In our “Engineering Energizers” Q&A series, we delve into the inspiring journeys of engineering leaders who are at the forefront of innovation in their fields. Today, we shine a spotlight on Logan Goulett, Director of Software Engineering at Salesforce. Logan’s teams lead the development of the Decisioning Pipeline and Recommendations Services (DPRS) for the Salesforce Personalization product — an AI-powered system that delivers real-time, context-aware recommendations across channels. This product enables businesses to dynamically tailor customer experiences with remarkable speed and precision.
Dive into how Logan’s teams overcomes the challenges of balancing ultra-low latency with AI decisioning, managing service interdependencies and data freshness, and dynamically scaling to handle unpredictable traffic surges—all while driving AI-powered personalization forward.
What is your organization’s mission?
Delivering real-time AI-driven personalization at scale is a complex challenge. Customers expect instant, relevant recommendations and experiences across multiple touchpoints, which requires ultra-low latency processing, scalable infrastructure, and continuously learning LLMs and AI models.
The organization’s mission is to power real-time personalization at scale through a low-latency, highly available decisioning pipeline. DPRS also delivers AI-driven recommendations across web, mobile, and email, ensuring fast and contextually relevant decisioning.
Additionally, DPRS determines what content or product recommendations to serve based on real-time customer behavior, ensuring businesses provide the most relevant experiences across multiple engagement channels. Whether it’s adjusting an email’s content based on past purchases or dynamically updating a homepage banner, DPRS guarantees instant and accurate personalization.
Additionally, DPRS supports emerging AI-driven interactions, such as AI-powered sales and service agents, pushing the boundaries of personalized customer experiences.
What makes managing DPRS uniquely challenging?
It is mostly due to the need to balance real-time AI decisioning, ultra-low latency, and high availability at scale. Unlike batch-processing systems, DPRS must return ML-powered recommendations within milliseconds while fetching data from multiple dependent services.
A major challenge is service interdependencies. DPRS relies on other internal sub-systems to retrieve user profiles, behavioral data, and item embeddings. Any lag in these dependencies can slow down the entire pipeline and impact the end customer experience.
Another key challenge is data freshness. DPRS must immediately update recommendations when a user’s preferences change or a product goes out of stock, while avoiding inconsistencies. This requires real-time streaming updates and intelligent caching strategies.
Scaling across multiple Salesforce teams adds further complexity, necessitating cross-functional coordination to prevent regressions, performance degradation, or bottlenecks.
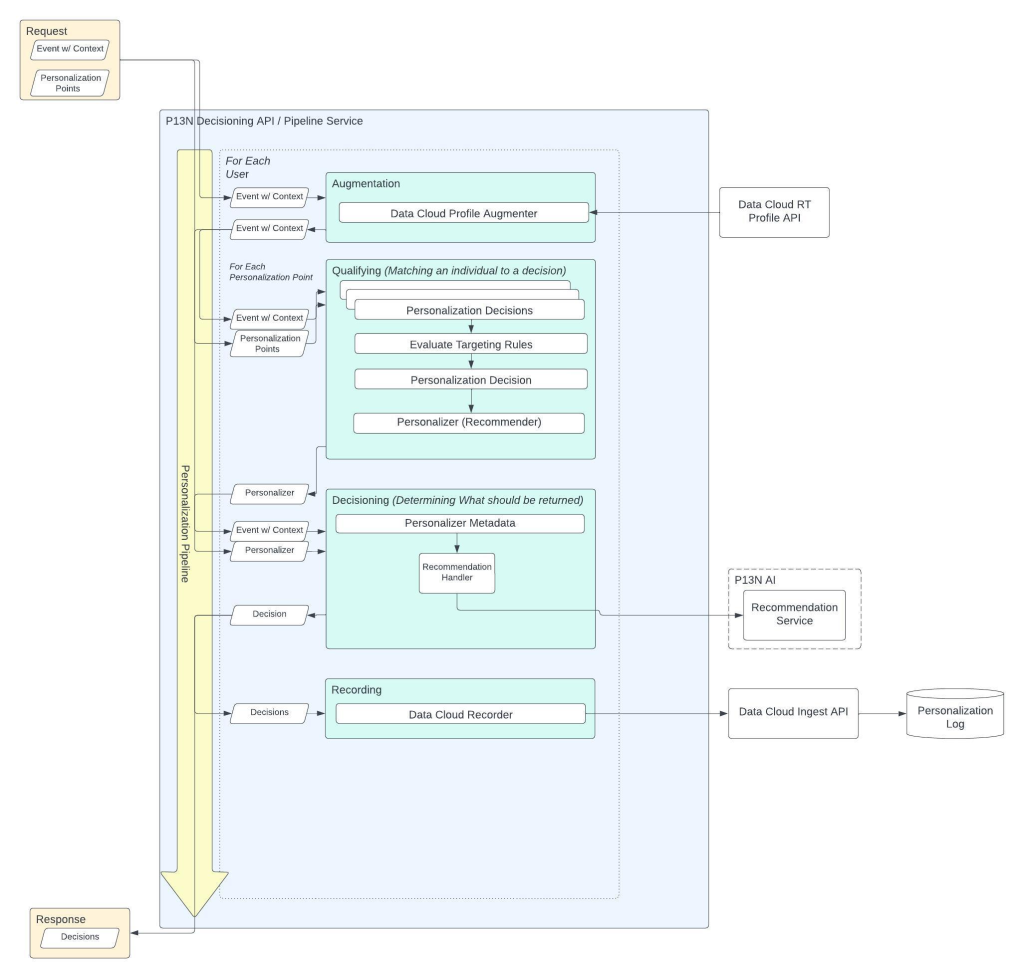
Diagram of the Decisioning Pipeline API and Pipeline Service.
How does your team optimize DPRS performance to achieve ultra-low latency?
Achieving sub-100ms response times is our biggest challenge, especially in a multi-service architecture where each API call adds millseconds can introduce delays.
To optimize performance, we use parallel processing to fetch user profiles, ML model outputs, and recommendation rankings simultaneously, significantly reducing processing time.
We also employ a two-layer caching strategy:
- Per-node caching: Reduces cost of deserialization and minimizes load on the global distributed cache.
- Global distributed caching: Ensures high-demand recommendations don’t overload back-end services.
Failover mechanisms allow DPRS to degrade gracefully if dependencies fail. Fallback models ensure that personalization continues even if real-time queries time out.
Every feature undergoes extensive performance testing before deployment, focusing on latency benchmarks to identify potential slowdowns at each stage of request processing, ensuring consistently fast response times.
Logan explains what keeps her at Salesforce.
What are the biggest scalability challenges when supporting real-time personalization with DPRS at web scale?
One of the biggest challenges with DPRS is handling unpredictable traffic spikes, especially during high-demand events like Black Friday. A single enterprise customer’s campaign launch can trigger a 10x surge in traffic, requiring DPRS to scale dynamically.
To address this, Kubernetes auto-scaling is leveraged, allowing DPRS to handle thousands of concurrent requests per second. The system is tenant-aware, ensuring that large clients don’t monopolize resources, which could degrade performance for smaller tenants.
Another significant concern is cache stampedes. If thousands of requests hit an expired cache entry simultaneously, this could overwhelm databases. We prevent this via asynchronous cache updates and a ‘stale-while-revalidate’ pattern that falls back to the existing cached value while we wait for the update.
While latency optimizations focus on making each request as efficient as possible, scalability improvements ensure that DPRS maintains stable performance even during extreme, unpredictable traffic spikes.
How does your team validate AI-driven decisioning in DPRS before pushing changes to production, and what research efforts (such as offline evaluation) are improving its capabilities?
Since DPRS is still in early adoption, we’re investing in offline evaluation to validate AI updates before deployment. This ensures that new ranking models, contextual bandits, and resorting algorithms improve recommendations without disrupting live customers. Offline testing allows simulation of user interactions using historical data, measuring:
- Prediction accuracy (do recommendations improve engagement?)
- Latency impact (does the model increase response time?)
- Computational efficiency (does the model strain resources?)
Staged rollouts are also used:
- Deploy to an isolated test environment with no live traffic.
- Release to a subset of low-risk customers while monitoring performance.
- Gradually expand rollout based on success metrics.
This ensures that DPRS evolves through rigorous validation rather than live experimentation on customers.
How does your team rapidly deploy new DPRS features while ensuring stability and system integrity?
Rapid deployment in a real-time AI system like DPRS requires a measured, risk-mitigated approach. A 30% Trust Investment is encouraged, allocating one-third of engineering time to security, reliability, and performance rather than feature development.
New features are deployed via canary rollouts, ensuring that high-risk changes are tested in small-scale environments before full deployment. Performance testing includes:
- Load testing to assess impact on Kubernetes scaling.
- Threat modeling to identify security vulnerabilities.
- Cross-team architectural reviews to prevent breaking dependencies.
This controlled, multi-layered deployment process allows DPRS to innovate rapidly while maintaining reliability.
How do you gather and incorporate real-world feedback to improve DPRS?
Customer feedback is crucial, especially during the early adoption phase of DPRS. The team works closely with pilot customers to gather real-world insights into performance, usability, and the effectiveness of recommendations.
Support engineers play a vital role by handling escalations and debugging live issues, providing valuable input on where the system faces challenges. A direct pipeline between support and engineering ensures that high-priority issues are addressed promptly.
Additionally, real-time telemetry and monitoring offer insights into:
- Latency trends (are requests slowing down over time?)
- Recommendation success rates (are users engaging with personalized content?)
- Error spikes (are certain failure patterns emerging?)
This continuous feedback loop ensures that DPRS evolves based on data-driven insights, not assumptions, delivering a more robust and reliable solution to customers.
How is DPRS expanding beyond traditional web and mobile experiences into agentic interactions?
At Salesforce, the next evolution of AI-driven personalization is moving beyond static content recommendations and into real-time, adaptive decisioning for AI-powered agents. One of the major challenges with AI assistants is that they often lack deep personalization, providing generic, pre-scripted responses instead of contextual, user-aware interactions.
With DPRS, AgentForce dynamically adjusts responses based on real-time customer sentiment, past behaviors, and engagement history. For example, instead of a chatbot asking, “How can I help you?” DPRS enables the chatbot to say, “We noticed your last order didn’t go as expected — would you like to speak with a live representative?”
Additionally, DPRS optimizes profile context retrieval, ensuring that only the most relevant customer data is surfaced instantly. This makes AI responses more adaptive, human-like, and effective.
As AI-driven customer engagement continues to evolve, DPRS will play a key role in ensuring that every interaction is intelligent, responsive, and deeply personalized in real time.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.