By Srikanta Prasad SV, Nitin Surya, and Sai Guruju.
In our “Engineering Energizers” Q&A series, we explore the paths of engineering leaders who have attained significant accomplishments in their respective fields. Today, we spotlight Srikanta Prasad SV, Senior Product Manager at Salesforce, who leads the AI Model Serving team in pushing the boundaries of natural language processing and AI capabilities for enterprise applications. One of the key focus areas for his team is optimizing large language models (LLMs) by integrating cutting-edge solutions, collaborating with leading technology providers, and driving performance enhancements that impact Salesforce’s AI-driven features.
Dive into how Srikanta’s team tackles challenges like balancing throughput and latency, ensuring secure AI deployments with AWS SageMaker, and exploring innovations like DJL-Serving and NVIDIA GPUs to power real-time AI applications.
What is your team’s mission?
The AI Model Serving team supports a wide range of AI models, including LLMs, multi-modal models, speech recognition, and computer vision-based models, advancing AI across various domains. The team focuses on boosting performance and capabilities through innovation and collaboration with leading technology providers.
Key features include:
- Comprehensive Model Support: Deploying and managing models such as LLMs, multi-modal, predictive, speech, and vision-based models to tackle diverse AI challenges.
- Advanced Performance Testing: Rigorous testing and continuous evaluation ensure models are production-ready, meeting high standards of scalability, reliability, and cost-efficiency.
- Scalability and Reliability: Solutions like DJL-Serving, NVIDIA Triton, and NIM provide scalability and reliability, allowing seamless deployment and efficient handling of complex tasks and high-traffic loads. Observability features like alerting and monitoring are available for all models.
- State-of-the-Art Inference Solutions: DJL-Serving, AWS SageMaker, and optimization techniques like TRT-LLM and quantization ensure seamless integration of AI models into Salesforce and business processes.
- Collaboration and Innovation: Partnering with NVIDIA, AWS, and open-source communities ensures the latest AI advancements are integrated to enhance model serving capabilities.
The team deploys and evaluates machine learning models across multiple environments. Extensive performance testing and hosting evaluation guarantee scalability and reliability, while DJL-Serving and AWS SageMaker provide frameworks for seamless integration into business applications.

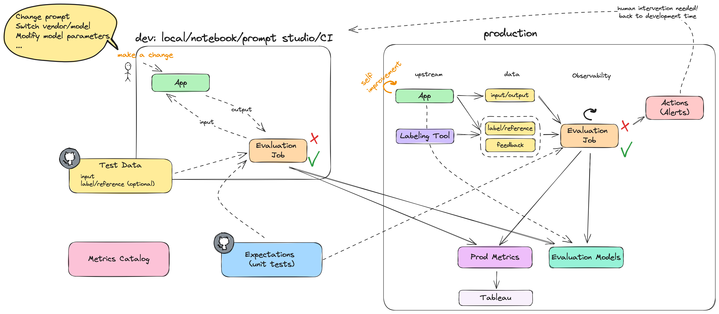
Machine learning (ML) inference capabilities at a glance with Einstein AI Model Serving.
What was the most significant technical challenge your team faced recently?
The team is responsible for the end-to-end process of gathering requirements/performance-objectives, hosting, optimizing, and scaling AI models, including LLMs, built by our data science and research teams. This includes not only optimizing the models to achieve high throughput and low latency, but also deploying them quickly through automated, self-service processes across multiple regions.
A key challenge they faced was balancing latency and throughput while ensuring cost efficiency, particularly when scaling these models based on dynamic workloads. By focusing on the entire lifecycle—from deployment to scaling—we ensure that the cost to serve is minimized without compromising performance or scalability. Inference optimization is a crucial aspect of this process, as we fine-tune the models to meet performance/cost requirements in real-time AI applications. To tackle these complex issues, we:
- Utilized AWS SageMaker for distributed inference
- Deployed hardware accelerators like NVIDIA GPUs
- Integrated DJL-Serving to streamline deployment workflows through a modular architecture, batching techniques, weights quantization and multi-framework support
DJL-Serving’s rolling-batch capabilities enhanced GPU utilization, ensuring effective resource management. These combined efforts successfully optimized model performance, meeting the rigorous benchmarks required for production environments.
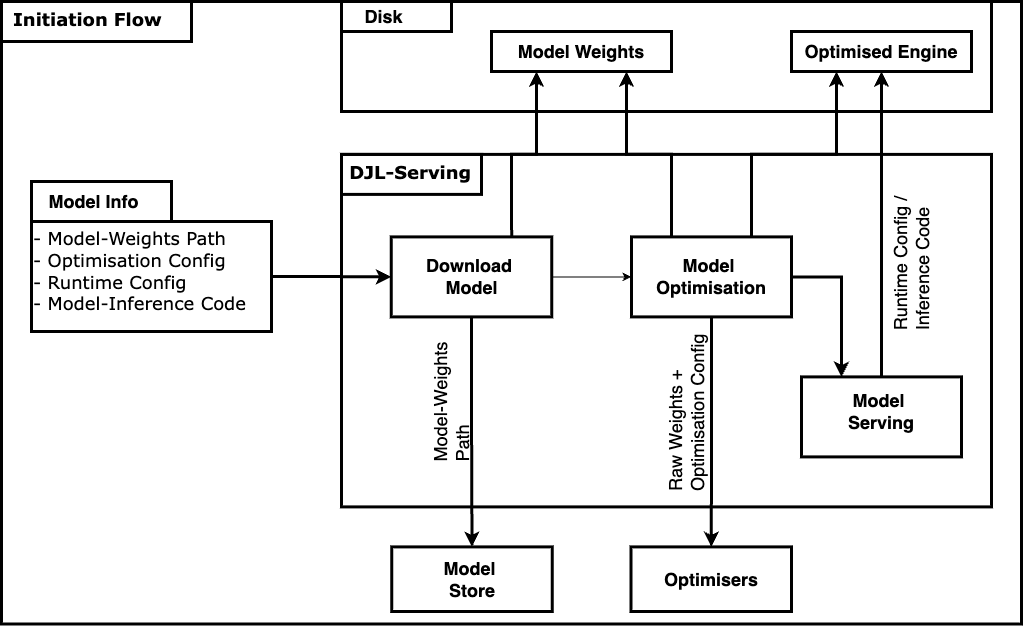
Initiation flow of DJL Serving.
How do you manage challenges related to scalability in your project?
Managing scalability in the project involves several strategies focused on balancing performance, efficiency, and resource management. By leveraging solutions like AWS SageMaker and NVIDIA’s Triton Server, the team supports distributed inference and multi-model deployments, preventing memory bottlenecks and reducing hardware costs. SageMaker provides access to advanced GPUs, supports multi-model deployments, and enables intelligent batching strategies, balancing throughput with latency. This flexibility ensures performance improvements do not compromise scalability, even during high-demand scenarios.
Additionally, routing strategies, autoscaling mechanisms, and features from AWS Inference components — such as instance scaling, real-time model monitoring, and elastic load balancing — are continually refined to balance traffic across multiple model instances. These measures ensure consistent performance across environments while optimizing scalability, performance, and cost-efficiency.
What strategies did your team employ to ensure enhancements in one area of your project did not compromise others?
The team adopted a modular development approach, complemented by comprehensive testing and cross-functional collaboration. DJL-Serving’s architecture is designed with modular components such as the engine abstraction layer, model store, and workload manager. This structure allows the team to isolate and optimize individual components, like rolling-batch inference for throughput, without disrupting critical functionalities such as latency or multi-framework support.
Continuous integration (CI) pipelines were implemented to detect any unintended side effects early. Regression testing ensured that optimizations, such as deploying models with TensorRT or VLLM, did not negatively impact scalability or user experience. Regular reviews, involving collaboration between the development, LLMOps, and security teams, ensured that optimizations aligned with project-wide objectives.
Configuration management using simple YAML files enabled rapid experimentation across optimizers and hyperparameters without altering the underlying code. These practices ensured that performance or security improvements were well-coordinated and did not introduce trade-offs in other areas.
How do you balance the need for your project’s rapid deployment with maintaining high standards of trust and security?
Balancing rapid deployment with high standards of trust and security requires embedding security measures throughout the development and deployment lifecycle. Secure-by-design principles are adopted from the outset, ensuring that security requirements are integrated into the architecture. Rigorous testing of all models, including LLMs, is conducted in development environments (Q2 and Q3 testing) alongside performance testing to ensure scalable performance and security before production.
To maintain these high standards throughout the development process, the team employs several strategies:
- Automated CI/CD pipelines with built-in checks for vulnerabilities, compliance validation, and model integrity
- DJL-Serving’s encryption mechanisms for data in transit and at rest
- AWS services like SageMaker that provide enterprise-grade security features such as role-based access control (RBAC) and network isolation
Frequent automated testing for both performance and security is employed through small incremental deployments (canary releases), allowing for early issue identification while minimizing risks. Collaboration with cloud providers and continuous monitoring of deployments ensure compliance with the latest security standards. These practices ensure that rapid deployment aligns seamlessly with robust security, trust, and reliability.
What ongoing research and development efforts are aimed at improving your project’s capabilities?
Ongoing research and development efforts are centered on enhancing the performance, scalability, and efficiency of large language model (LLM) deployments. The team is exploring new optimization techniques, including:
- Advanced quantization methods
- Tensor parallelism
- More efficient batching utilizing caching strategies within DJL-Serving to boost throughput and reduce latency
Additionally, the team is investigating emerging technologies like AWS Inferentia and Graviton processors to further improve cost and energy efficiency. Collaboration with open-source communities and public cloud providers like AWS ensures that the latest advancements are incorporated into deployment pipelines while also pushing the boundaries further. we collaborated with AWS to include some advanced features into DJL which makes the usage even better and more robust. A key focus is refining multi-framework support and distributed inference capabilities to ensure seamless model integration across various environments.
Efforts are also underway to enhance LLMOps practices, such as automated testing and deployment pipelines, to expedite production readiness. These initiatives aim to stay at the forefront of AI innovation, delivering cutting-edge solutions that align with business needs and meet customer expectations.
Learn More
- Read this blog to explore how SageMaker enhances Einstein’s LLM latency and throughput.
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.