In our “Engineering Energizers” Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we meet Viraj Jasani, a Principal Software Engineer on the Big Data Storage team. Viraj led the development of DynamoDB-compatible REST services on Apache Phoenix, enabling hundreds of Salesforce teams to migrate across cloud platforms without altering a single line of application code.
Explore how the team reverse-engineered Amazon’s most scalable and powerful 15-year-old database APIs, built highly scalable features, developed dynamic SQL generation to handle diverse query permutations, built enterprise-grade reliability systems for four nines availability, and implemented change data capture with metadata-driven consumer scaling across AWS, GCP, AliCloud, and Salesforce’s first-party data centers.
What is your team’s mission building enterprise multi-cloud database infrastructure with Apache Phoenix for Hyperforce?
The team at Salesforce manages one of the largest distributed database production footprints globally, handling over 72 billion transactions daily across hundreds of petabytes of data. Our expertise extends to key contributions to Apache HBase and Phoenix. We are available on all cloud infrastructures where Salesforce operates.
At Salesforce, we use a diverse range of SQL and NoSQL databases, which can lead to inconsistent behavior and vendor lock-in. Our mission is to create a unified NoSQL database solution that behaves as a single product, addressing all NoSQL use cases across the company. This ensures highly scalable databases that operate seamlessly, regardless of the underlying cloud infrastructure.
What database portability challenges did your team solve when hundreds of teams using AWS DynamoDB needed to expand to GCP and other cloud platforms — and how did this prevent multi-year productivity losses?
Hundreds of teams using DynamoDB face vendor lock-in when expanding to other substrates under Hyperforce’s four-substrate strategy. Without a solution, these teams would be forced to maintain separate codebases for each substrate indefinitely, increasing the likelihood of inconsistent behavior and infrastructure-specific bugs.
To solve this, we developed horizontally scalable HTTP REST servers with API contracts that mirror DynamoDB. This allows teams to use the same codebase and migrate to GCP seamlessly with our DynamoDB REST service, which includes Salesforce-specific features like backup/restore, org migration and tenant encryption.
This API compatibility ensures that teams can continue using the AWS Java, Python, or Go SDKs with our service across all four substrates, as if the teams are using DynamoDB. The only change needed is the endpoint URL, making it possible to achieve zero-code migrations and avoid the multi-year productivity losses that could have hindered Hyperforce’s expansion..
What foundational architectural challenges did your team solve in Apache Phoenix to deliver true DynamoDB API compatibility — and how did Salesforce’s position as primary Phoenix contributor enable these breakthroughs?
Apache Phoenix traditionally provided SQL access to HBase through JDBC APIs, but we needed REST API support for the first time in Phoenix’s history. To achieve true DynamoDB compatibility, we introduced document database support alongside existing SQL capabilities.
We implemented BSON binary JSON data type support, enabling document database functionality while preserving SQL features. This allows for multiple global secondary indexes and indexing on document database models. We also added set data type support for string, number, and binary sets, a unique feature of DynamoDB not found in other document databases. Additionally, we implemented an encoded binary data type to support various combinations of partition and sort keys for the global indexes. To complement these capabilities, we developed complex functions to support a wide range of condition expressions, update expressions, and atomic update APIs, providing powerful and expressive query and mutation capabilities.
This wire compatibility was crucial, given that Phoenix originated at Salesforce and became a top-level Apache project in 2012, with Salesforce as the primary contributor. Most significantly, we evolved Phoenix from an early SQL version to a document database fully compatible with DynamoDB APIs. This makes Phoenix the industry’s first open-source DynamoDB alternative, offering new database options to over 1 million DynamoDB users worldwide for their enterprise deployments.
What technical obstacles did you overcome reverse-engineering Amazon’s DynamoDB APIs to deliver wire-compatible REST services enabling zero-code database migrations?
The biggest challenge was creating wire-compatible API support, which required flexible mapping from DynamoDB request parameters to SQL statements. DynamoDB has a long history of stable features over 15 years, and we needed to generate SQL queries dynamically to handle its diverse and complex request patterns. Templates weren’t feasible due to the wide range of query permutations.
Our team developed context-aware, intelligent SQL patterns that dynamically generate SQL and support all DynamoDB API permutations, including change data capture. We leveraged Phoenix’s internal features, such as uncovered indexes, global secondary indexes, max lookback, time-to-live (TTL) expirations, and HBase partition metadata management to uniquely build change streams.
One of the key challenges was a metadata-driven approach, allowing consumers to determine compute requirements and resource allocation before processing change stream records. As we target the latency-sensitive strict OLTP use cases, we also ensured quick responses for one megabyte of data by implementing server-side and client-side improvements, making this a significant multi-quarter project.
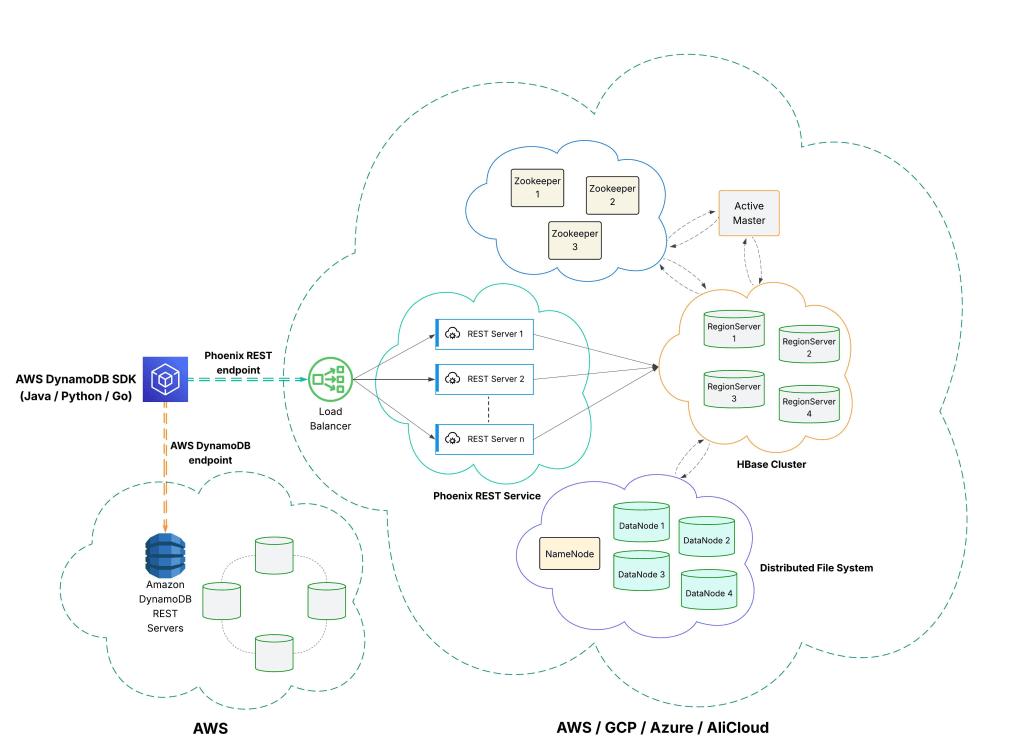
Multi-substrate Phoenix REST Service with DynamoDB APIs.
How did you ensure Phoenix delivers DynamoDB-level performance across AWS, GCP, AliCloud, and first-party data centers through multi-tiered storage architecture?
Cloud-native databases like DynamoDB and Google Spanner offer predictable performance, maintaining consistent latencies as scale increases. We found that traditional hard disk drives (HDDs) couldn’t meet the performance expectations of DynamoDB users. To address this, we developed a multi-tiered storage architecture where part of our cluster uses SSDs for low latency and high throughput, while HDDs provide cost-effective storage.
We implemented an in-memory caching system, ensuring that only the top 95th or 99th percentile queries access SSDs, with the rest served from memory. This significantly improved compute and storage efficiency, bringing Phoenix’s performance on par with cloud-native databases.
We also enhanced Phoenix’s change data capture (CDC) with real-time streaming and partitioning for parallel processing. This allows clients to scale their compute layers based on CDC needs. As HBase tables grow, consumers are notified and can spin up additional instances to maintain processing throughput across all four substrates.
This multi-tiered architecture has been essential for providing the predictable latency and performance that teams expect from DynamoDB, while positioning Phoenix as the first open-source alternative for over 1 million DynamoDB users worldwide, offering vendor-agnostic database options for enterprise deployments.
What development challenges emerged building enterprise systems requiring zero application code changes for hundreds of teams migrating from AWS dependency?
This project represented a multi-year effort from our team over the past five years. We developed several foundational features to support the implementation of our REST service. These include support for global uncovered indexes and partial indexes to optimize query performance, relaxed and conditional TTL for flexible data expiration, and an encoded binary data type to handle combinations of partition key and sort key.
The document data model was extended to support sets, nested lists, and maps, enabling richer data representation. We also implemented change data capture using uncovered indexes, segment scans for efficient large-scale parallel reads, and a variety of functions that support conditional updates and integration with document and binary types.
In addition to above features, we also implemented client-side schema caching to eliminate extra network calls, optimized compaction workloads, achieving significant improvements in compute and storage efficiency, bringing us on par with cloud-native databases.
We segregated read and write workloads into different resource pools to ensure that large read queries don’t impact critical write operations, which are essential for e-commerce applications. We also separated server groups to provide an additional layer of security for metadata, preventing cluster-wide outages in the event of partial failures.
The metadata segregation took nearly two years to develop, ensuring four nines of availability despite HBase being a strongly consistent database. We have also executed large-scale upgrades of HBase, Phoenix, Hadoop, and ZooKeeper, ensuring security compliance for government cloud operations.
With over seven to eight years of consistent work, we developed robust CI/CD workflows, providing the strong foundation necessary for operating the high scale database that can be used by teams worldwide.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.