


Written by Viraj Jasani and Andrew Purtell
At Salesforce, we run a large number of Apache HBase clusters in our own data centers as well as in public cloud infrastructure. This post outlines some important design aspects of Apache HBase and how its data distribution mechanism has evolved over time to become more robust and scalable.
A Short Introduction To How HBase Manages Data
First, let’s define sharding or horizontal partitioning. Sharding is the process of breaking up large datasets into smaller chunks (the shards) that are then typically distributed over multiple data serving resources (servers). Therefore let us define a shard as a horizontal data partition that contains a subset of the total dataset. The idea is to distribute data that can’t fit on a single node (or server) onto a cluster of database servers. The server that hosts a shard is responsible for serving that portion of the overall workload. HBase provides automatic sharding out of the box.
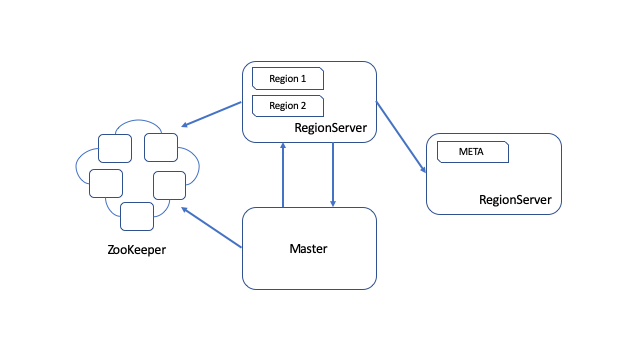
HBase stores rows of data in tables. Tables can be grouped into namespaces. A table can belong to only one namespace at a time. Tables are split into groups of lexicographically adjacent rows. These groups are called regions. By lexicographically adjacent we mean all rows in the table that sort between the region’s start row key and end row key are stored in the same region. Regions are distributed across the cluster, hosted, and made available to clients by regionserver processes. Regions are the physical mechanism used to shard and distribute the write and query load across the fleet of regionservers. Regions are non-overlapping. A single row key belongs to exactly one region at any point in time. Together with the special META table, a table’s regions effectively form a b-tree for the purposes of locating a row within a table. HBase is properly described as a distributed ordered tree. When a region becomes too large after adding some data, the region is split into two separate regions at the midpoint of the region’s key range, creating two roughly equal halves. The HBase master, or coordinator, takes care of balancing the assignment of regions across the fleet of regionservers to ensure all nodes of the cluster have a similar distribution of regions and load. An HBase cluster typically runs several instances of the master or coordinator daemon. They elect a leader among themselves, and this active coordinator takes on certain management and housekeeping responsibilities, including region assignment.
Writes to a region are served by only a single regionserver at any point in time. This is how HBase guarantees consistency and how we can implement cheap atomic operations with good performance. In trade, when a region is offline, writes to the portion of the keyspace covered by that region must be held and retried until the region is online again. Reads may be served by either one or up to three regionservers, depending on if the optional read replica feature (HBASE-10070) is enabled for the given table(s).
While regionservers host regions that serve data to clients, the active coordinator also has considerable responsibilities:
- It must assign regions to the fleet of available regionservers in order to make the data available to the client. (The words “assign” and “assignment” throughout this blog post series will refer to this operation).
- It must drive and balance the allocation of regions across the fleet of regionservers. Based on various metrics like load of the server, number of regions available to a given server, etc, the coordinator continuously attempts to balance the cluster by moving regions from heavily loaded servers to less occupied servers.
- It must perform various table schema and metadata operations, such as table creation or deletion, schema modification, and explicit onlining (enable) or offlining (disable) of tables.
- It maintains an in-memory snapshot of the overall state of the cluster, makes the snapshot available to clients, and exposes various metrics regarding the status and health of the cluster, the regionservers that make up the cluster, and the regions hosted on those regionservers.
If we step back, what this architecture looks like from orbit is a collection of many small databases (regions) which are dynamically assigned to a fleet of servers (or regionservers). The lifecycle of a region is very similar to the lifecycle of a standalone database: At rest, the database is a collection of files. These files are mounted into a serving process. The serving process announces their availability. The serving process then handles reads and writes. When shutting down, the serving process flushes all pending writes into files, and then, at rest, the database is a collection of files again. This cycle repeats as the responsibility for serving the data is reassigned from one server to another by the active coordinator. The responsibility for serving a region shifts when there are server failures or when triggered by an administrator or a housekeeping task performed by the active coordinator, such as the balancer or the normalizer. The process of opening a region or closing a region is transitional by nature. Therefore, we term regions currently in the process of opening or closing as regions in transition, or “RIT”.
A region may enter transition for a variety of reasons as we discuss in the next section. The chief goal of region assignment in the active coordinator is to minimize the amount of time any given region is in transition; and the trade-off between necessary global optimizations, like balancing, and minimizing any/all-time in transition. This is because RITs affect availability. The process of assignment must itself be efficient, effective, and reliable, or otherwise inefficiency or unreliability there may impact availability.
Region Availability
Let us attempt to define region availability as simply as possible given the various runtime options HBase makes available to operators:
- The assignment has two goal states: ONLINE, when a region is available for request serving; and OFFLINE, when a region has been taken out of service, perhaps because its table has been disabled or deleted.
- A region may be OFFLINE, ONLINE, or in another, transitional, state. If a region is ONLINE, it is available and can receive and process requests from clients; otherwise, it cannot.
- A region is available for writing on at most one regionserver.
- A region is available for reading on at most either one or three regionservers, depending on if the read replica feature is enabled for the respective table(s).
- When a region is in transition, it is not available until it is ONLINE again.
If read replicas are enabled, other replicas of the transitioning region can continue to serve read requests, but the replicas may not have received the latest write from the primary in failure cases. Read replicas transition independently from the primary region.
A region may enter transition for a variety of reasons:
- Server hardware failure
- Regionserver process crashes/bugs
- Administrative actions like table creation, deletion, schema modification, and explicit onlining (enable) or offlining (disable)
- Automatic management processes:
- Region splits (auto-sharding)
- Region merging (keyspace to shard distribution optimization)
- Balancing (shard to server distribution optimization)
What is Apache Zookeeper and How Does HBase Use it?
Apache ZooKeeper is a quorum-based service for coordination and configuration, providing distributed configuration synchronization and group coordination services. ZooKeeper provides applications, such as HBase, a filesystem-like interface in which a collection of mutable values are organized into a tree-like hierarchy. A node in the tree is referred to as znode. Znodes are strongly versioned and optionally protected by access control lists. Clients can set watches on znodes, which trigger callbacks to application code whenever the contents or state of a znode changes. These primitives allow ZooKeeper users like HBase to implement reliable and consistent state tracking and event notification features.
HBase uses Zookeeper for multiple purposes:
- Coordinators elect one of their numbers into an active role and track both the currently active coordinator as well as remaining alternative (or backup) coordinators.
- Regionservers can track cluster status and the location of the current active coordinator.
- Coordinators can track dynamic configuration settings and the state of various toggles that mediate background housekeeping activity, such as region balancing, table normalization, and region splitting or merging.
- Coordinators can track the liveness of each regionserver in the regionserver fleet, and whether or not any are in online or draining (shutting down) state. When server failure is detected, the coordinator implements recovery procedures to redistribute regions that were previously served by a failed server to other, available, servers.
- Coordinators and regionservers can track the location of the special meta region that tracks the location of other regions.
- If cross-cluster replication is enabled, the coordinators and regionservers can track and update peer cluster and replication queue details.
- Coordinators and regionservers in HBase versions 1.x implement region assignment workflows using znodes as rendezvous. (We will shortly talk more about that in this blog post series.)
HBase 1 vs HBase 2
HBase 1 is a long-term-stable release version, still under maintenance but trending toward end-of-life.
HBase 2 is the latest stable release version. HBase 2.0.0 was released in early 2018. As of today, the latest stable HBase 2 release line is 2.4.x. HBase 2 offers many improvements over HBase 1. Of particular interest is the evolution of the design and implementation of the process of region assignment. In an HBase cluster, the currently active coordinator manages the assignment of regions to regionservers.
The AssignmentManager
The HBase architecture consists of coordinators and regionservers at its core. What regionserver among the fleet is given responsibility for serving a given region is determined by the currently active coordinator process. The coordinator’s AssignmentManager (AM) component orchestrates the transfer of region serving responsibility from one server to another.
In HBase 1, assignment is a state machine implemented in three places:
- Coordinator side logic for making decisions and monitoring progress.
- Regionserver side logic for taking action and responsibility.
- ZooKeeper, as the rendezvous point for #1 and #2. ZooKeeper is used for state synchronization between these distributed processes.
In the standard assignment, the coordinator initiates an assignment, the regionserver processes the request, a zookeeper znode is used by both the coordinator and regionserver as a rendezvous to communicate state changes to the assignment in progress, and, finally, the regionserver updates the relevant entries in the meta table directly:
Why redesign AssignmentManager in HBase 2?
Assignment in HBase 1 has been problematic in operation. Here are some reasons:
- Complexity: During region assignment, the current state of the region in the assignment process is maintained in multiple places: the current active coordinator, the regionserver’s data structures, the meta table, and the znode corresponding to the assignment activity for the region. Completely synchronizing these state replicas is not possible so we must handle cases where one disagrees with another.
- Stability and Reliability: In HBase 1, the region state has multiple writers. The active coordinator and the regionservers can make state changes that represent invalid transitions in corner cases if clocks are awry or in the presence of logic bugs. When that happens, error checking will cause the assignment to fail and enter a terminal condition where the region is not assigned and manual intervention is required. HBase provides tooling to manage this case in production but it is obviously undesirable.
- Slowness and Scalability: Assignment is slower in operation because state transitions are coordinated among HBase daemons and ZooKeeper. The overheads of this coordination place a scalability ceiling on how large a cluster can grow in terms of the number of regions. We can support a couple of hundred thousand regions per cluster with this model. Beyond that point, the process of starting or restarting the whole cluster is prone to load-related errors and can take hours to complete. Such errors might cause the assignment of some regions to fail and enter a terminal condition where the region is not assigned and manual intervention is required.
HBase 2 offers solutions to the above problems in its new version 2 of the AssignmentManager (or AMv2, see HBASE-14614). The new architecture of AMv2 provides a solution to the complexity, scalability, and reliability concerns present in the previous design:
- Zookeeper is no longer part of assignment workflows. The logic for assignment, crash, split and merge handling has been recast as procedures (or Pv2, see HBASE-13202 and its detailed overview). As before, the final assignment state gets published to the meta table for all participants in the assignment process, and clients, to read with intermediate state kept in the procedure’s state transition log (or ProcedureStore).
- Only the active coordinator, a single writer, can write into the Pv2 ProcedureStore and this design improves state handling by dramatically reducing the chances of conflicts among components during state transitions. The active coordinator’s in-memory cluster image is the authority and, if there is disagreement, regionservers are forced to comply.
- Pv2 adds shared/exclusive locking of HBase schema entities — namespace, tables, and regions — to ensure at most one actor at a time has mutable access and to prevent operations from contending over resources (move/split, disable/assign, etc.).
- The current active coordinator is given the sole authority to manage region transitions and lifecycle. Previously, we could have ambiguities in the region transition process caused by desynchronized state among the various replicas, necessitating complex and error-prone handling of resulting corner cases and disagreements.
- The Pv2 framework durably logs all actions taken and therefore every operation in progress can be safely restarted or rolled back should there be any problem, such as a process crash or server failure. Every action taken during region assignment is fully fault-tolerant. In HBase 2.3 and up, HBase uses a coordinator-local region-based store as default ProcedureStore implementation for durably storing procedure state logs (see HBASE-24408), for performance.
In this first part of the blog post series, we have covered some of the important design details of HBase and we have also covered why the AssignmentManager was redesigned in HBase 2, to overcome the shortcomings of its design in earlier HBase versions.
In the second part of the blog post series, we will cover in detail how the evolved version of the AssignmentManager handles region transition workflows.
Thanks to Dhiraj Hegde, Kadir Ozdemir, Laura Lindeman and Prashant Murthy for review and feedback.
See all of the open positions at Salesforce Engineering!



