By Sanjeev Chhabria, Aditya Kamath, Derek Donaldson, and Sandeep Siroya.
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today we spotlight Sanjeev Chhabria, Vice President of Engineering, who leads the Salesforce Edge (Trusted Perimeter Platform) team, building and operating global perimeter services that handle 1.5 trillion requests and approximately 23 petabytes of traffic monthly.
Explore how the team reduced global rollback time from eight to twelve hours to roughly ten minutes, re-architected Kubernetes deployments and autoscaling for true blue-green operation, and automated traffic cutover and TCP connection draining to preserve four-nines availability during worldwide rollback events.
What is your team’s mission as it relates to building and operating Salesforce Edge as a global, high-availability service?
Our purpose is to manage Salesforce Edge as the reliable entry point for Salesforce application traffic. We ensure consistent security, performance, and uptime through this system.
Salesforce Edge, our dependable perimeter platform with 21+ points of presence around the globe and expanding, resides directly within the data path for inbound requests for Salesforce Core and some non-Core services. It enforces security protocols, diminishes threats, and directs traffic dependably to downstream services. We deliberately manage Edge as a consolidated perimeter instead of numerous independent regional deployments. This strategy streamlines architecture, minimizes redundant logic, and decreases operational burden while enhancing uniformity across environments. Centralized enforcement fortifies blast-radius containment and facilitates consistent controls. Operating as a singular platform allows for quicker incident response without requiring region-by-region coordination.
Given that Edge is a global service that fronts a large amount of Salesforce traffic, it is imperative to avoid any unnecessary downtime. Any compromise directly affects customer access to Salesforce. This fundamental truth promotes a strong inclination towards automation, predictability, and swift recovery mechanisms integrated directly into the platform’s deployment and operation.
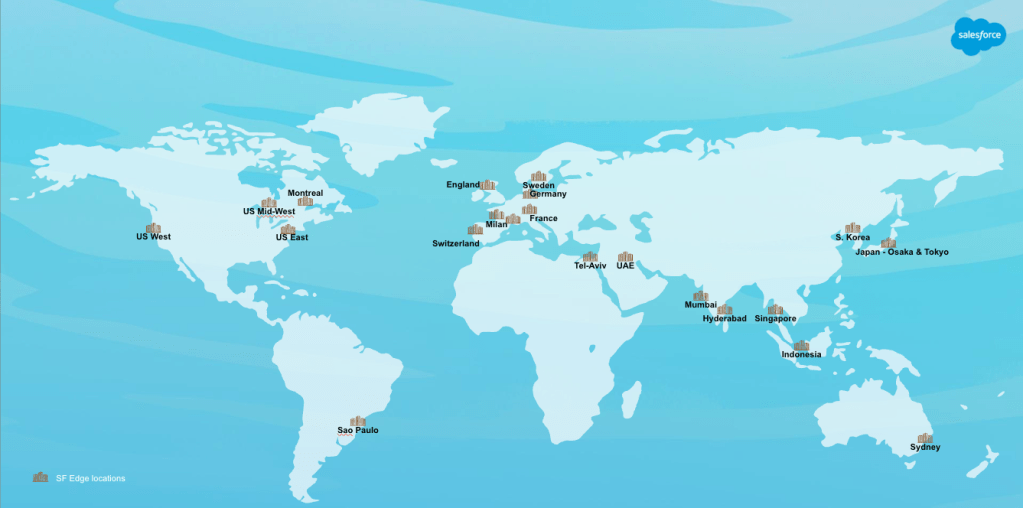
Salesforce Edge worldwide network as of January 2026.
What reliability and release-engineering constraints made multi-hour global rollbacks unacceptable for Salesforce Edge?
The primary limitation was time. The current rollback method could not satisfy recovery needs. Individual Edge pods, running on EKS clusters, require several minutes to initiate, and pod creation is deliberately staggered to prevent overwhelming Kubernetes clusters and the Edge control plane. The deployment pipeline itself also introduces a delay before traffic reaches new pods.
Deployments were executed in regional phases for safety. While effective for roll-forward releases, this method became a weakness during rollback. Reverting a single region could take nearly an hour, and sequential rollback across the global fleet extended total recovery time to the eight-to-twelve-hour range.
Considering these limitations, reducing rollback time within the existing architecture was impractical. We required an approach where rollback did not necessitate rebuilding or restarting capacity. This led us to a blue-green model where the prior version already operates at full scale as a warm standby. Rollback then transforms into a controlled traffic redirection rather than a redeployment. This change reduced global rollback from eight to twelve hours to ten minutes.
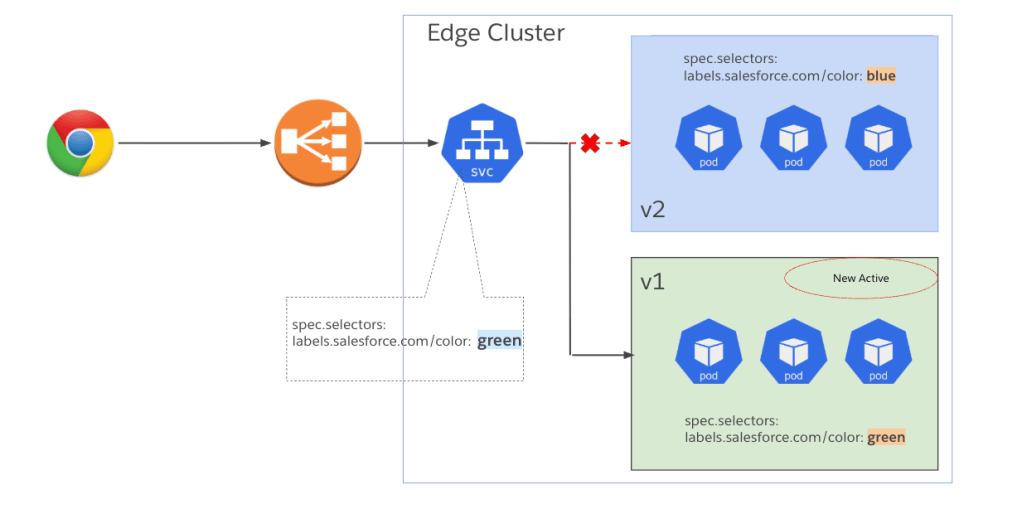
SF Edge data path switch from blue to green clusters.
The above diagram depicts the blue and green edge clusters and a rollback taking place. The label (green or blue) in the Kubernetes deployment controls the active data path. In the diagram, we have decided to rollback from version v2 to v1, which involves modifying the color label to green in this case, which will cause traffic to start landing on the v1 version of the software.
What architectural limitation did you encounter when evaluating existing Kubernetes blue-green tooling for a globally distributed edge service?
Evaluating existing Kubernetes blue-green tools led us to Argo, an open-source Kubernetes deployment system. It is widely used for blue-green and progressive delivery workflows. While effective for many application workloads, its underlying assumptions do not apply to a global edge service.
Argo anticipates traffic switching at a layer-seven routing tier, but Salesforce Edge functions as the routing layer itself. It also lacks native support for maintaining two fully scaled global deployments simultaneously. Furthermore, it does not coordinate autoscaling behavior across blue and green fleets. Instantaneous cutovers at this scale can also disrupt load-balancing behavior.
These limitations meant that adopting Argo would have introduced unacceptable risk. Therefore, we implemented equivalent workflows directly on native Kubernetes constructs. We used existing deployment automation to achieve this. This approach provided precise control over deployments, scaling behavior, and traffic transitions without inheriting incompatible platform assumptions.
What Kubernetes system-design constraints shaped how you implemented blue-green deployments at global edge scale?
Deployment and rollback mechanics were established, making autoscaling the next critical limitation. Kubernetes does not offer a native blue-green deployment primitive, so we explicitly designed one. We introduced parallel blue and green deployments, ensuring only one receives production traffic at any given moment. The main challenge involved maintaining identical scaling for both deployments so either could immediately handle full load.
Autoscaling presented the most complex aspect. Our Horizontal Pod Autoscaler scales based on the average CPU utilization of the request-processing container. During blue-green operation, traffic might split between deployments. This would typically cause each to scale independently, resulting in insufficient capacity during cutover.
To resolve this, we adjusted the autoscaling calculation. It now evaluates CPU utilization across both blue and green deployments and scales based on the higher value. The same calculation is used by the blue and green horizontal pod autoscalers, resulting in the same number of desired pods for both deployments. This guaranteed capacity parity at all times. We also updated the deployment pipeline. It now determines the active color through service labels, deploys only the inactive color, and promotes it after validation by updating the service.
What traffic-management constraints did you face minimizing customer disruption during a worldwide rollback?
Traffic cutover faced limitations due to long-lived TCP connections. Even after updating Kubernetes service labels, existing connections stayed with their original pods until natural termination. At edge scale, these connections can last for hours, which is unacceptable during an emergency rollback.
To fix this, we implemented explicit connection draining. After redirecting traffic at the service level, we launch a Kubernetes job. This job securely connects to each pod using mutual TLS and issues TCP drain commands. This forces connections to close gracefully, so clients immediately reconnect to the correct deployment.
This method replaces unpredictable organic connection churn with controlled traffic migration. Most clients reconnect quickly. This allows traffic to converge on the rollback target within minutes and enables global rollback completion well within the recovery window.
What availability constraints did operating a four-nines, petabyte-scale edge service impose on recovery time?
With four-nines availability, the margin for error is extremely small. The entire annual downtime budget measures in minutes, not hours. Prolonged degradation from faulty releases can quickly exhaust that budget.
Before blue-green rollback, recovering from a bad release could consume a significant portion of the annual availability allowance in a single incident. Maintaining a fully scaled warm standby fundamentally changed that dynamic. Once a rollback decision happens, recovery becomes a rapid traffic redirection rather than a prolonged rebuild.
This capability has already proven critical. During a recent severity-one incident, we rolled back globally fast enough to restore service before escalation to a severity-zero outage. Automated rollback now acts as a safety net that materially limits customer impact when failures occur.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.