Written by Prianna Ahsan and Scott Nyberg.
Around the world, companies must satisfy global compliance regulations or face pricey fines, where failure to comply results in 2.71 higher costs than the cost to comply. For example, Fortune 500 companies are projected to lose $8 billion per year as a result of GDPR non-compliance.
In response, Salesforce created Hyperforce, a cloud-based platform that enables Salesforce to rapidly scale its infrastructures for customers. Providing a consistent infrastructure for Salesforce-owned products and services, Hyperforce ensures adherence to global compliance requirements and regulations — removing barriers to customer consumption. For example, Hyperforce supports integration and seamless global adoption of Salesforce product suites, including the MuleSoft Anypoint Platform, a unified integration system for connecting applications, data, and devices.
Featuring countless customers and the largest cloud infrastructure footprint within Salesforce, MuleSoft is currently building its platform within new Hyperforce environments. This process forms the foundation — an onboarding template — paving the way for other Salesforce products’ platform migration.
However, the team cannot solely focus on onboarding — they must tackle two tasks simultaneously: Customers want new features, but building out new environments can be a costly exercise that delays feature development.

How does the MuleSoft team solve this tough tradeoff problem? They amortize the cost of subsequent environment builds by harnessing the power of automation. Automated Environment Builds (AEBs) ensure repeatable and replicable deployments across multiple regions — radically reducing the team’s workload.
Here is a closer look into how the MuleSoft team leverages AEB to easily replicate the onboarding process…
What is Automated Environment Build?
Standing up services in a new datacenter within a new geographic locale traditionally involves a multi-month effort of teams manually experimenting how to best deploy their software while unscrambling obfuscated service dependencies.
What does this mean for the MuleSoft team? They must deliver layers of core foundational infrastructure services in the correct topological order — a complex process — before serving app traffic. These services include:
- The ability to transmit packets: Machine A must be able to communicate with Machine B
- Network infrastructure
- Authenticated connections for identity / access management
- Load balancing
- Ingress gateways capable of monitoring authenticated and unauthenticated traffic, which prevents unauthorized individuals from accessing public APIs
Ultimately, time is the enemy for MuleSoft developers: The longer it takes to for them to build a region, the more changes they must grapple with because these services do not live in a vacuum — they evolve over time as the MuleSoft team innovates on a day-to-day basis, adjusting the architecture and adding features that customers want.
Consequently, new features require the team to take on new dependencies, which must be continuously reflected in the topological ordering; or the team may encounter a new issue because it was not tested in a region build scenario.
That is just the beginning. The MuleSoft team must also deploy more services, which requires a continuous deployment infrastructure. What does that look like? Their build infrastructure needs to replicate their deployment artifacts into particular regions. How do they get there from here? Enter AEB.
AEB enables a topological ordering of every required service — empowering developers to execute and orchestrate the topological ordering programmatically.
For example, if a developer needs services A, B, C, D, and E to execute before service F, an AEB should guarantee that A, B, C D E exists prior to service F. This allows every service downstream to have its dependencies already up and running before it executes.
What is the endgame after AEB executes all the services? MuleSoft goes live within that region and the team executes “game day” performance exercises before opening up the region to production traffic and serving customers.
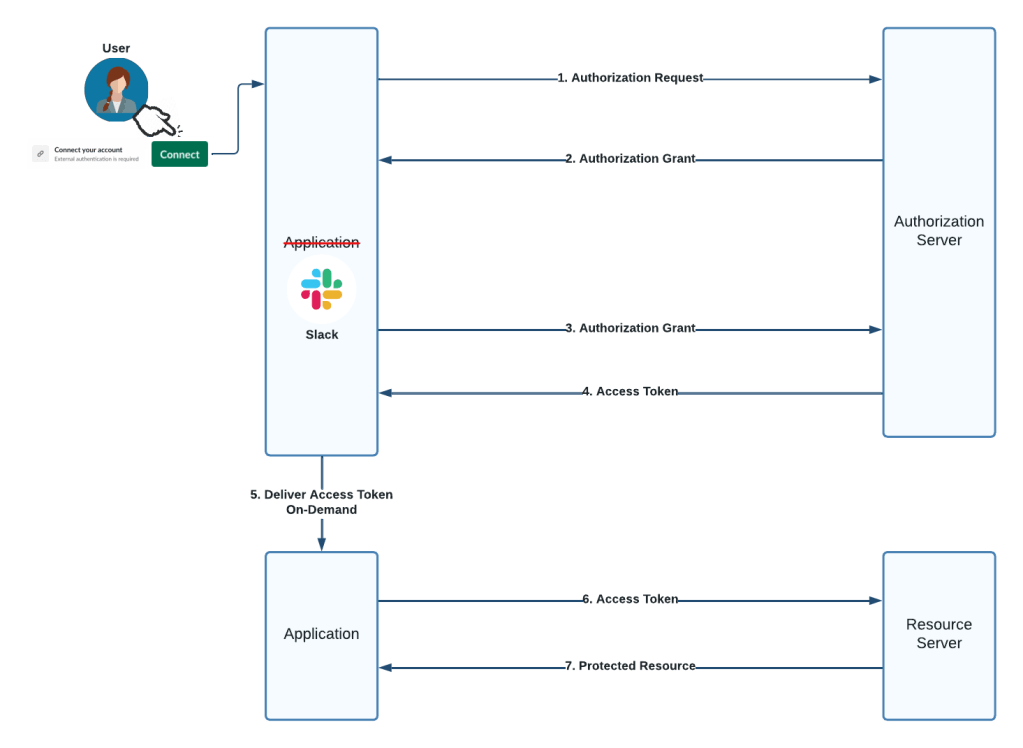
How does the MuleSoft team collaborate with the Hyperforce team?
The MuleSoft team maintains its own mature integration and delivery framework that contains necessary business logic to deploy its services in a specific topological order. As the team migrates to a new region, they share this information with the Hyperforce team, empowering them to incorporate it within their orchestration framework and extend their infrastructure to support MuleSoft’s use case requirements — explicitly codified within a CI/CD platform.

A look at MuleSoft’s CI/CD integration with Hyperforce. The two teams closely collaborated to design an effective solution that efficiently onboards MuleSoft onto Hyperforce.
Diving deeper, the collaboration process is about translating MuleSoft’s requirements into a set of plug-ins and extensions called add-ons. Others are translated into additional API endpoints for foundation services. Ultimately, the process for the MuleSoft team focuses on just separating out those things, asking questions ranging from “how can we employ the existing extension mechanisms to serve our use cases?” to “what are things that we actually just need new mechanisms for?”
This process is simpler than you might imagine. The MuleSoft team informs the Hyperforce team, “Here’s what we are doing and here is what we need.” The Hyperforce team typically responds, “Well, here is what we have.” Following that, the two teams meet in a room to white board, discuss requirements, and study code. Lastly, both teams write up abbreviated experimental implementations and try them out, using the data to iterate further. Hyperforce teams also write proof of concepts, sharing them with the MuleSoft team.
And best of all, closely collaborating with the Hyperforce team empowers the MuleSoft team to avoid pausing feature development — continuing to deliver world-class value to their customers while reliably and regularly building out new Hyperforce environments.
Learn more
- To learn how Prianna’s MuleSoft production engineering team enhances developer experiences, read her blog.
- Check out our Technology and Product teams to learn how you can get involved.
- Stay connected – join our Talent Community!