By Suvra shankha Dutta and Vikas Mangla.
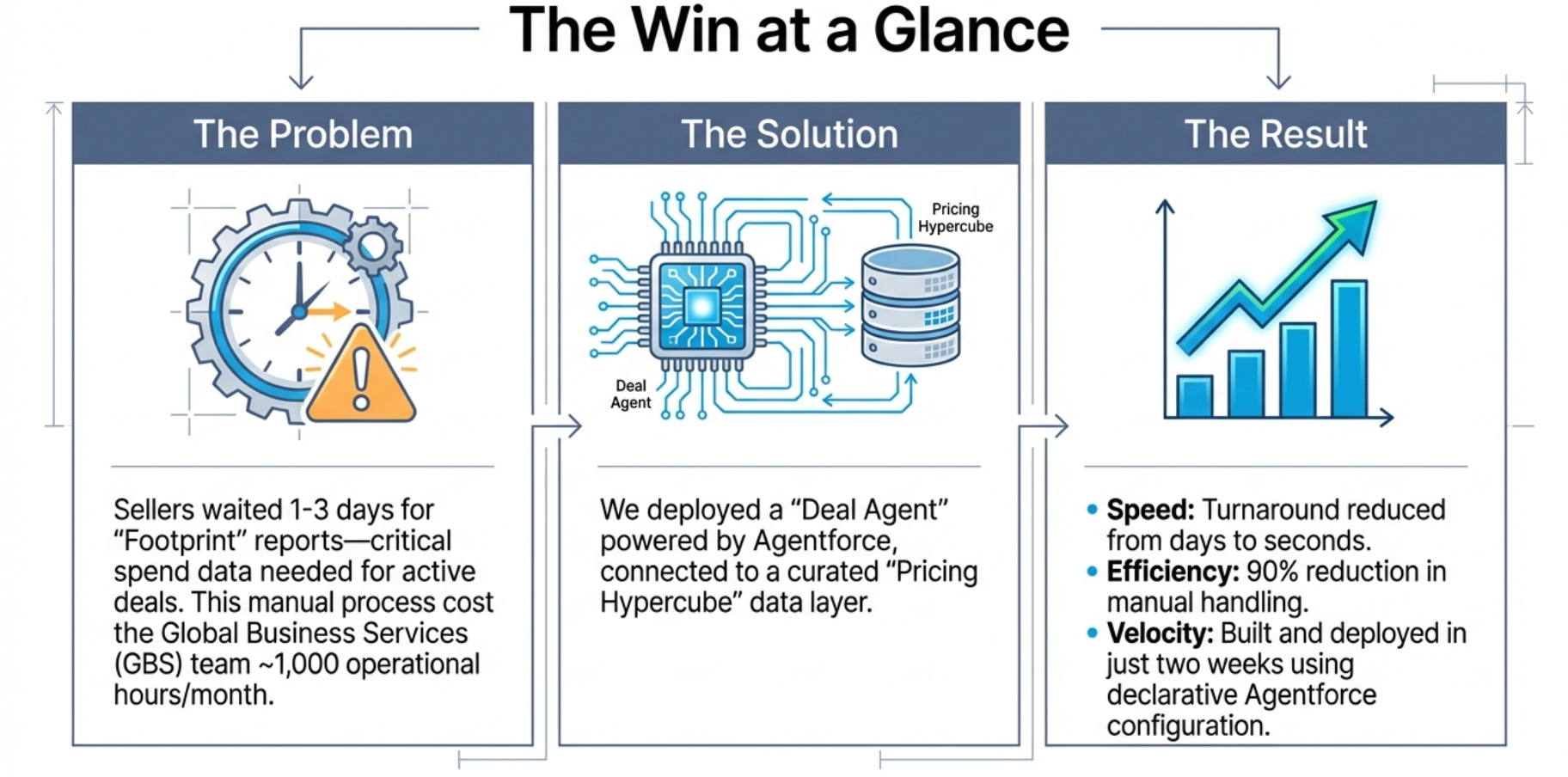
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we spotlight Suvra shankha Dutta, Director of CPQ Product Management, who led the creation of Customer Footprint for Deal Agent to provide a unified view of revenue-generating products and contracts across multiple Salesforce orgs, replacing a manual process that previously drained 1,000 hours every month.
Explore how the team engineered a cross-org aggregation engine that resolves identity gaps and complex hierarchies within strict API limits, then integrated that logic into Deal Agent using Agentforce to remove manual bottlenecks and ensure precise data accuracy at scale.
What is your team’s mission extending Deal Desk Support with an Agentforce-powered customer footprint capability?
Sellers deserve instant, self-service access to comprehensive customer product footprint data within their deal workflow. Previously, sellers relied on an operational workflow to retrieve consolidated asset reports. This separation created latency and limited how quickly teams incorporated footprint data into active pricing, renewal, and expansion discussions.
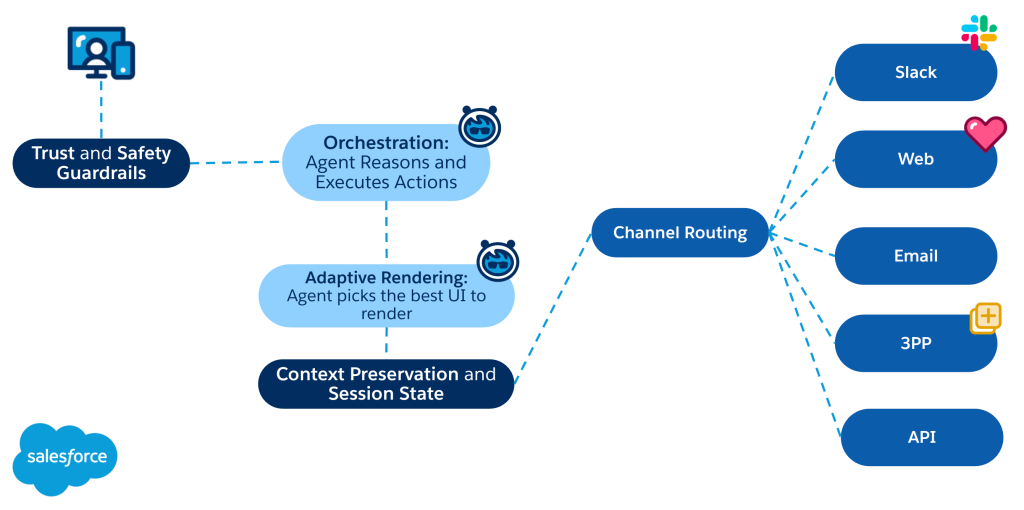
To remove this structural dependency, we embedded footprint generation directly inside Deal Agent using Agentforce. Sellers now request a consolidated footprint through natural language or a dedicated entry point. This action triggers structured API orchestration without requiring a departure from the deal context.
The system generated 391 unique footprint reports within the first two weeks of launch. This immediate adoption proves the value of the integration. Rather than focusing on simple automation, we embedded hierarchy-aware retrieval directly into the decision surface where sellers operate.

What identity-resolution and hierarchy constraints shaped how you built the customer footprint engine?
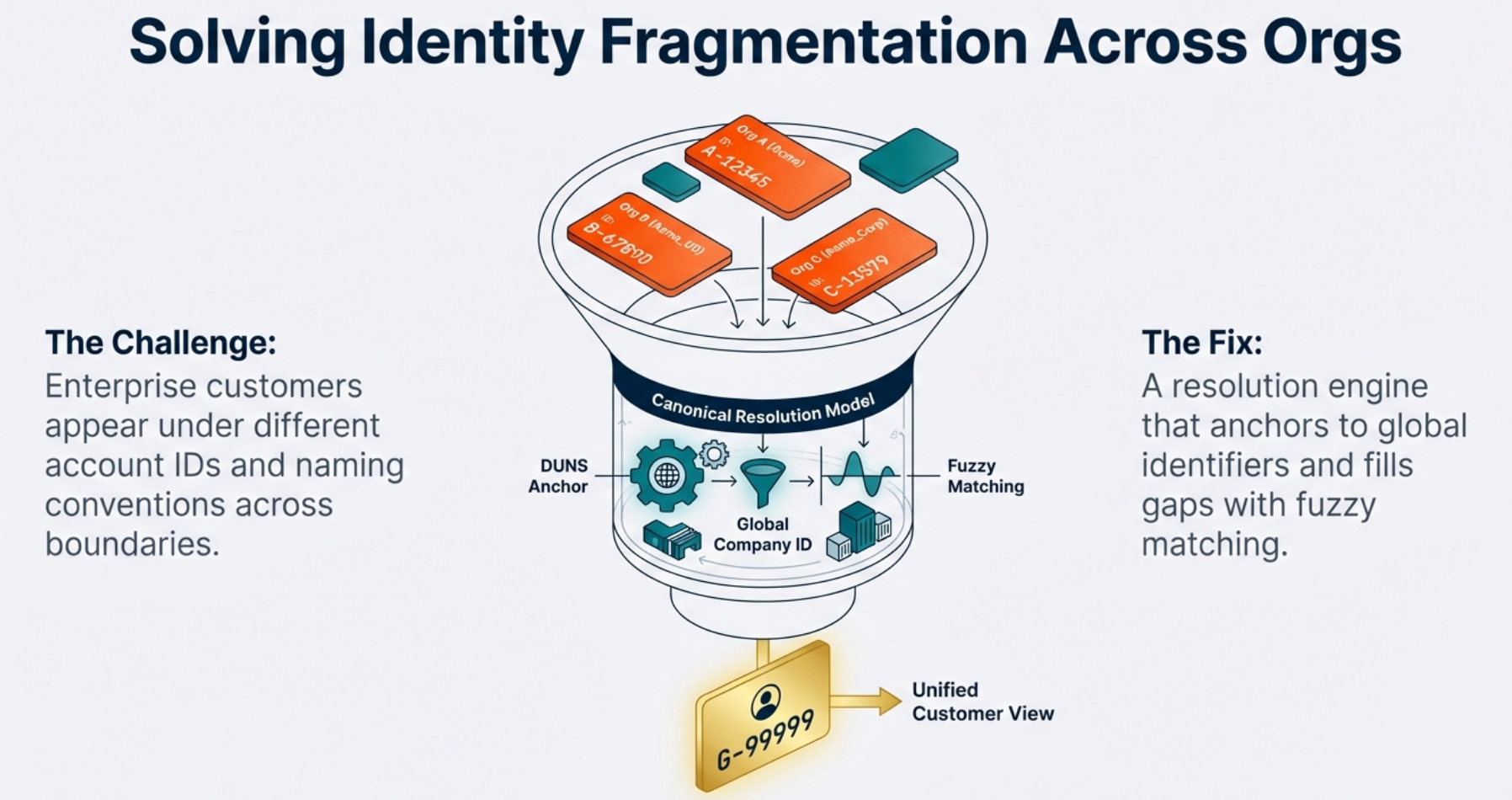
Identity fragmentation across organization boundaries creates a significant engineering constraint. The same enterprise customer often appears under different account IDs, naming conventions, and schema customizations without a universal identifier. Additionally, assets frequently carry inconsistent expiration logic and contract metadata across different environments. Attempting real-time aggregation across these systems risks hitting API rate limits and producing inconsistent joins.
To solve this, we joined forces with our Data & Analytics (D&A) colleagues, who established a canonical resolution model. This approach uses DUNS and Global Company identifiers to anchor cross-org matching, while fuzzy matching fills the gaps where identifiers remain incomplete.
Instead of executing direct multi-org joins during a request, we implemented a centralized aggregation layer. This layer normalizes schemas and reconciles expiration conflicts using deterministic business rules. By materializing a parent-child hierarchy model in advance and resolving identity upstream, the agent surfaces a consolidated view. This strategy preserves predictable response performance while remaining within API constraints.
What architectural and platform constraints shaped how you embedded that footprint engine using Agentforce in roughly two weeks?
The primary constraint required delivery within two weeks while integrating into an existing agent architecture. Building a standalone UI, custom authentication layer, or bespoke conversational engine exceeded the feasible timeline. Additionally, executing cross-org API calls synchronously at prompt time introduced unacceptable latency.
To operate within these constraints, we decoupled data aggregation from conversational rendering. During the first week, team focused on enabling backend orchestration across high-volume data sources and validating a single end-to-end footprint retrieval path.
In parallel, we configured Agentforce topics, actions, and prompt templates declaratively instead of writing custom orchestration code. By leveraging the built-in conversational interface, intent recognition, and access validation of Agentforce, we concentrated engineering effort on aggregation correctness. This approach compressed delivery into the required two-week window.
What correctness and guardrail constraints shaped how you ensured the agent generated accurate and trustworthy footprint outputs?
Footprint data informs renewal timing, pricing strategy, and expansion planning. Misinterpreting asset status, hierarchy ownership, or expiration logic erodes trust. Open-ended generative interpretation fails this use case.
To enforce correctness, the team constrained the agent to operate exclusively over structured API responses from curated Snowflake-backed datasets and D&A APIs. Prompt templates summarize validated outputs instead of inferring new conclusions. We also implement explicit failure handling for unresolved account matches, unavailable org data, and incomplete hierarchies to prevent partial or misleading results. By separating deterministic backend reconciliation from conversational summarization, we minimize hallucination risk and ensure reproducible footprint outputs.
What operational bottlenecks did you eliminate by automating customer footprint generation?
The legacy workflow required manual extraction across multiple organizations, hierarchy reconciliation, and spreadsheet compilation before delivery to sellers. That process typically took one to three days per request and created persistent queue backlogs. It also consumed approximately 1,000 hours per month of operational effort.
To eliminate that bottleneck, we replaced the manual case workflow with automated API orchestration, triggered directly from the seller interface. Requests now generate consolidated Google Sheets at the L5 level within seconds, including pricing, quantity, and tenant information. Within two weeks, the system captured 54% of total footprint volume company-wide, and request volume grew 30% week over week. This reduced manual footprint handling by approximately 90% while removing queue dependency from the seller workflow.
What scale and data-volume constraints shaped how the system handles enterprise customers with thousands of assets?
Managing data for large enterprise accounts involves more than just handling high throughput. Many organizations oversee thousands of SKUs across various subsidiaries, support contracts, and legacy environments. Sending every raw record directly to the agent creates heavy payloads, which slows down rendering and obscures important details.
To solve this, we set strict inclusion criteria at the backend layer. This means the system identifies active, revenue-generating assets and removes expired trials or zero-dollar SKUs before they reach the processing stage.
By refining the data early, we reduce the overall dataset size. This approach ensures the system stays fast and reliable for high-volume accounts while keeping the information relevant to your needs.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.