(Update: my colleague Dr. Elena Novakovskaia and I later incorporated part of this blog into a presentation in AAAI 2020 Workshop on Cloud Intelligence)
Behind every cloud service, there is one or more data centers that support it and ensure customer trust. In this post, I’m going to unveil the mystery of the data center operations. What’s more, I’ll use data centers as an example to show you how to build a data-driven feedback loop that optimizes trust, agility and cost in operations.
Background

As listed in this article, this map shows the locations of the data centers we manage around the world, currently 9 and still growing. Like public cloud providers, we share a lot of technical challenges in data center operations. Unlike them, a lot of services we provide are infrastructure instead of public cloud services.
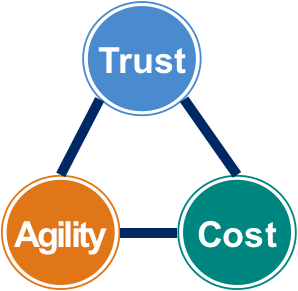
What do you think are the core values of operating data centers? In my opinion, there are three:
- Trust. Services, and the data centers that host them, are secure and meet customers’ requirements for availability and performance
- Agility. The cloud resources that services require are available rapidly
- Cost. Costs, both hardware and operational, are kept within budget
These core values together form a triangle of concerns that teams need to address so that they can run the data centers successfully.
Challenges
However, managing data centers to meet company goals for all of the three areas of trust, agility and cost simultaneously has many challenges. To give a few examples:
- Provisioning. This complicated workflow touches many systems, from network and security to operating systems and software. With so many interdependencies among systems, provisioning can slow down, impacting R&D agility and the cost of assets in the data centers.
- Repair. When a server goes offline, the cause can be anything — software, operating system, hardware failure. The logs may not always tell us the root cause, and there are times where manual intervention is required. In a large server fleet, this type of manual work is extremely costly and can affect the agility of operational teams.
- Power. When power goes out to a data center, for whatever reason, it means downtime for customers, which frustrates them and damages their trust in us. We need power monitoring that can detect issues before an outage occurs.
Areas of Interest
In order to make our data centers more cost efficient, more agile, and more trustworthy, we reflected on our specific areas of interest and grouped them into four areas.
- Data Coverage and Quality. For example, collecting hardware health and power signals, accessing data sources of new acquisitions’ infrastructure, and so on.
- Data Correlation. For example, software events may have correlated with hardware events, although they come from different systems.
- Data Timeliness. It’s important to have the most current data possible. Signal delay may impact the effectiveness of actions, such as incident remediation. Worse, outdated data can lead to erroneous actions.
- Intelligence. Taking repair as example, we need to use the data we collect to build intelligence so that we can automate complicated manual steps.
As you can see, many of the problems we are tackling here are essentially data problems. In fact, they are the common challenges encountered in IT operations. That’s why we need to use state-of-the-art technologies to build a data-driven loop.
Approach
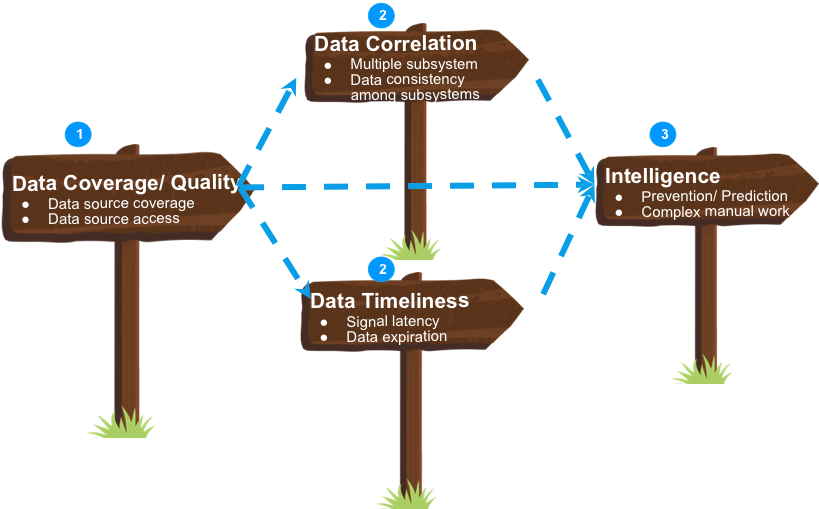
The roadmap we adopted consists of three phases.
- In Phase 1, we addressed data coverage and quality. Without available data or valid data, we couldn’t progress to our subsequent phases. In this phase, we created tooling to collect signals from all data sources of all of our data centers.
- In Phase 2, based on data coverage and quality, we addressed data correlation and data timeliness in parallel. We built tools that identify and fix data validity, data consistency, and data normalization issues across multiple systems. We also conducted machine learning experiments in order to explore opportunities for optimization.
- In Phase 3, based on the results of previous phases, we rolled out smarter tooling and automations such as machine-triaging and self-healing into the server fleet.
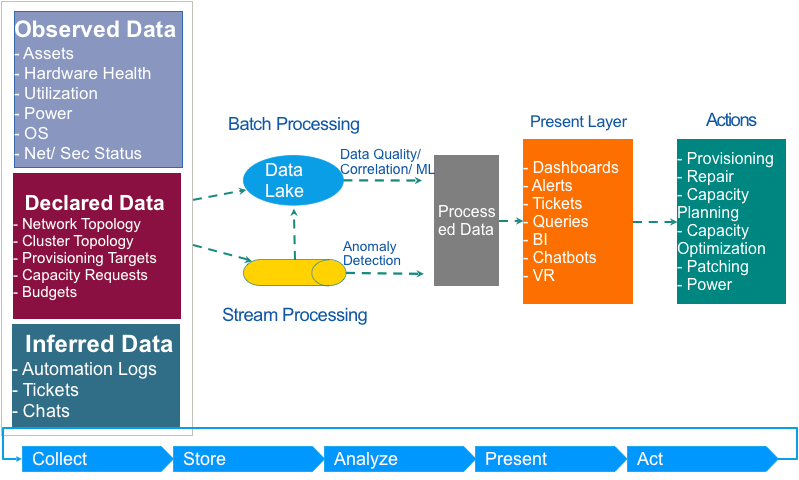
The diagram above illustrates our overall technical solution. You will see that we created a data-driven loop that starts from data collection, to storage, to analysis, to presentation, to action, and then collects new feedback.
- We collect three categories of data in the Collection layer. Observed data are the objective facts we collect from hardware. Declared data is human-defined; it’s the target state we want to arrive at. Inferred data is data generated by software or people.
- The data is collected into the data lake and into stream processing separately. On the data lake, we run batch processing such as data quality improvement, data correlation, and machine learning. During streaming processing, we do tasks such as anomaly detection.
- In Present layer, besides the routine services, we also provided some tools such as ChatOps and VR of data center rooms. All these help operation teams to take automated or intervention actions; each action has its own data-driven loop, assessed by metrics.
Using this data-driven approach allowed us to optimize workflows and to coordinate the many systems, lowering our operational costs while also achieving greater trust and agility.
Looking forward, I believe data center operations will go through 3 phases, from manual to automation to autonomous. Our work is at the early stage of autonomous operations.
Lessons Learned
Now let me share some lessons I learned during the work.
- Maintaining data coverage and quality is a shared challenge across most operational scenarios. This is the most important step. This work might not seem as fancy or “cool” as other work, such as the machine learning work, but it’s critical.
- Building a feedback loop required a business-oriented approach. Start with the business goals and use them to decide what questions need to be answered and what actions need to be triggered. After that, determine what information needs to be collected. That, in turn, determines the data definitions, the data sources, and the data destinations. Building a big data pipeline or applying cool machine learning techniques only comes afterwards.
- There is path dependence in building both data capabilities and tooling capabilities. For data capabilities, the path is from data coverage and quality to data correlation and real timeliness to intelligence. As mentioned above, data coverage and quality are the fundamentals without which we cannot proceed. Data correlation augments the dimensions of machine learning; data timeliness extends the intelligence to detect anomalies in a timely fashion. For tooling capabilities, the path is from manual to automated to data-driven. Sometimes we don’t have automation in place, and this is the time we fill the gap of automation first, prior to addressing the feedback loop.
In summary, at Salesforce, we built a data-driven feedback loop that improved the trust, agility, and cost of data center operations. This trusted infrastructure empowers our company as the world’s #1 customer success platform that enables trailblazers like you.
Thanks to the infrastructure automation, telemetry, orchestration and management teams for their amazing contributions!