In our Engineering Energizers Q&A series, we shine a spotlight on engineering leaders who tackle complex technical challenges at Salesforce. Today, we feature Jayesh Govindarajan, Executive Vice President of Software Engineering at Salesforce. Jayesh leads the development of Agentforce — an AI-driven system designed to autonomously plan, reason, and execute enterprise workflows. His team is pushing the boundaries from predictive AI to generative and agentic AI, revolutionizing how businesses automate complex decision-making and operations.
Discover how Jayesh’s team scaled Agentforce to 1000 customers in just three months, optimized retrieval-augmented generation (RAG) for enterprise-scale AI, and built a fault-tolerant execution pipeline for multi-agent collaboration.

What were the biggest engineering challenges in transitioning from predictive AI to generative AI and then to a fully agentic system? How did the team overcome these challenges while maintaining seamless integration within the Salesforce platform?
Agentforce, Salesforce’s agentic AI system, is designed to plan, reason, and execute workflows autonomously. The transition from predictive AI to generative AI, and then to agentic AI, introduced distinct engineering challenges at each stage.
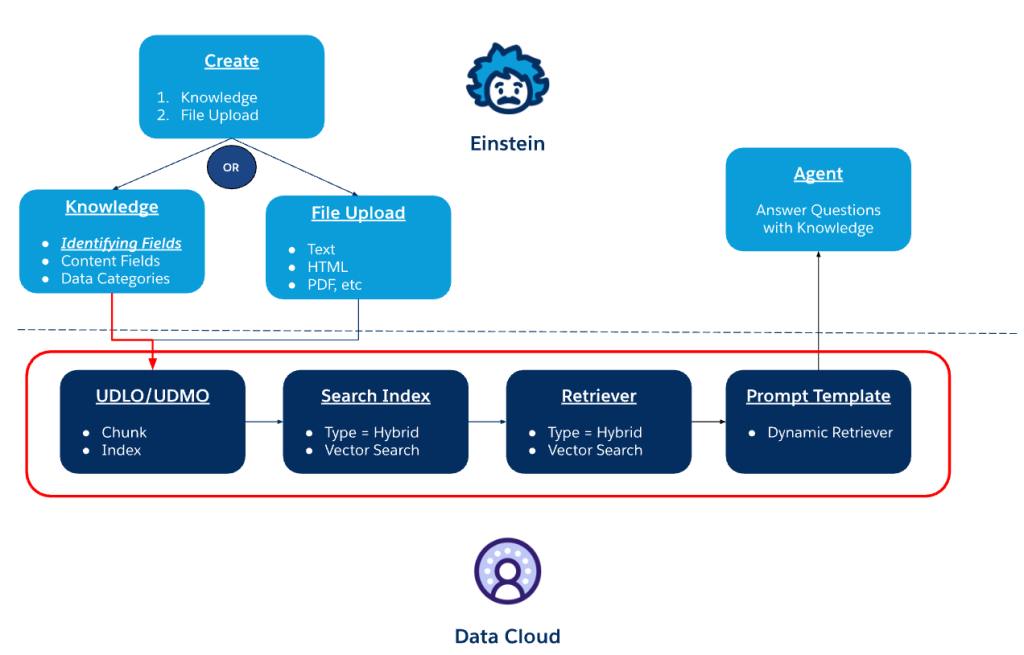
The first major challenge emerged when moving from predictive AI to generative AI. Predictive AI models relied on statistical classification and decision trees, which were highly structured but limited in adaptability. These models could forecast trends, such as lead scoring, but could not generate responses or synthesize complex data. The shift to generative AI required integrating RAG to provide enterprise-specific context, ensuring AI-generated responses were accurate. The challenge was balancing high recall and precision, which the team addressed by optimizing multi-tiered document indexing and pre-computed semantic embeddings.
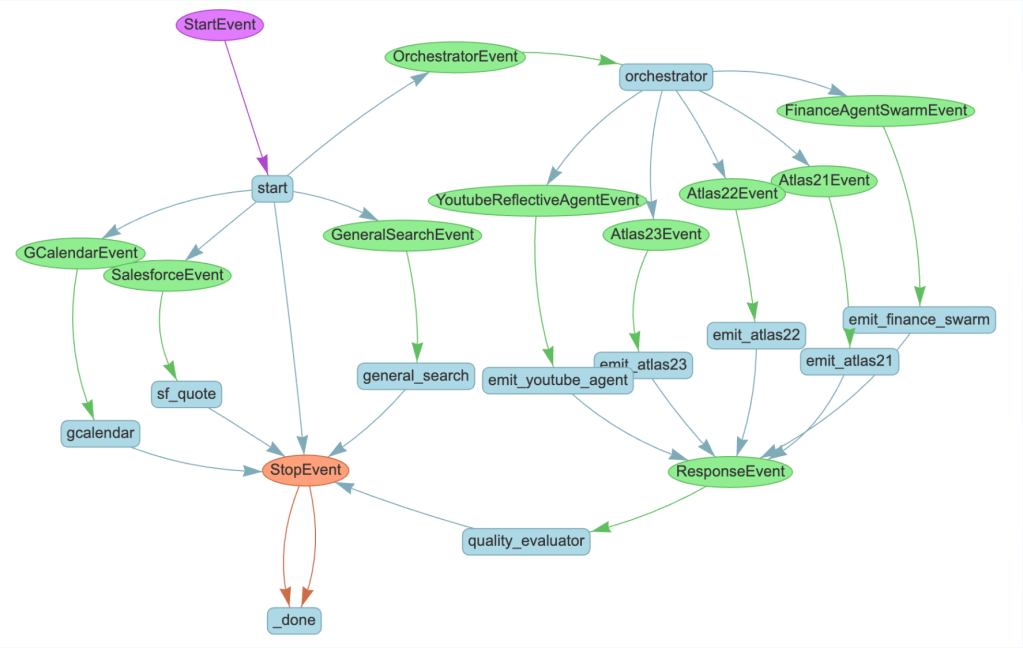
The next challenge was transitioning from generative AI to fully agentic AI. While generative models could produce intelligent responses, these models lacked the ability to autonomously plan and execute multi-step workflows. In response, the team developed the Atlas Reasoning Engine that can dynamically understand user intent, decide what action to take, and sequence actions across Salesforce Data Cloud, MuleSoft, and external APIs.

To ensure seamless integration, Agentforce offers the Agent API, making AI-driven automation easily deployable within both Salesforce and external applications. Additionally, inference pipelines were optimized to handle up to 2 billion AI-driven predictions per month, ensuring real-time execution across enterprise workloads.

What technical roadblocks did the team encounter when scaling Agentforce to Salesforce’s expansive customer base?
Unlike traditional software rollouts, where enterprises phase in new capabilities slowly over time, with the sudden rise of agentic AI, companies have been driven to integrate AI-driven workflows, often without prior AI experience. This created onboarding issues where misconfigured automation led to workflow failures. To mitigate this, the team built AI-guided configurations and guardrails that make Agentforce approachable for even a novice user.
Performance bottlenecks also emerged as customer adoption surged. Agentforce spans Salesforce Core, Data Cloud, and MuleSoft, meaning AI workloads had to be synchronized across multiple platforms. To address this, the team introduced dynamic load-balancing mechanisms that scaled inference workloads automatically based on real-time demand, ensuring stable AI execution under heavy loads.
Observability became another key challenge. With countless AI-driven sessions daily, tracking execution failures across distributed systems required real-time visibility. In response, engineers developed an execution tracing system that mapped every AI request to its processing path, allowing proactive failure detection and debugging. This prevented silent failures and enabled rapid issue resolution at scale.
By optimizing onboarding automation, load balancing, and execution monitoring, Agentforce successfully scaled while maintaining reliability.
How does Agentforce leverage RAG at scale, and what were the biggest challenges in ensuring both precision and recall across structured, unstructured, and external data sources?
Agentforce relies on RAG to enhance AI-driven decision-making by retrieving enterprise-specific knowledge before generating responses. Implementing RAG at Data Cloud scale introduced challenges in multi-source retrieval, query optimization, and ranking intelligence to balance precision and recall efficiently.
One major challenge was ensuring AI agents retrieved only the most relevant information while maintaining high recall. Agentforce addresses this by using multi-tiered indexing, which pre-filters document clusters before executing full-text search. Additionally, entity-based extraction is performed at indexing time rather than query time, reducing computational overhead and improving query optimization.
Another challenge was multi-source retrieval, where Agentforce integrates Data Cloud, API-driven knowledge bases, and external web content. The issue was that different sources had varying levels of accuracy and relevance, making it difficult to surface the best information. To solve this, Agentforce applies ranking intelligence, using context-aware ranking to prioritize real-time enterprise data over generic AI-generated insights, ensuring that retrieved results remain highly relevant and actionable.
Retrieval speed was also a key issue at scale. The system maintains low latency through query batching, embedding-based semantic search, and caching frequent request patterns.
By combining multi-source retrieval, query optimization, and ranking intelligence, Agentforce ensures that RAG remains efficient and scalable for enterprise AI applications.
How does Agentforce handle AI execution failures and ensure reliability at enterprise scale?
Ensuring high availability and fault tolerance in Agentforce requires a multi-layered failure recovery system designed to detect, diagnose, and mitigate AI execution issues in real time.
At the execution level, Agentforce tracks every AI request through an execution monitoring layer, mapping dependencies across workflows. If an AI process fails mid-execution, the system automatically retries tasks based on failure type and system load. If a retry isn’t viable, Agentforce reroutes requests to alternative agents or escalates these to a failover workflow designed to handle mission-critical failures.
At the infrastructure level, Agentforce leverages distributed execution tracing and predictive failure detection, identifying anomaly patterns before these cause disruptions. The system logs failure correlations across AI workflows, refining execution strategies to reduce recurrence of similar issues.
By integrating multi-tiered recovery, adaptive workflows, and AI-driven fault detection, AgentForce maintains enterprise-grade reliability, even under high-load conditions.
What will be the biggest operational challenges in scaling AI observability ?
Ensuring comprehensive AI observability at scale will be a key challenge. With AI workflows becoming more autonomous and interconnected, real-time visibility into execution paths, system health, and failure diagnostics across distributed environments will be essential.
One major challenge will be workflow tracing across multiple AI agents. Unlike current systems, where execution is primarily linear, parallel processing and dynamic task delegation will become more important. Observability tools will need to track agent decision-making in real time, identifying dependencies and potential failure points before these cause disruptions.
Another challenge will be proactive debugging and anomaly detection. The team will need to implement predictive alerting mechanisms that identify workflow slowdowns, API failures, and incorrect AI reasoning patterns before these impact performance.
Scalability will also be critical. As AI-driven processes expand, observability systems must handle exponentially increasing telemetry data without overwhelming engineers with false positives.
To address these challenges, we will need to integrate AI-driven monitoring tools, enabling self-correcting workflows, automated failure recovery, and predictive analytics for real-time system optimization.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.