Most developers begin with the same rush of excitement: the agent writes code, fixes bugs, explains unfamiliar systems, generates tests, and turns vague intent into something that looks runnable. For a moment, it feels like the hard part of software engineering has collapsed. The model can produce in seconds what used to take hours. The demo works. The prototype is impressive. The future feels obvious.
But that early confidence is misleading. We all know that generating code is not the same as delivering safe, integrated, maintainable change.
That distinction is the heart of Agent Coding maturity. Agent Coding is not simply using AI to write code faster. It is the practice of designing, supervising, evaluating, and improving agentic workflows that can plan, act, verify, and integrate work across the software delivery lifecycle. A mature agentic workflow also requires proof of work: at every Ralph loop, the agent must produce objective empirical evidence that it did what it was instructed to do at every stage in every environment. It should not simply claim completion. It should provide empirical evidence: tests run with coverage values, implemented features mapped to matching functional test cases, behaviors tied to assertions or observed outputs, inspected logs with relevant log lines or patterns, discovered failures with reproduction steps and error output, and incomplete tasks with clear explanations for why they could not be completed.
At the beginning of the journey, the developer is focused on what the model can produce. At the end of the journey, the developer is focused on how the entire engineering system must change when agents can do meaningful work and prove that work reliably.
This matters for individual careers, and it matters for the organization. Developers everywhere are moving through this curve right now. The skill is becoming part of the global engineering baseline. The question is not whether developers will use coding agents. They already are. The question is whether we will progress deliberately from experimentation to mastery while we have the time and space to do it well.
This model is based on what I have experienced in my own learning of Agent Coding, what I have observed in the data, through feedback, and through conversations with nearly one hundred developers. Experiences will vary. Not every developer or team will move through these stages in exactly the same order, and some stages may overlap. Stage 9 is not the end of the journey; it is simply the farthest stage I have seen people reach so far. That will likely change soon.
The important pattern is that each stage builds on the lessons of the prior stage. Tool euphoria creates the realization that coding has become easier. Easier coding creates the temptation to convert every problem into code. That expansion creates proliferation. Proliferation creates the need for reliability. Reliability creates the need for standardization. Standardization creates the foundation for orchestration. Orchestration creates the need to manage many agent teams without drowning in context and burnout. Managing agent managers creates the foundation for scheduled and event-driven loops. Those loops create the foundation for trusted automation and autonomy. Trusted automation and autonomy expose the limits of the current PDLC and force process redesign.
The journey so far has nine stages:
- Tool Euphoria
- Everything Becomes Code
- Skills Proliferation
- Reliability Reckoning
- Standardized Tooling and Workflows
- Agent Team Orchestration
- Manager of Agent Managers
- Scheduled, and Event-Driven Coding
- Trusted Automation and Autonomy
1. Tool Euphoria
The first stage is the moment of discovery. A developer uses an AI coding agent and sees immediate leverage. The agent drafts code, explains a stack trace, writes a test, or produces a plausible implementation from a rough instruction. The experience is powerful because it compresses the distance between intent and artifact.
At this stage, confidence is high and maturity is low. Often the tool is judged by its best moments: the impressive demo, the passing unit test, the prototype that appears faster than expected. The center of gravity is individual productivity. The question is, “How much faster can I code?”
That question is useful, but incomplete. It points at the inner loop of development: writing, editing, and debugging code. Agent Coding begins there, but it does not end there. The lesson of this stage is that speed is real, but speed alone is not maturity.
2. Everything Becomes Code
The second stage begins when developers realize that coding has become cheap enough to apply in places where it previously did not seem worth the effort. Small automations become scripts. Manual checklists become tools. Repetitive investigation becomes code. One-off analysis becomes a reusable workflow. Documentation cleanup, migration planning, test generation, bug reproduction, data inspection, and environment setup all start to look like coding problems.
This is a powerful shift. It expands the surface area where developers can apply leverage. When the cost of creating software drops, the number of things worth expressing as software increases.
But this stage also creates a new failure mode. Developers can become too quick to turn every problem into a coding problem. Some problems require product judgment, process clarity, organizational alignment, domain expertise, or better requirements. Code can accelerate work, but it cannot replace understanding.
The lesson of this stage is that easier coding expands what is possible, but it also increases the need to choose carefully what should be automated, encoded, or delegated to agents.
This stage helps explain why Skills Proliferation happens next. Once everything starts to look codable, developers naturally begin creating reusable skills, scripts, wrappers, and workflows for every recurring problem they encounter.
3. Skills Proliferation
The third stage is the explosion of local invention. Developers create skills, plugins, workflows, conventions, context, and scripts. This stage can look chaotic because it is chaotic. Everyone is experimenting. Everyone has a trick. Everyone has a demo. Everyone has a workflow that worked once and might work again and definitely works on their machine.
This proliferation is not a failure. It is part of the learning process. Organizations need exploration before they can standardize. But the cost becomes visible quickly. New adopters face a discovery tax. Teams struggle to tell the difference between useful skills and clever-looking artifacts. People share instructions that are untested, redundant, too specific, or actively harmful in a new context.
The mistake at this stage is believing that more skills automatically mean more capability. In reality, unvalidated (read I build an eval suite) agent artifacts can be and likely add negative value. A large pile of skills does not create maturity. It creates inventory. The lesson of this stage is that invention must eventually give way to evaluation.
Example: lots of skill listings https://git.soma.salesforce.com/pages/scg-innovation/ai-catalog/ are popping up. If you wrote an eval set for it, put it in the AI Expert Suite so everyone knows it’s proven to add value.
4. Reliability Reckoning
The fourth stage is the valley. Developers begin to notice the gap between a good answer and a reliable workflow. The agent produces code, but the code is sloppy. It misses architectural constraints. It assumes requirements that were never stated. It writes tests that prove too little. It succeeds on a small example and fails when connected to a real system.
This stage can feel discouraging, but it is the most important transition in the maturity curve. It is where developers stop asking, “Can the agent generate code?” and start asking, “What is wrong with this workflow?” Trust begins with proof of work and independent validation, enabling a trusted closed loop. The agent needs to demonstrate, with empirical evidence, that it did what it was asked to do rather than merely asserting that it is finished. A separate validator, check, test harness, reviewer, or agent should then challenge that evidence before the workflow is trusted.
The reliability reckoning reveals that Agent Coding requires the same discipline as any other engineering system: evaluation, repeatability, review, integration, ownership, proof of work, and feedback loops. It also reveals that many of the inputs we give agents are not good enough. User stories are too small. Requirements are ambiguous. Non-functional expectations are missing. Architectural context lives in people’s heads. The agent is not creating these problems; it is exposing them.
This is the stage where confidence drops. That drop is healthy. It replaces inflated confidence with grounded judgment. The lesson of this stage is that trust cannot be assumed; it must be earned through evidence.
5. Standardized Tooling and Workflows
The fifth stage begins when teams stop treating every local invention as equally valuable. The organization starts to curate. Skills are tested. Workflows are evaluated. Scorecards appear. Repositories and CI/CD processes become part of the agent tooling lifecycle. The question shifts from “Who has a clever skill?” to “What has been proven to work?”
This is where confidence begins to rebuild. Not because developers trust agents blindly, but because the surrounding system becomes more trustworthy. Standardized tooling lowers the discovery tax. It reduces duplication. It gives new adopters a path into productive use without forcing them to sort through every local experiment. It also creates shared expectations for proof of work and independent validation: what evidence an agent must provide, what checks count, which validator is responsible, and what artifacts are required before a workflow is considered complete.
Standardization also changes developer behavior. Once trusted tooling exists, developers care less about inventing individual skills and more about composing reliable workflows. The unit of value moves from the isolated prompt to the tested primitive. The lesson of this stage is that repeatable capability depends on shared, validated foundations.
[TODO: Insert example of standardized skill intake, scorecards, repositories, or CI/CD validation. AI Suite intake and CI/CD pipeline.]
6. Managers of Agent Teams
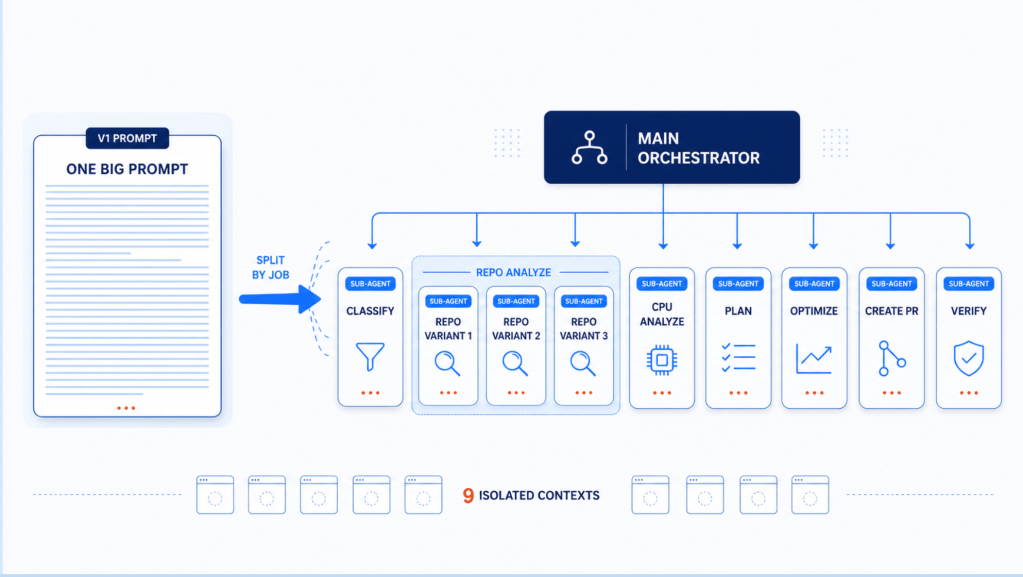
The sixth stage is the shift from individual agent sessions to managing many Agent Teams across parallel sessions. Agent Teams are a Claude Code feature that every developer should be using. This is non-negotiable for serious Agent Coding. At this point, the developer is no longer asking one model to perform one task. The orchestrator agent is designing coordinated execution: one team member plans, several implement, others review and validate, others test, another investigates failures, another validates the work was done correctly, and finally another merges the worktrees.
The point of this stage is parallelism of work. Agent Teams take a plan and break it into parallelizable tasks, including tasks that touch the same file or related files. Each team member can operate in its own git worktree, with its own session settings, context, model, skills, and instructions. That matters because different tasks need different configurations. A planner, implementer, validator, test writer, failure investigator, and worktree consolidator should not all be forced into the same context window, the same role, or the same session posture.
This is where Agent Coding starts to change the shape of execution. I have run workflows with up to twenty team members helping implement forty new features from Plan Mode across fourteen worktrees, then spun up a validator team member, and finally created a worktree consolidator team member to bring the outputs together. That kind of execution is not about making one agent smarter. It is about turning one large plan into many coordinated streams of work that can move at the same time. iTerm2 for the win.
Agent Teams also show us whether we are working at the right level. If the typical story cannot spin up a meaningful team for a meaningful period of time, the work is probably sliced too small. That is not a virtue; it is a sign that the unit of work was designed around the limits of human execution, not agent execution. A story that is too small to support an Agent Team may just be a task. As Agent Coding matures, the right unit of work shifts from tiny tickets toward larger units of product intent that agents can plan, implement, validate, and consolidate.
Each loop needs proof of work and independent validation. A planning team member should show how it decomposed the work. An implementation team member should show what changed and which task it addressed. A testing team member should show what it ran, what passed or failed, and what coverage or behavioral evidence was produced. A validator team member should challenge the output independently. A worktree consolidator team member should show what it merged, what conflicts it resolved, and what validation was run after integration. Critically, validation should not depend only on the team member that performed the work. Agent Teams need separation between doing, checking, accepting, and merging.
Agent Teams are also where the distinction between AI-assisted coding and Agent Coding becomes clear. AI-assisted coding helps a developer produce code. Agent Coding designs a system in which agents participate in the software delivery lifecycle with defined roles, boundaries, checks, feedback, parallel execution, and integration paths. The lesson of this stage is that scale comes from coordinated systems, not from a single smarter session. Once developers have reliable tools and workflows, the next unlock is learning to decompose work, assign it to specialized Agent Teams, run those teams in parallel, validate them independently, and consolidate the result safely.
Here is the context that I use, it has specific instructions for Agent Team usage as well as instructions for configuring Agent Teams.
7. Manager of Agent Managers
The seventh stage emerges from the pressure created by orchestration. Once a developer is running multiple parallel sessions of agent teams, the bottleneck shifts again. The problem is no longer simply getting agents to work in parallel. The problem is that the developer must maintain context across those sessions, design the workflows inside each one, track progress, handle interrupts, and decide when the work is ready to integrate.
This stage introduces a command-center model. The developer should not need to live inside every session. The system should show what work is running, which agents are assigned, what state each session is in, what tasks are being assigned and worked, what evidence has been produced, which validations have passed, and where human input is required. The operator intervenes when there is an interrupt, an ambiguity, a safety concern, a failed validation, or a completed session ready for review.
The goal is to reduce orchestration overhead without losing control. The developer still owns judgment, prioritization, and acceptance, but the mechanics of staffing, launching, monitoring, and resuming agent teams become reusable. This is also where agent memory becomes practical rather than abstract. The system remembers not just facts, but workflows: how a certain kind of task should be decomposed, which agents should participate, what proof of work is required, and what independent validation should be run before completion.
The lesson of this stage is that parallelism creates management overhead, and management overhead must itself be systematized. To scale Agent Coding, developers need to stop manually rebuilding orchestration for every task and start operating reusable agent-team manager systems.
The best orchestrator I’ve seen [so far] is ClaudeUnleashed. I won’t code without it.
8. Scheduled, and Event-Driven Coding
The eighth stage moves Agent Coding from purely interactive use to triggered initiation. Agents are not only invoked manually; they run because something in the system tells them it is time to run. A schedule fires. A dependency changes. A test fails. A vulnerability appears. A bug is filed. A release branch is cut. A service emits a signal that work is needed. Another agent session emits an event.
This is a major maturity step because it changes when software work begins. Agent Coding is no longer limited to moments when a developer opens a tool and asks for help. Agentic workflows become part of the operating fabric of engineering. Some work starts overnight. Some work starts continuously. Some work starts when the system detects a condition that should trigger investigation, preparation, repair, or review.
The key shift is from “I asked the agent to do this” to “the system knows when this work should begin.” At this stage, agents may watch, triage, gather context, generate an initial plan, identify likely files or owners, assemble evidence, and prepare a proposed path forward. The emphasis is not yet end-to-end autonomy. The emphasis is reliable initiation: making sure the right work starts at the right time, with the right context, under the right constraints, and then pauses for review before proceeding further.
Engineering teams must think carefully about permissions, observability, rollback, cost, scheduling, ownership, proof of work, and safety. Scheduled and event-driven work must be visible and governable. Every loop should leave behind empirical evidence of what happened, why it was triggered, what context it used, and what result it produced. That evidence should be independently validated before the output is accepted or allowed to trigger further work.
The lesson of this stage is that triggered initiation is only valuable when it is observable, governable, independently verifiable, and reviewable before execution continues.
9. Trusted Automation and Autonomy
The ninth stage is trusted automation and autonomy. Agents do not only start work because a trigger is fired; they are allowed to carry that work end-to-end within defined guardrails before a human review. A bug is filed, a story is created, a vulnerability appears, or a test fails, and an agent can reproduce the problem, inspect relevant code, propose a plan, create a patch, generate tests, run checks, collect proof of work, prepare a review summary, and package the result for human acceptance.
The word “trusted” matters. Automation without trust is an unchecked risk. Autonomy without validation is confidence theater. Trusted automation and autonomy depend on the prior stages: standardized tooling, orchestration, manager-of-agent-managers systems, guardrails, evaluation, proof of work, independent validation, observability, and clear escalation paths. The agent can carry more of the work because the system around the agent has matured.
This stage changes the developer’s role again. The developer becomes less of a line-by-line code producer and more of a constant session operator. The developer becomes a domain expert, reviewer, system designer, and owner of non-functional correctness. The agent may move the work forward, but the developer remains responsible for whether the change fits the architecture, respects operational constraints, integrates safely, and serves the product intent.
Trusted automation and autonomy are earned by the system, not granted by enthusiasm. The agent must leave behind evidence that a human or independent validator can inspect, reproduce, and challenge. It must know when to stop, when to escalate, when to ask for clarification, and when not to proceed.
The distinction from Stage 8 is where the human review happens. In Stage 8, the system initiates the work, performs triage or planning, and pauses for review before proceeding. In Stage 9, the agent is trusted to carry the work through the loop and then present the completed output, evidence, and validation results for review.
The lesson of this stage is that autonomy is not measured by how much the agent does alone. It is measured by how safely, visibly, and verifiably the agent can carry work forward before human acceptance.
Cross-Cutting Evolution: PDLC Process Redesign (“Burn It All Down”)
PDLC Process Redesign is not the final stage of Agent Coding. It is the organizational work that runs alongside the entire learning curve. Each stage exposes a different class of process debt, and the organization has to decide whether to tolerate that debt, route around it, or fix it.
Tool Euphoria exposes the gap between generating code and shipping safe change. Everything Becomes Code exposes how much manual work was never automated because coding used to be too expensive. Skills Proliferation exposes the absence of shared standards and evaluation. Reliability Reckoning exposes weak requirements, weak tests, missing context, and unclear definitions of done. Standardized Tooling exposes the need for shared primitives and lifecycle management. Agent teams expose coordination and context-management costs. Manager-of-agent-managers systems expose the need for command centers and reusable orchestration. Scheduled and event-driven coding exposes the need for observable triggers, permissions, and governance. Trusted automation and autonomy expose whether the PDLC can actually support agents doing meaningful work safely.
This is the “burn it all down” thread running through the curve. Not because teams should discard discipline, safety, or engineering judgment, but because much of what we previously assumed to be true or hard may no longer be true in the same way. The people who reach later stages often experience a specific frustration: the agents are ready to move faster, but the surrounding systems keep fighting progress. That frustration is what gives the phrase “burn it all down” its force.
The work is not to automate yesterday’s process. The work is to decide which parts of yesterday’s process still deserve to exist, then actually change the ones that do not. That may mean changing the intake process, the test strategy, the review model, the ownership boundaries, the infrastructure assumptions, or the definition of what “done” means when agents participate in the work.
The lesson is that PDLC redesign is not a destination after autonomy. It is a continuous organizational responsibility. The more capable agents become, the less tolerable old bottlenecks become. Mastery is not recognizing that the system is broken; that recognition happens early. Mastery is taking responsibility for fixing it as the curve advances.
The Agent Coding Learning Curve
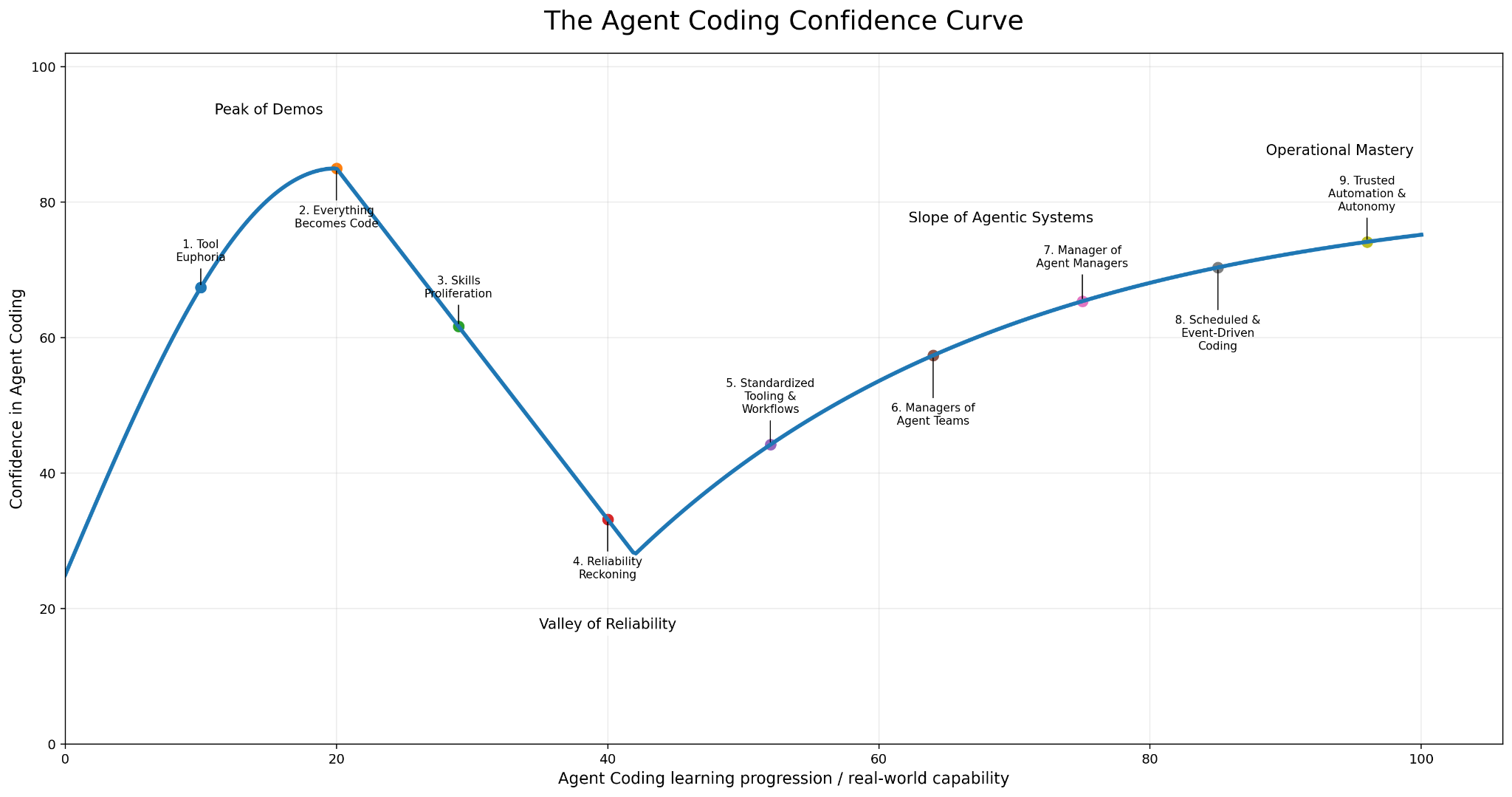
The chart is a visual analogy to the familiar Dunning-Kruger-style confidence curve. It is not meant as a psychological claim about individual developers. Instead, it uses the shape of that curve to illustrate a common learning pattern in Agent Coding adoption.
In the early stages, confidence rises quickly because the visible output is impressive. Developers see agents generate code, solve local problems, and accelerate small tasks. This creates the “Peak of Demos.”
Confidence then drops during the Reliability Reckoning, when developers encounter the limits of unstructured AI use: brittle outputs, missing context, weak tests, architectural gaps, ambiguous requirements, and inconsistent workflows. This is the “Valley of Reliability.”
Confidence rebuilds as teams introduce tested tooling, standardized workflows, orchestration, manager-of-agent-managers systems, scheduled and event-driven initiation, and trusted automation and autonomy. The far side of the curve represents operational mastery: the point at which teams stop asking only how agents can make coding faster and start asking how to operate reliable agentic systems.
The purpose of the chart is to make the journey visible. It reminds developers and leaders that the valley is not failure. It is the transition from enthusiasm to mastery. The stages should be read as an evolving model based on current experience and conversations with dozens of developers, not as a final map. Stage 9 marks the farthest point I have seen this journey reach so far, not the endpoint of Agent Coding maturity.
The Career and Organizational Imperative
Agent Coding maturity is not optional. Developers worldwide are learning these practices now. Some will remain at the level of tool euphoria and prompt tricks. Others will learn to design reliable agentic systems, evaluate outputs, supervise autonomy, and redesign workflows around continuous agent contribution.
That second group will have a different kind of leverage.
For individual developers, the opportunity is to deeply understand this way of working. The durable skill is not knowing one tool or one prompt. The durable skill is understanding how to turn agents into reliable engineering collaborators: how to provide context, define constraints, demand proof of work, require independent validation, evaluate evidence, design feedback loops, and integrate agent output into real systems.
For the organization, the opportunity is to move together. If every developer has to rediscover the same lessons alone, progress will be slow and uneven. If we standardize what works, share proven patterns, invest in orchestration, build trusted autonomy, and redesign the processes agents expose as broken, we can turn individual experimentation into organizational capability.
We have time to do this now. That time should be used intentionally. The organizations that master Agent Coding will not be the ones with the most skills, the cleverest prompts, or the most impressive demos. They will be the ones that move through the maturity curve with discipline and redesign their engineering systems around what agents make possible.
Conclusion
Agent Coding begins with speed, but it matures into systems thinking. The journey starts when a developer sees an agent produce code and feels the future arrive all at once. It progresses through code-first expansion, chaos, disappointment, standardization, orchestration, manager-of-agent-managers systems, scheduled and event-driven initiation, trusted automation and autonomy, and continuous PDLC redesign. Each stage teaches a different lesson. Each stage raises the bar. Each stage turns the lesson of the prior stage into the foundation for the next one.
The lesson of the curve is simple: early confidence is easy. Mastery is earned. To master Agent Coding, we must stop treating agents as novelty tools and start treating them as participants in a redesigned software delivery system. In that system, agents do not get credit for confident claims; they earn trust by producing empirical proof of work at every loop and by having that proof independently validated. That is the work ahead, and it is work worth doing deliberately.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.