By Kunal Pal and Krista Hardebeck.
In our Engineering Energizers Q&A series, we showcase the engineering minds driving innovation across Salesforce. Today, we introduce Krista Hardebeck, Regional Vice President of Forward Deployed Engineering (FDE), whose team collaborated with a large multi-brand specialty retailer to launch their initial production Agentforce service experience on an accelerated timeline. This effort involved optimizing an evolving architecture, aligning multiple clouds, and establishing the groundwork for brand-specific conversational AI within a complex enterprise environment.
Discover how the team restructured deterministic and LLM-driven responsibilities to resolve early inconsistencies, reduced multi-stage reasoning latency by approximately 20 seconds through consolidated model and Data 360 execution, and designed a multi-brand architecture capable of supporting differentiated tone and voice without compromising accuracy or maintainability.
How does your FDE team support large multi-brand enterprises as they adopt Agentforce for their first production agents?
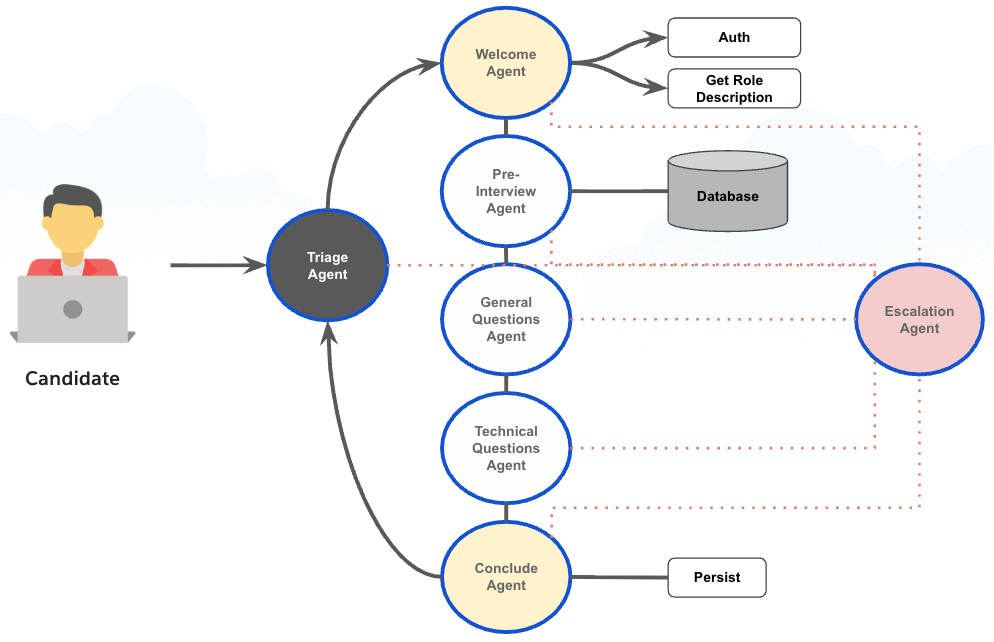
Our mission started with validating the first production agent. This agent delivered reliable, business-aligned value for the customer’s initial brand. For this specific retailer, the team ensured the service agent handled high-volume order interactions with consistent accuracy and a clear link to operational benefit. Establishing this trust proved essential for expanding Agentforce across additional brands, each having its own identity and requirements.
As the engagement progressed, the mission broadened to support more advanced conversational experiences under fixed timelines. The retailer aimed to move beyond basic service workflows. They sought to explore new forms of interactive AI that could showcase emerging capabilities at enterprise scale. Meeting these expectations required stabilizing early patterns, aligning data sources, and ensuring the architecture supported future scenarios without rework.
Across all phases, our mission remained consistent. We established a durable technical foundation. We ensured the earliest agents demonstrated clear and repeatable value. We also enabled the organization to scale Agentforce with confidence across a diverse multi-brand portfolio.
What early architectural and prompt-design challenges surfaced during diagnostic work, particularly around balancing deterministic logic with LLM-based reasoning and clarifying data-flow boundaries?
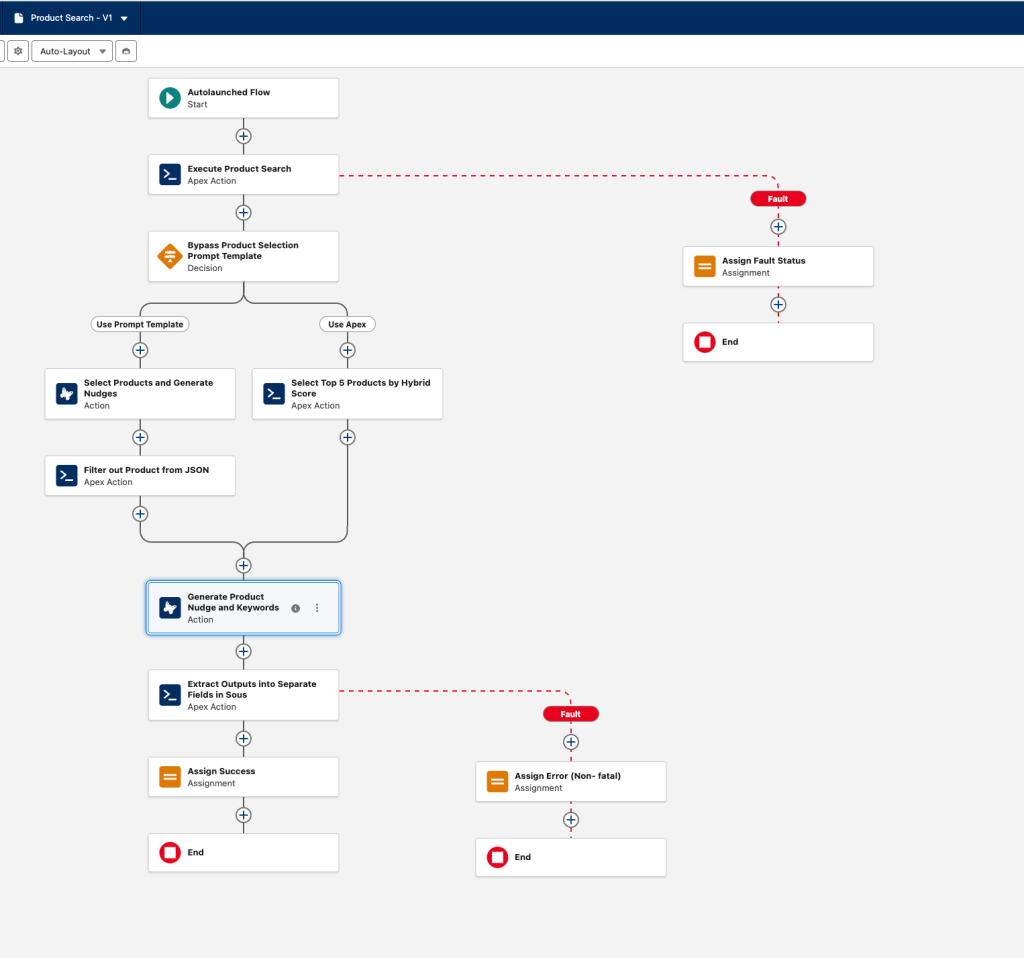
Early diagnostic work revealed that the initial proof-of-concept design relied heavily on the large language model (LLM) for tasks demanding deterministic precision. The model handled JSON parsing, hierarchical decisioning, and conditional evaluation. These areas, however, introduced small inconsistencies, which created downstream variability. Hardcoded instructions accumulated inside the prompt over time. This resulted in overlapping directives that behaved differently based on subtle user phrasing.
The team also uncovered ambiguity in how upstream data flowed through the system. Failing to resolve this early would have introduced unnecessary rework when scaling across multiple brands. It also would have created architectural dependencies limiting flexibility.
By rebuilding deterministic components in Apex and restructuring the prompt to remove overloaded instructions, the team created a clear separation between conversational reasoning and rule-based processing. These changes eliminated early inconsistencies, made responses more predictable, and laid the groundwork for a scalable multi-brand deployment.
Inside the refactor: engineering a successful Agentforce deployment and launch.
What non-deterministic LLM behavior created the most friction during customer QA, especially when nested order data introduced complex edge cases?
Deeply nested order structures presented the most challenging friction for the LLM. Retail orders include multiple items with independent delivery timelines, accessory attributes, and layered flags that influence operations. The LLM performed well in many scenarios. However, slight variations in structure or vocabulary caused it to choose inconsistent reasoning paths in edge cases needing deterministic precision.
During quality assurance, the customer observed that small changes in user language sometimes triggered different branches of the overloaded prompt instructions. When multiple flags existed at various hierarchy levels, the model occasionally misinterpreted their precedence or applied logic out of sequence. These inconsistencies made repeatable outcomes difficult across every scenario.
To correct this, the team moved all hierarchical interpretation and branching logic out of the model and into deterministic code. The LLM focused on conversational tasks. Structured rule evaluation occurred in Apex. This shift removed ambiguity, closed reliability gaps, and ensured complete consistency across the retailer’s full set of order flows.
What latency constraints emerged across the end-to-end flow—from order APIs and Data 360 lookups to multi-call LLM reasoning—and which areas introduced the greatest performance sensitivity?
Latency constraints came from two major areas:
- Order-system API latency required upstream retrieval before any reasoning could begin.
- Data 360 lookup latency occurred, especially when retrieving catalog or content records across millions of items.
The second major contributor was the multi-call LLM reasoning loop. Early versions made several sequential model calls to refine relevance scoring and determine next-step logic, which increased latency. Additional latency surfaced when data was retrieved in multiple incremental passes rather than through a single optimized pull. This created unpredictable delays across different interaction paths.
To address these constraints, our FDE team implemented several key optimizations:
- Consolidated the full reasoning flow into a single model call, eliminating multi-step evaluation sequences.
- Restructured prompt instructions to enable clear, deterministic one-pass reasoning.
- Optimized Data 360 retrieval to minimize round trips by requesting all required fields in one consolidated pass.
Together, these changes reduced end-to-end latency by 75%. This delivered the responsiveness needed for a production-grade conversational experience. It also established a scalable performance baseline for future multi-brand expansion.
What engineering challenges surfaced when scaling from a single pilot to a full multi-brand Agentforce architecture, particularly around domain abstraction, reusable schemas, and brand-specific conversational models?
The team weighed two options: a single agent for all brands or a dedicated agent for each. A unified model offered simplicity but struggled with brand voice, release schedules, and distinct domain needs. Each brand’s unique identity made a single abstraction compromise quality.
A multi-agent approach proved superior. Each brand gained a tailored agent for its voice, workflows, and user experience. This reduced coordination overhead and allowed independent brand evolution. It also ensured sensitive user interactions, like language and style, could be tuned individually.
The team built on a common architectural foundation, which allowed us to accelerate subsequent brand delivery by 5x. However, they avoided forcing a one-size-fits-all solution. Choosing one agent per brand preserved experience fidelity, simplified long-term maintenance, and created a clear path for future growth.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.