Introduction
Sales Cloud empowers our customers to make quick and well-informed decisions, with all of the tools they need to manage their selling process. The features we work on in the Activity Platform team, spanning Sales Cloud Einstein, Einstein Analytics, Einstein Conversation Insights, and Salesforce Inbox, rely on a real-time supply of activity data. Building a robust and reliable data pipeline can be complex because it’s based on the user’s business rules. In an effort to speed development, we’ve created a framework for our business use case that is easily extensible to create a custom real-time ingestion pipeline. In this blog post, we’ll explore its fundamentals, take a look at our design choices framework, and examine the high-level architecture of this framework that makes it versatile.
Background & Terminology
Activities in the context of this topic are of different types, including email, meeting, video call, voice call, etc. The provider/vendor of such activities have a few distinct characteristics:
- They provide a way to fetch a given activity using a unique identifier.
- They let you subscribe to any new activity or changes to existing activity.
- They allow some form of range query.
Some of the popular vendors/providers we support include Gmail, Gcal, O365, and Exchange.
For the scope of this discussion, we’ll focus on email activity. Each mailbox to be crawled is tracked internally as a first-class Datasource object. Each datasource entry tracks all configurations required to communicate with the vendor including the subscription lease metadata. Customers have control over the Datasources they provided and can disconnect/reconnect on demand. Thus, Datasources can be in different states based on various customer actions. As a result, managing this lifecycle of the datasource and respecting its state becomes part of the crawling system.
Breaking up the problem
In a nutshell, the problem we are trying to solve is that we need to be able to capture any change in an external system to data that we are interested in and propagate/introduce this into our system. Let’s dive into the problem space at a high level, and, at each level, define the pieces needed to formulate our solution:
- Systems
- Components
- Subcomponents
Systems
At a high level, the process of crawling an activity can be broken into two major systems.
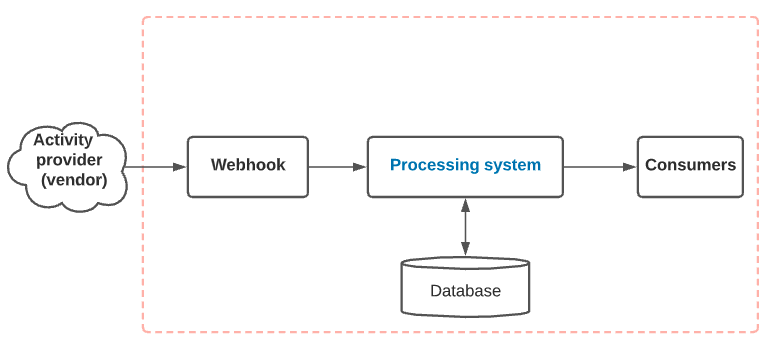
- Webhook — This is a public-facing microservice that accepts incoming notification events and queues the notification for the downstream component to consume. The webhook is a fairly simple process microservice that can be placed behind a load balancer and horizontally scaled.
- Processing system — A processing unit translates the received notifications to their corresponding activities. The system manages the lifecycle of the datasource and tracks any operational metadata.
Components
Let’s expand on the processing system. This system can be broken down into multiple components, each with a specific responsibility.
- Fanout — This component accepts a given notification and fans-out to a number of internal actionable notifications. The fanout queues messages for the collector to consume.
- Collector — The collector is responsible for gathering an activity based on the translated internal notification generated by the Fanout, such as fetching a new email, gathering the RSVP list from a meeting, etc. This component is I/O intensive, and an unreachable external service can have a cascading effect. To mitigate this, the component works with at-most-once semantics. The collector is also responsible for recording all messages it has crawled in a given timeframe. It does this by adding the successfully collected activity Id to a set data structure for a given time bucket.
- Verifier — The verifier’s job is to periodically check for missed data and crawl them. Contrary to the collector, which relies on a push-style operation model, the verifier is a pull-style operation model. This helps us account for any events we miss due to transient errors or cases when we never received the notification itself.
- Refresher — This component manages the lifecycle of the datasource by preemptively refreshing the auth tokens for the datasource and refreshing the subscription lease if needed.
- Onboarder — This special component is used specifically to crawl historical activities. Ideally, the onboarder is triggered the first time the datasource is connected to gather all historical data. Once the historical data is crawled, the datasource is enabled for real-time crawling.
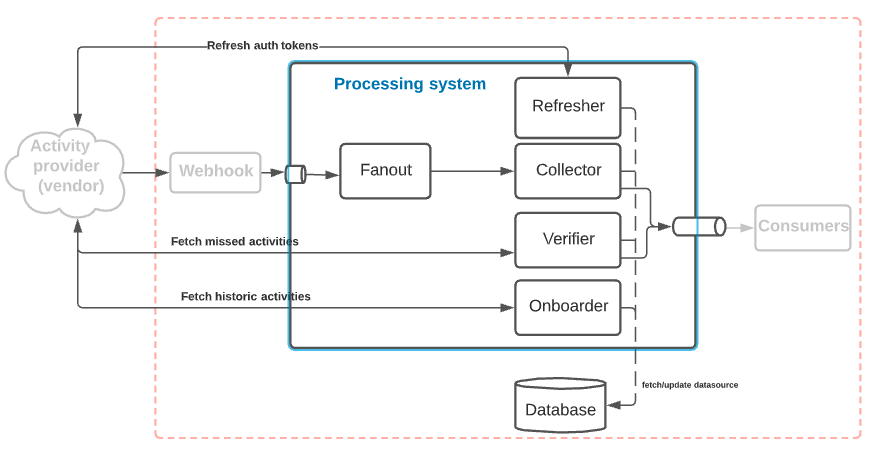
Apart from its component-specific responsibility, each component is also responsible for handling errors and updating the state of the datasource if it observes it as invalid. This allows us to weed out notifications/operations that correspond to invalid data sources. To avoid any messages being dropped as they pass across component boundaries, we recommend using some form of a persistent queuing system. Each component, after acting on a message/operation for a datasource, checkpoints with what we call the component watermark. The component watermark gives us a glimpse of the operational data for a given datasource and helps us track failures at different stages of the pipeline. Each component is further responsible for reporting its metrics and response time.
If we implement each of these components on any stream/micro-batch framework, we’ll have a functioning pipeline capable of capturing any changes in activities from the external provider.
Subcomponents
Implementing these components allows us to stream one type of activity from a given vendor. This may work well for most cases where we have a single vendor and a specific activity type. However, at Salesforce, we need to support different types of activities while supporting various vendors. To make this more extensible, we split each component into reusable subcomponents. Imagine each of the subcomponents as a Lego block; re-packaging them in a different manner allows you to create a component. This approach makes it easy to work with new types of activities and also activities from different vendors.
Let’s dig into the building blocks of each component and its purpose:
- Spouts: This is a borrowed term from the Apache Storm framework. This represents the source of a data stream and is essentially a wrapper around the underlying dataset, e.g. a KafkaSpout that reads data from Kafka. This subcomponent allows you to read data into the component.
- Readers: This construct helps interface with the specific external activity provider. We need a specific reader for each combination of vendor-activity.
- Mappers: These are responsible for mapping any of the external constructs to internal objects, e.g. mapping an email create time to our internal time bucket
- Emitter: This subcomponent allows us to transfer and publish data from a component. Similar to the reader subcomponent, the emitter can also have different flavors, such as a KafkaEmitter to let components queue messages to a specific Kafka topic
- Recorder: This is a unique subcomponent and is used to track individual actions/operations/data for a given component. As an example, the collector component uses a recorder to track a list of activities crawled for a datasource within a specific time frame.
- Transformers: Unlike mappers, which transform an external representation to an internal one, transformers convert one internal representation to another.
- Checkpointer: This allows each component to checkpoint on completion of their action on a datasource. The checkpointer is responsible for updating the component watermark for a datasource and also for updating the datasource state on consecutive failures.
Armed with the above information, we can build most of our components by gluing these subcomponents together in various arrangements.

Each subcomponent can come in various flavors based on the vendor and activity type. If tackled correctly, each subcomponent can be made further configurable to avoid re-engineering.
Conclusion
This framework has been the cornerstone for us to capture activities and data of similar nature. With this generic framework, we are able to significantly reduce development time when deploying a new activity capture pipeline for a vendor. The framework not only provides us with a generic approach to capture activities but also unifies the way we track and monitor such systems. This makes it easier to catch issues early on and alert based on component-specific rules. Although we mainly focused on activity data, this is by no means the limit. As of this writing, we have built real-time robust data pipelines capable of capturing email, calendar, contact, and video call information from different vendors. We hope to improve this framework with our continued learning about new external systems, observations of different ingested data-shapes, and examinations of the operational challenges we face over time. If you’d like to use this framework, let us know on Twitter at
@SalesforceEng! Based on community interest, we may open source this framework.