By Makarand Bhonsle, Christina Abraham, and Jayesh Govindarajan.
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today’s discussion features Makarand Bhonsle, a software engineering architect at Salesforce, whose team is developing Agentic Memory within Agentforce to provide durable, governable memory for enterprise agents at massive scale.
Explore how the team addressed the inherent limits of stateless agents with small context windows by introducing Agentic Memory as a durable, structured data layer, and how they tackled the formidable challenge of ensuring its accuracy, governability, and reliability at enterprise scale through confidence scoring, write and read gates, and hybrid semantic validation.
What is your team’s mission in addressing the limitations of stateless AI agents within enterprise workflows?
The fundamental objective is to elevate agents beyond fleeting, stateless exchanges, transforming them into dependable collaborators over extended periods. Across the industry, most AI agent architectures operate within a restricted working space, treating each interaction in isolation. This design severely curtails their capacity to retain user context, past decisions, and crucial enterprise constraints across various business workflows. Consequently, applying these architectures reliably becomes increasingly difficult beyond basic, single-turn interactions.
To overcome this limitation, the team prioritizes equipping agents with a robust, durable memory foundation. This memory persists across interactions, yet remains governable and transparent. Agentic Memory is a core platform capability and allows agents to use relevant information in the chat without referring back to chat history and other large consumer datasets.
While short-term context remains tethered to the active session, enabling agents to reason effectively in the immediate moment, long-term memory is linked to a persistent profile graph. This graph endures across sessions and distinct communication channels. This strategic approach ensures continuity without compromising trust, auditability, or enterprise control. The profile graph refers to an individual profile within Salesforce.
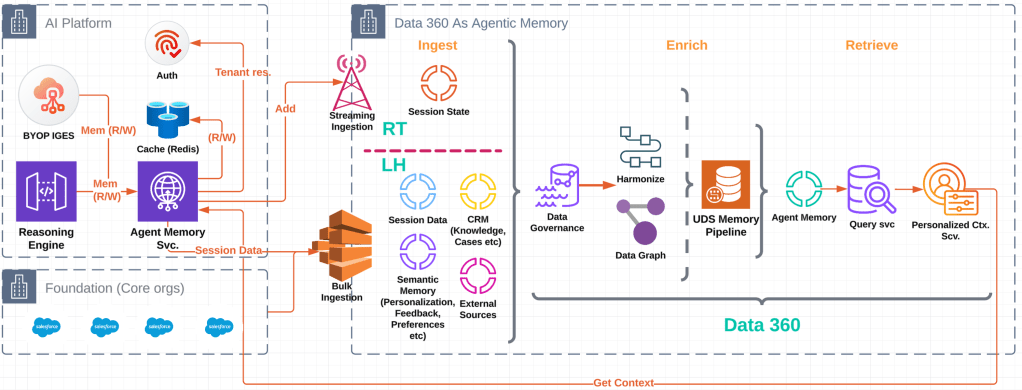
The Agent Memory Platform powered by Data 360.
What constraints of small context windows and stateless execution prevent today’s agents from operating reliably over time?
In the realm of stateless agent designs, agents operate with a severely restricted view of information. Older chats, emails, and CRM records simply vanish from their scope as conversations evolve. Furthermore, this execution model consistently resets an agent’s working context with each interaction, even when the user and the task at hand remain constant. During extended interactions, these limitations often lead to repetitive questioning, inconsistent behavior, or noticeable gaps in the retained context.
Industry efforts to mitigate this by injecting vast quantities of raw historical data into prompts only introduce further latency, increase costs, and generate unnecessary noise. Obsolete or irrelevant information actively distracts the model, diminishing its reasoning capabilities. Without explicit memory records, updating or removing facts as individuals change roles, preferences, or circumstances becomes a formidable challenge, allowing outdated information to resurface persistently.
Agentic Memory directly confronts these constraints by externalizing memory into structured records. These records come with explicit lifecycle control. This design enables agents to retain stable facts, adapt their understanding as conditions shift, and effectively discard information that no longer holds relevance.
Why does treating memory as prompt text break down at enterprise scale, and what architectural shift was required to overcome that?
Prompt-based memory approaches frequently fail at an enterprise scale due to their inherent lack of structure, governance, and explainability. When memory exists solely as transient prompt text, auditing an agent’s knowledge, enforcing access controls, or explaining decision paths becomes increasingly difficult. At the enterprise level, these deficiencies severely limit the capacity to meet trust, governance, and compliance expectations.
To rectify this, the team re-conceptualized memory as a core platform capability, rather than a mere prompt-side technique. Memory now resides in a real-time data layer, distinctly separate from prompts, and possesses explicit structure and lifecycle controls. Short-term session context is isolated from long-term memory, which anchors to a profile graph. Raw signals pass through a pipeline that determines whether to add, update, delete, or disregard each memory candidate.
This fundamental shift makes memory inspectable, governable, and explainable. It also allows for seamless integration with retrieval, planning, and tool execution across various agents.
How does adaptive context and session-level tracing help make agent behavior governable and explainable at enterprise scale?
Salesforce serves as the authoritative record for enterprise data. However, effective agent automation needs context that evolves with interactions. Adaptive Context allows agents to dynamically refine, prioritize, and prune information in real time, moving beyond static inputs. This helps agents highlight the most relevant signals from conversations, documents, and enterprise systems as their tasks progress.
During execution, agents create structured reasoning and decision traces. These traces capture how choices are evaluated and which tools or actions are selected. They provide an evidence-backed history, explaining an agent’s actions, which supports accurate auditing and governance. To enhance this visibility, a standardized session trace model organizes session activity, capturing the agent’s complete journey.
Over time, these traces build a relational history connecting decisions to enterprise outcomes. By referring to successful past sessions in similar situations, agents can base future behavior on proven patterns. This remains fully inspectable, auditable, and consistent with organizational policies.
What makes enterprise-grade agentic memory especially difficult to build correctly at scale?
The most challenging aspect involves determining what information merits retention and ensuring its accuracy over time. Storing an excessive amount of data quickly generates noise, while saving too little limits practical utility. Episodic memory introduces additional complexity because order and timing are crucial. Agents must preserve the precise sequence of events to reason accurately.
Conflicts between various sources present an additional risk. Enterprise systems may contradict conversational signals, and memory must represent uncertainty rather than false certainty. Mixing short-term context with long-term memory can also lead to private or one-time information persisting incorrectly across multiple sessions.
The team tackles these challenges through strict write and read gates, confidence scoring, memory compaction processes and comprehensive source tracking. Hybrid matching combines similarity search with semantic checks to prevent duplication and drift as memory evolves.
What performance and cost constraints shaped how Agentic Memory retrieval was designed?
Every agent turn operates under strict latency and cost constraints. If memory retrieval is slow, the agent appears unresponsive. Frequent invocation of large models quickly escalates costs, becoming unsustainable at scale.
The solution employs compact, structured memory records with precomputed embeddings to facilitate rapid similarity search. Only a small, task-relevant subset of memory is retrieved per interaction, with caching applied to active sessions. Smaller models manage inexpensive steps such as candidate extraction and validation, while larger models are reserved for more complex reasoning when necessary.
This design enables agents to leverage long-term memory without sacrificing responsiveness or efficiency in real-time enterprise environments.
What scientific and engineering challenges arise when modeling episodic, long-term, and short-term memory in agents?
Episodic memory is inherently temporal. Agents must preserve event order and understand how outcomes relate across time, otherwise they risk applying incorrect lessons. Short-term context must also remain distinct from long-term memory to prevent the persistence of transient or sensitive information.
Uncertainty further complicates the modeling process. Different sources may disagree, and the agent must represent confidence rather than assuming correctness. Measuring memory quality also presents a challenge, requiring evaluation across correctness, freshness, helpfulness, and safety, rather than relying on a single metric.
To address these constraints, the team designed a memory model that supports long-term reasoning while respecting temporal boundaries and uncertainty. Time-bounded episodic chunks, a confidence-first design, and replay-based evaluation help ensure memory remains useful without becoming rigid or unsafe.
Further, we consider data sources beyond just agentic conversations. For example, human agent chats in Service Cloud (from the livechattranscript Salesforce object) and Einstein Bot conversations (from the Bot Conversations Data model) can feed into the memory derivation pipeline. We also include data brought in via the zero-copy connector.
These memory derivation candidates are pre-defined as metadata and fed into the derivation pipeline. This aligns with industry memory solutions, where the system extracts memories or insights from an actor-text-blob tuple or actor-text-actor triplet. The text-blob can come from various sources like agentic, bot, or human conversations, or documents such as Excel or PDF files.
This approach means data from all Data 360 connectors are potential memory candidates. Decoupling data sources makes the derivation pipeline a flexible, extensible enterprise memory platform. Memories are derived from diverse sources, not just conversations, and stored in a standard memory object.
What early R&D approaches show the most promise for keeping agentic memory reliable and governable over time?
Memory is currently being approached as clean, structured data, complete with explicit fields for type, time, source, confidence, and lifecycle controls. Write gates are implemented to ensure that only high-quality candidates become part of this memory. Concurrently, read gates are utilized to limit retrieval exclusively to records relevant to the task at hand.
Hybrid validation is a technique that combines vector similarity with meaning checks. This method aims to prevent both duplication and drift within the memory system. Episodic memory undergoes summarization over time, a process designed to preserve signal while simultaneously reducing noise. Furthermore, trusted enterprise records are prioritized over what might be considered more casual conversational signals.
To assess the system’s performance, replay testing is employed to evaluate correctness, freshness, and safety. These techniques, when combined with a cost-aware model selection process, collectively support the development of long-running, enterprise-grade agentic memory, all without sacrificing trust or reliability.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.