By Shiva Kumar Pentyala and James Zhu.
In our “Engineering Energizers” Q&A series, we shine a spotlight on the innovative engineers at Salesforce. Today, we feature Shiva Kumar Pentyala, Lead Data Scientist for Agentforce. Shiva and his team developed HyperClassifier, a specialized small language model that classifies data according to user provided prompts 30 times faster than general-purpose models by using a single-token prediction architecture.
Discover how they tackled the issue of unpredictable latency in real-time voice interactions, resolved the accuracy-speed tradeoff that traditional encoder classifiers couldn’t handle for prompts over few hundred tokens, and ensured adherence to complex instructions in the user prompts — thus achieving model quality at scale through frontier model consensus, as human-labeled datasets were not feasible.
What is your data science team’s mission building specialized small language models for Agentforce production AI?
We are building a new class of highly efficient and performant AI for Agentforce. Rather than relying on general-purpose models, we focus on creating specialized small language models (SLMs) that are fine-tuned to excel at specific business tasks, such as classification and response quality evaluation.
HyperClassifier is a prime example of this approach in action. It is an ultra-fast SLM that serves as the core decision-making engine for Agentforce. Before an agent generates a response, HyperClassifier understands user intent, routes agents to specific action sets, and, in voice interactions, determines if users have finished speaking. This specialized architecture allows us to deliver solutions that are significantly faster and more accurate for their intended purpose.
A core part of our mission is a commitment to continuous improvement. We constantly refine our models based on performance feedback and evaluations to enhance their reliability and effectiveness for our customers. This ensures that our AI solutions not only meet but exceed the expectations of those who use them, driving better outcomes and more seamless experiences.
What Time to First Token (TTFT) bottlenecks forced your team to build HyperClassifier for real-time AI agent classification?
External general-purpose models often introduce significant latency issues, mainly due to their multi-token, variable-length outputs. For simple classification tasks, these large models generate unnecessary reasoning or explanatory text, and the response time increases with the number of tokens produced. This unpredictable latency is particularly problematic for real-time applications like Agentforce Voice, where a longer topic name can lead to longer response times, which are unsuitable for seamless user experiences.
Moreover, these models occasionally produce hallucinated labels. When user class labels include unique codes, these models can fail to reproduce them accurately, leading to invalid outputs that disrupt the Agentforce stack. To overcome these challenges, we developed HyperClassifier. By designing it to produce a decision in a single, predictable output token, HyperClassifier reduces topic classification time by one second and thus reducing final agent response TTFT, ensuring efficient and reliable performance in real-time scenarios.

LLM training data schema to achieve single output token prediction.
What context window limitations prevented traditional encoder-based classifiers from handling 1,000+ token prompts for Agentforce?
While traditional encoder-based models are fast, they have two key constraints that prevented them from solving our problem:
First, they often cannot handle prompts over few hundred tokens without truncation, which can result in the loss of critical context from detailed instructions.
Second, they lack the nuanced reasoning capabilities of modern decoder architectures. Instead of understanding intent, they often rely on simple keyword matching.
For example, if asked to classify a query about a CEO’s birthdate against options including irrelevant biographical information versus “none of the above,” an encoder model would likely select the biographical option based on keyword relevance, rather than understanding that it doesn’t actually answer the question.
HyperClassifier, however, is designed to understand complex instructions while maintaining the deep understanding of large language models (LLMs) and achieving the speed of encoder models. This ensures that our solutions are both accurate and efficient.
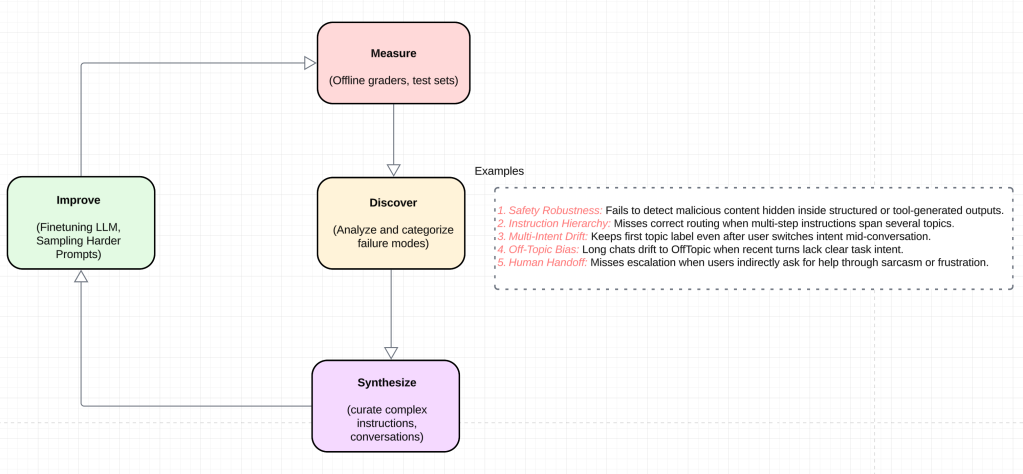
Our LLM finetuning pipeline for iterative model improvement.
What single-token prediction and KV caching innovations enabled HyperClassifier to achieve 30x speed improvement with LLM-level accuracy?
Our speed improvement stems from two primary architectural innovations. First, we recast classification as a task where the model predicts a single, unique special token that represents a class, rather than generating the class name as free-form text. This is the core of the speedup. Second, we aggressively cache the initial prompt computations using advanced KV caching, also known as Cached Augmented Generation. This technique ensures the model doesn’t re-process the same instructions on subsequent requests, which is crucial for real-time performance. These innovations deliver three key benefits:
- Constant-time O(1) inference: The model outputs a decision in a fixed number of steps, regardless of the class name length.
- Zero reasoning overhead: By fine-tuning the model to perform classification exclusively, we eliminate the slow free-form text generation capabilities.
- Complex instruction understanding: Despite its specialized function and speed, the model retains the powerful context-handling capabilities of modern decoder-based LLMs.
What production deployment obstacles did your team overcome shipping HyperClassifier in 2 months during a code freeze?
We achieved the ambitious two-month timeline by focusing on practical solutions for deployment, testing, and monitoring. For deployment, the team managed a production code freeze by using organization-level feature flags and optimized the inference stack by minimizing network hops, particularly for voice applications. Instead of a full A/B testing framework, we validated performance with key internal hero agents through a manual sign-off process and implemented robust regional and frontier model fallbacks to ensure resilience.
To monitor the model’s performance, the team quickly developed essential dashboards from scratch, enabling real-time tracking of topic drift and quality analysis, with clear rollback procedures to maintain production stability. We also addressed the model’s architecture and backward compatibility to meet legal and compliance requirements. These constraints guided our approach to the final validation challenge: ensuring high quality without relying on traditional testing infrastructure.
What validation challenges emerged ensuring HyperClassifier matches baseline model accuracy at enterprise scale without human-labeled datasets?
Overcoming prompt bias and achieving scalable data labeling was the most challenging aspect. Many customer prompts were implicitly designed for general-purpose model behavior, so we had to perform large-scale drift analysis to ensure our model performed exceptionally without customers needing to modify their existing prompts.
Since obtaining human-labeled golden datasets at an enterprise scale is impractical, the team developed a robust validation system using consensus from multiple advanced AI models to set our quality benchmark. This approach allowed us to validate at the scale required for production deployment while achieving 1-2% better accuracy than baseline models on internal evaluation benchmarks. This proved that we not only significantly reduced latency but also improved quality.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.