In our “Engineering Energizers” Q&A series, we explore the paths of engineering leaders who have made significant contributions to advancing their fields. Today, we spotlight Ashish Bharadwaj Srinivasa, Lead Data Scientist responsible for Data Cloud Hybrid Search at Salesforce. Ashish has been instrumental in developing an innovative search system that merges traditional keyword search with advanced vector search capabilities to deliver a more accurate, efficient, and reliable search experience.
Explore how Ashish’s Search Relevance team tackled technical challenges such as fusing results from different retrieval systems, implementing advanced ranking algorithms, and ensuring trust and security in delivering the most relevant search results, necessary to power AI-driven applications for Salesforce customers.
What is your team’s mission?
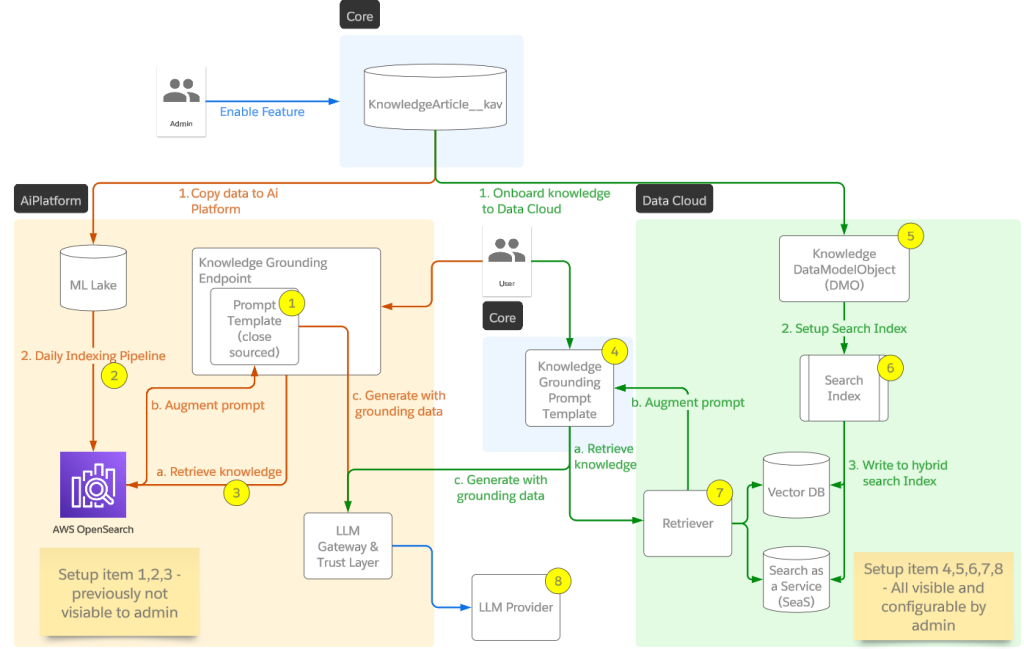
Salesforce’s Search Relevance team is dedicated to enhancing user productivity by delivering the most pertinent information for search, retrieval augmented generation, and other AI and Data Cloud applications. The goal is to optimize the efficiency of user and AI interactions in information retrieval.
With the introduction of Data Cloud Hybrid Search, the aim is to merge the strengths of traditional keyword search with advanced vector search. This integration not only supports Agentforce and generative AI applications with superior grounding information from Data Cloud but also improves accuracy of SearchBox, automation, and analytics experiences that are required to retrieve unstructured data. Keyword search offers exact match capabilities essential for handling specific domain vocabularies of customers. Vector search adds value by recognizing semantic similarities between queries and document text passages.
In Hybrid Search, results from both keyword and vector indices are combined, fused, and ranked, and then the top-ranked K passages are delivered to the requesting applications. Testing shows that Hybrid Search’s dual approach significantly improves search accuracy and offers a more dependable search solution.
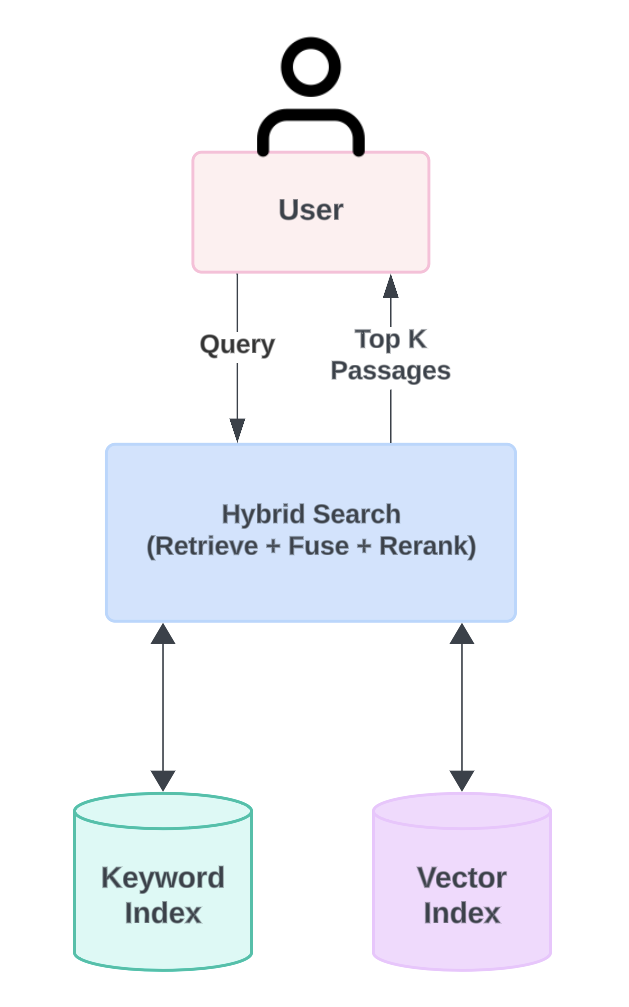
Overview of how Hybrid Search combines keyword and vector search to provide results for a user query.
What was the most significant technical challenge your team faced recently?
We faced technical challenges integrating results from two distinct retrieval systems in the Hybrid Search tool. The difficulty stemmed from the fusion logic, as the similarity scores from keyword and vector searches originated from different distributions, complicating direct comparisons among keyword-only and vector-only results. Additionally, updates to the vectorization or embedding models used in vector searches added complexity to this process.

Difference in distributions across keyword and vector similarity scores, including the impact of the embedding model.
To address this issue, various score transformation functions were experimented with to standardize the similarity scores into easily and directly comparable distributions.. The team also fine-tuned the combination of these transformations with appropriate ranking algorithms, enabling the merging and fair comparison of results from both indices. Hybrid Search then assigns a relevance score to each result, selecting the top-ranked results to return to the users.
Moreover, customers are offered the flexibility to customize these score transformation functions according to their specific needs when configuring Hybrid Search, enhancing adaptability and user satisfaction.
Please describe the fusion ranking in Data Cloud Hybrid Search and highlight the challenges it solves.
In Data Cloud Hybrid Search, a linear fusion ranker is used that effectively merges search results from different sources. Two transformation functions are offered for adjusting similarity scores: the query max scaler and the reciprocal rank transform.
The query max scaler normalizes scores to a range between 0 and 1 by dividing each score by the maximum for that query, allowing for accurate comparisons across different tenants. The reciprocal rank transform focuses on rank ordering rather than scores, with a configurable decay parameter to adjust rank gradients, ideal for vector similarity scores where cosine similarity scores might not be a good indicator of relevance.
Hybrid Search also includes two default fusion rankers: the reciprocal rank fusion (RRF) and an optimized linear fusion ranker. The RRF applies reciprocal rank transforms with a decay of 60 to both keyword and vector similarities, with customizable index weighting. The linear fusion ranker uses data-driven trained weights and transformations developed from a broad training dataset, ensuring effective ranking.
From experience with CRM search, it has been observed that, apart from the query-passage similarity, certain document metadata help further enhance the relevance of search results. Hybrid Search currently has the capability to use additional configurable ranking factors such as popularity and recency. Generally, Hybrid Search uses these features as additional deciding factors when keyword and vector relevance are insufficient to decide the final relevance of the passage.
How do you balance the need for Data Cloud Hybrid Search’s rapid deployment with maintaining high standards of trust and security?
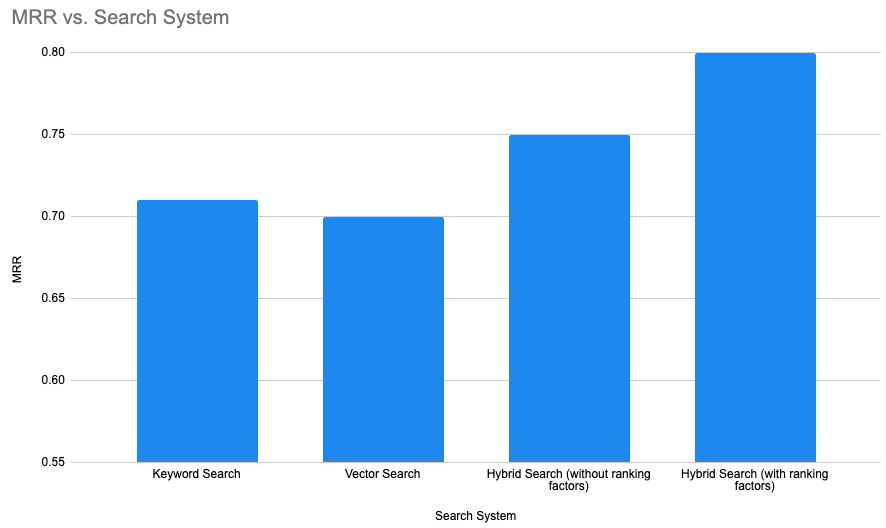
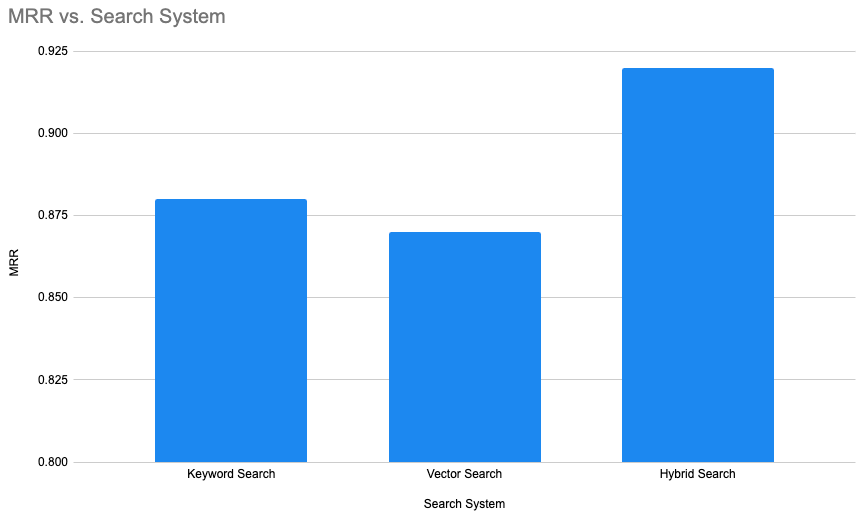
Trust and security of Data Cloud Hybrid Search are ensured by extensive evaluation on internal benchmarks. Initially, Hybrid Search ranking is evaluated on a passage ranking task. For each query, the goal is to identify the most relevant passage as captured by the MRR (Mean Reciprocal Rank) metric. The chart below shows that Data Cloud Hybrid Search performs better than using either keyword or vector in isolation. Additionally, the use of popularity and recency ranking factors enhances the overall relevance.

Generative AI is another important application for Data Cloud Hybrid Search. It is intended to be used as the retriever/ranker in a Retrieval-Augmented Generation (RAG) setting with downstream generation tasks. To capture this query pattern, Hybrid Search ranking is also evaluated on a RAG-specific task such as question answering. The chart below similarly shows that Hybrid Search performs better than using keyword or vector in isolation.

What strategies did your team employ to ensure enhancements in one area of Data Cloud Hybrid Search did not compromise others?
Handling numerous types of scenarios without breaking the search experience is critical. The current Hybrid Search, integrated into Data Cloud, is the result of multiple iterations of research and development on ranking algorithms. This process included quantitative and qualitative assessments to address identified gaps. Data Cloud Hybrid Search is trained to remove biases between results retrieved from keyword versus vector searches to ensure fair comparisons. This is essential to provide relevant passages for downstream generative AI tasks.
Additionally, Hybrid Search is optimized to perform well whether users enable the additional popularity and recency ranking factors or not, ensuring the robustness of the ranking models. To address possible biases in the model and its sensitivity to missing features, a metric called robustness (higher is better) is introduced. Observations show that Hybrid Search performs much better than a classical RRF (Reciprocal Rank Fusion) ranker.

What ongoing research and development efforts are aimed at improving Data Cloud Hybrid Search’s capabilities?
Efforts are underway to enhance Hybrid Search by implementing a cascade ranking system with additional late-stage rerankers on top of the current retrieval + fusion + rank system. The objective is to further improve precision in the top K results, which is crucial for use in generative AI applications such as RAG, where the top chunks are sent to an LLM for generation.
To ensure generalizability and robustness, a novel ensemble technique for features will soon be introduced into the deep reranker. This will enable the model to make the most precise predictions even when certain features are missing. Additionally, the deep rerankers are being refined to understand user intent from the query and to appropriately favor keyword versus vector results.

Ensemble deep ranking for increased robustness and precision.
Learn More
- Want more Data Cloud stories? Learn Data Cloud’s Secret for Scaling Massive Data Volumes in this blog.
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.