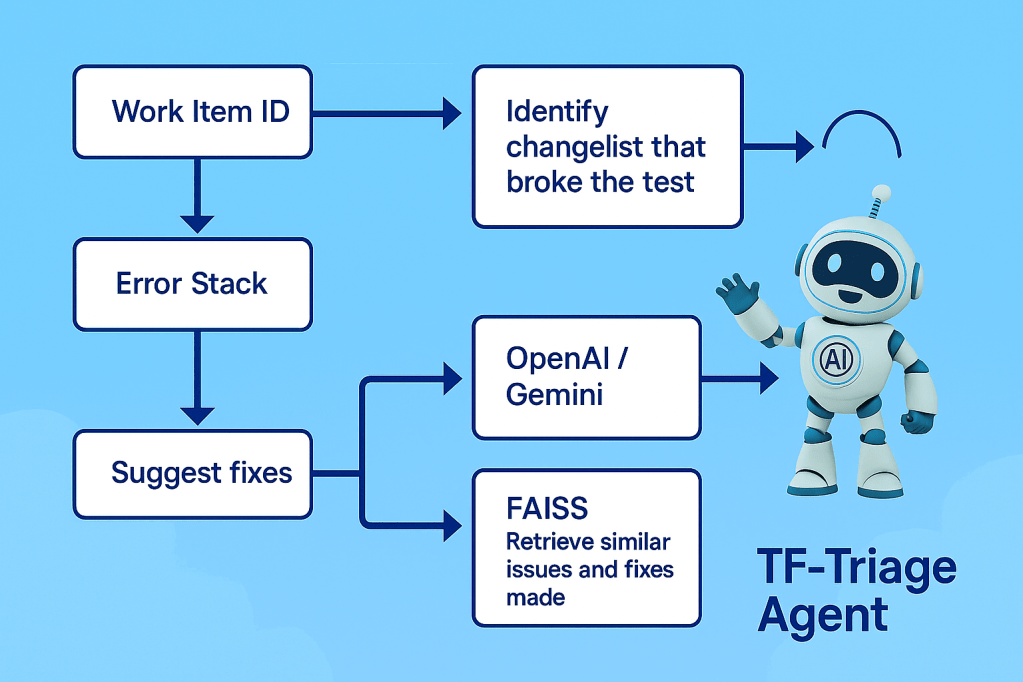
Depiction of the TF Triage Agent tracing test failures and suggesting smart fixes.
What machine learning accuracy and developer experience challenges did the team face ensuring AI-powered test automation wouldn’t hinder engineering productivity?
Developers often expressed skepticism toward AI tools, primarily due to concerns about hallucinations and inconsistent outputs. Given the high volume of daily changelists and complexity of test coverage, even a small increase in false positives or speculative AI output could create noise and erode trust. Engineers questioned whether these tools would introduce more confusion than clarity, or if the tools would overwhelm with numerous options when only a few were relevant. The human factor presented significant risks to the adoption of these technologies.
To address these concerns, the team implemented a layered approach that integrates AI insights with concrete Salesforce data. Rather than relying solely on AI-generated suggestions, the system pairs these insights with historical solutions derived from FAISS-indexed past fixes. For example, the system might indicate, “This issue appears to have a similar stack trace to a different test that was resolved yesterday.”
The emphasis was on providing the AI with precise, contextual data instead of broad, open-ended prompts. Instead of a generic query like, “Can you find why this failed?” the system offers detailed information: “This failure occurred at this specific feature, line, and class. Here are the exact files, the replication scenario, and 50 changes made yesterday. Which of these changes might have caused the issue?”
This approach ensures that the AI operates with exact context, reducing the likelihood of speculative or inaccurate suggestions. By providing developers with precise and relevant guidance, the system builds trust and enhances the overall effectiveness of the development process.
What developer productivity and CI/CD pipeline challenges was the team facing before using AI automation tools like Cursor — and how did AI-powered development change the technical approach?
Before Cursor, diagnosing countless monthly test failures manually — across daily changelists — was unsustainable. Developers wasted hours navigating logs, changelogs, and GUS records, compounding backlog and burnouts — pending hours on each failure, leading to significant productivity losses and a growing backlog.
With 30,000 engineers potentially affecting any test, questions like “Is this a flaky test? Did another team introduce a bug? Should I wait for it to resolve itself?” were common. Each failure required extensive manual investigation, often taking several hours.
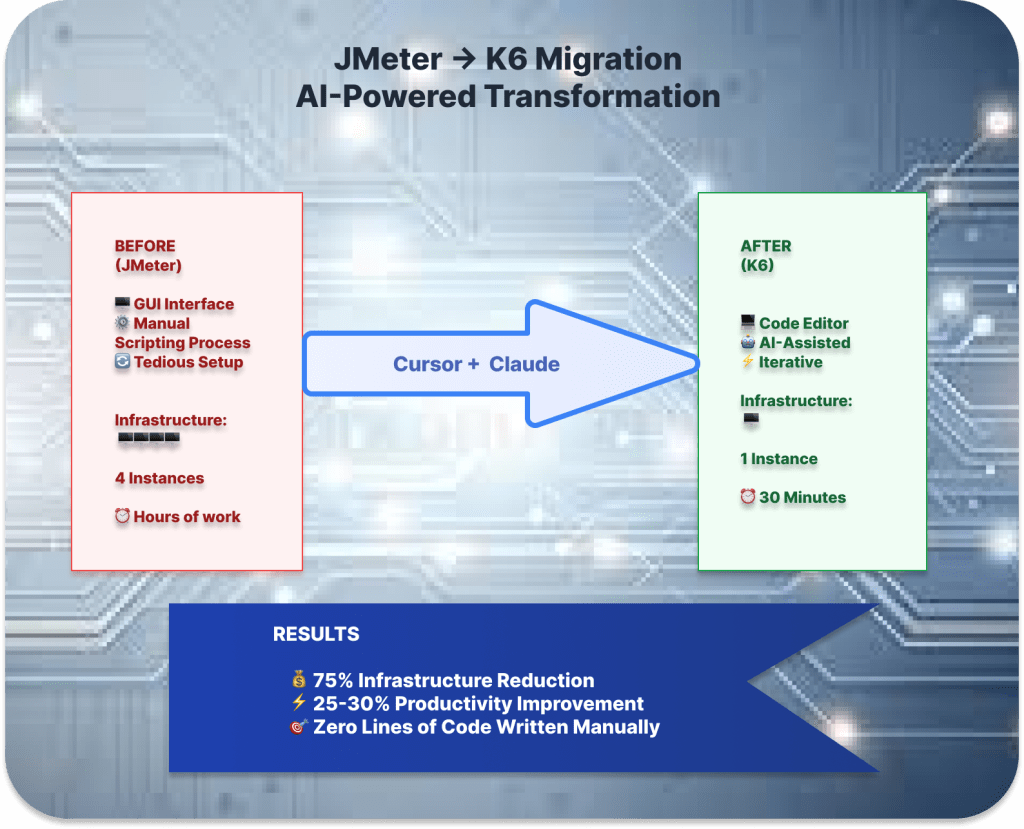
Cursor transformed the development workflow by streamlining the diagnosis process and eliminating context switching. What would have taken months to build, the team delivered in just 4-6 weeks. Cursor’s deep integration with the codebase provided immediate, contextually relevant suggestions during the development of the TF-Triage Agent. For example, when adding a new similarity engine, we could instantly reference how a similar retrieval mechanism was implemented elsewhere, ensuring consistency and reducing redundant effort. This allowed the team to focus on designing intelligent failure triage logic while Cursor filled in the implementation scaffolding.
When scaling challenges arose, Cursor enabled rapid iteration by offering multiple design paths and insights into how other parts of the system behaved, helping the team move from trial-and-error to confident architectural decisions. This shift allowed engineers to focus on building robust logic rather than hunting down wiring or legacy mismatches. By providing precise, actionable context during the development phase, Cursor significantly accelerated the engineering cycle and helped deliver a reliable, intelligent test triage tool faster — with higher confidence.
What specific productivity improvements has the team measured since deploying the TF Triage Agent, and how is the 30% faster resolution times technically validated?
The team documented a 30% reduction in test failure resolution time, validated by comparing metrics before and after deployment across multiple scrum teams. The average resolution time dropped from seven days to two to three days.
Validation involved analyzing scrum team dashboards, comparing test failure patterns from a month before deployment to current performance. Teams that adopted the tool were measured against historical baselines using time-from-creation-to-resolution metrics in GUS.
The deployment strategy was phased to build trust: starting with an internal 20-person team, then expanding to focused scrum teams, and scaling to all 500 people in AI Application Development Cloud. The team is now preparing to expand to Service Cloud, Sales Cloud, and Industries Cloud.
In addition to faster resolution times, the team tracks dev hours spent on root cause analysis and the success rate of suggested changelists. The most appreciated feature was identifying the highest probability change that broke tests. Teams consistently reported, “The probability of the change you pointed to being the actual cause was very high,” enabling engineers to focus immediately on fixes rather than lengthy investigations.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.