In our “Engineering Energizers” Q&A series, we explore the journeys of Salesforce engineering leaders who have reached significant achievements in their fields. Today, we catch up with Erwin Karbasi, leader of the Salesforce Machine Learning (ML) Observability team. His team is responsible for maintaining the reliability and performance of generative AI applications across their entire lifecycle.
Discover how Erwin’s team tackles large language model (LLM) hallucinations and retrieval-augmented generation issues, provides insights into prompt performance, and supports the generative AI development lifecycle through continuous learning and refinement.
What is your team’s mission?
We focus on implementing robust monitoring and feedback mechanisms that maintain model accuracy and track performance during lifecycles. Early detection of anomalies and prompt resolution of issues are key to preserving the integrity of AI solutions.
Additionally, we analyze user interactions and feedback to drive iterative improvements. This ensures that AI applications remain effective, adaptable, and aligned with user needs and business goals. Through continuous learning and refinement, we help AI models become smarter and more reliable over time.
What was the most significant technical challenge your team faced recently, and how did you overcome it?
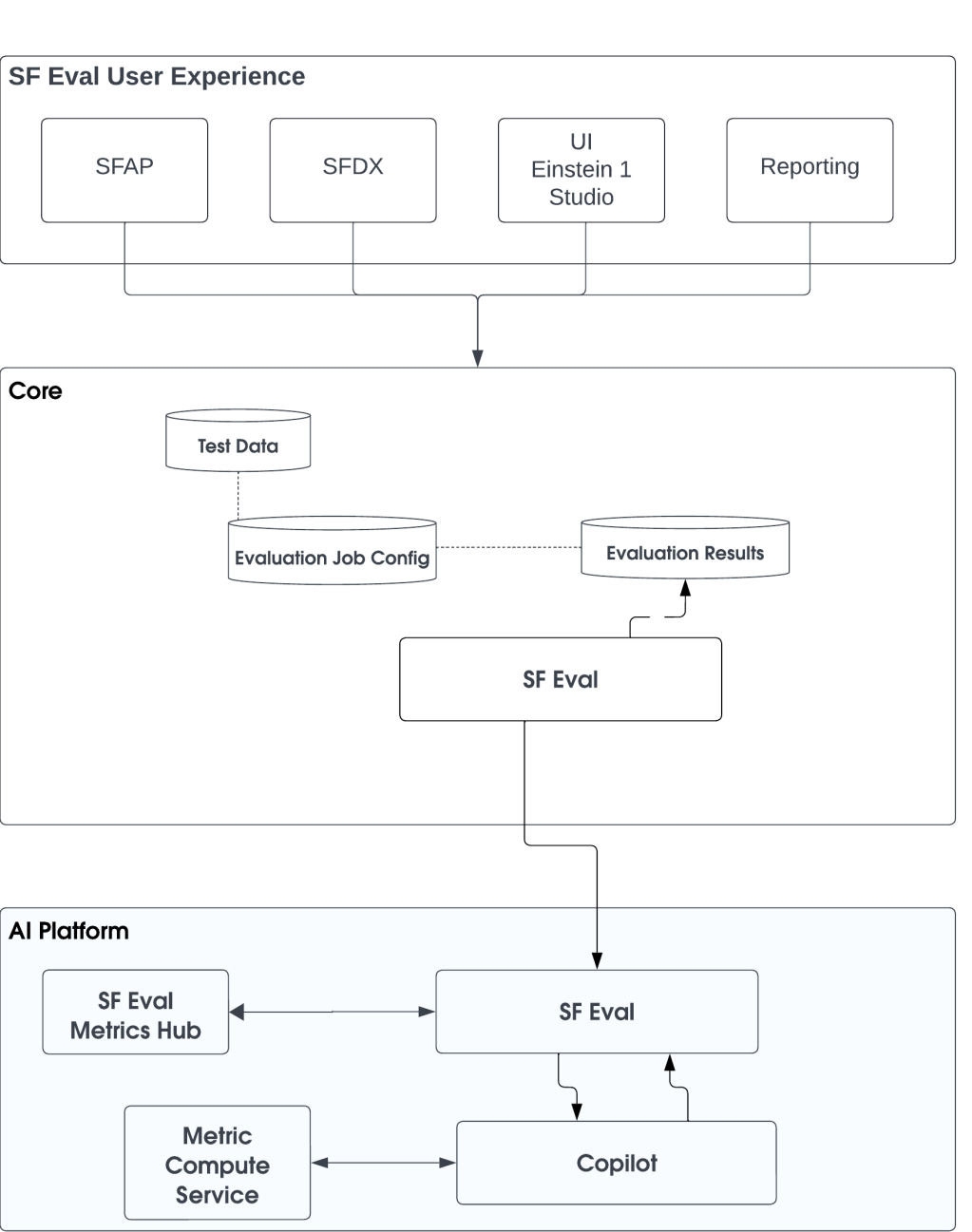
The team encountered a major hurdle in monitoring and ensuring the observability of generative AI applications. To address this, the Salesforce Central Evaluation Framework (SF Eval) was utilized to implement and track:
- Model Operational Metrics: Inferences processed, along with warnings and errors, were monitored to maintain system health and proactively resolve issues.
- Text and Code Generation Metrics: Text quality was assessed using metrics like toxicity detection score and bias detection score to ensure the content was safe and accurate.
- Retrieval-Augmented Generation (RAG) Metrics: Factual consistency and relevance were checked with contextual relevance and answer relevance metrics.
- Latency Metrics: Response times were monitored to enhance system performance.
- Model-specific Metrics: BLEU scores and perplexity were tracked to refine model performance.
- Token and Cost Metrics: Expenses and token usage were managed to optimize efficiency and control costs.
- Prompt Accuracy Metrics: Prompt design was continuously refined to improve AI performance.
By implementing these diverse metrics, the team ensured that the generative AI applications remained accurate, reliable, and effective.
What challenges do LLMs typically encounter in production?
Deploying LLMs in production involves several challenges. One significant issue is LLM hallucinations, where the model generates incorrect information but presents it as accurate. This can undermine user trust and compromise the reliability of the application. To combat this, our team actively monitors outputs to identify and correct inaccuracies promptly.
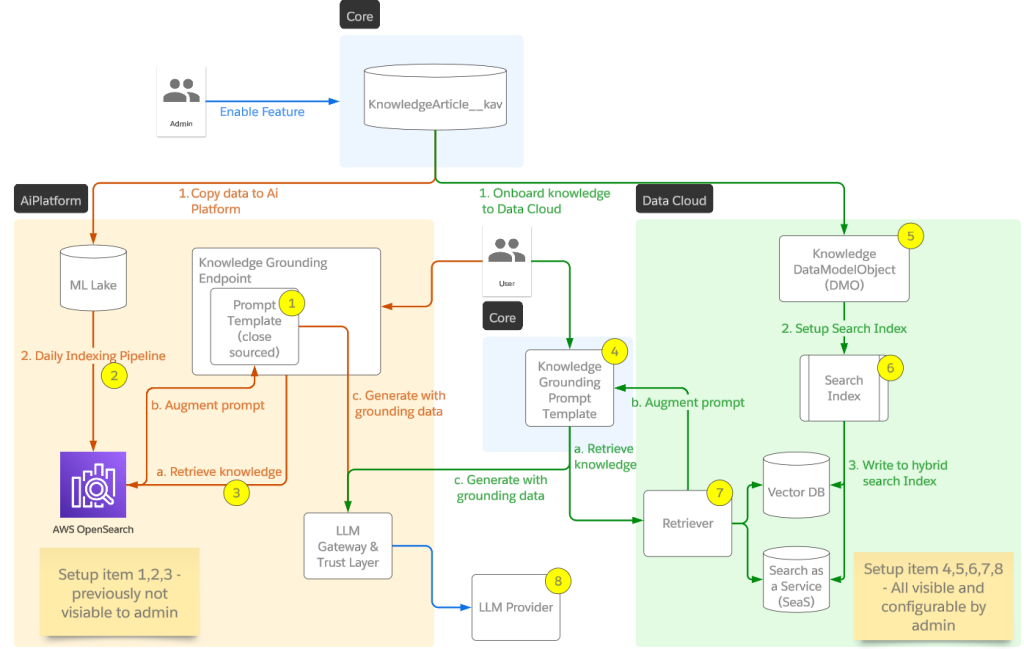
Another challenge involves issues with RAG processes, where identifying the source of retrieval errors is crucial for effective resolution. Our observability tools are instrumental in pinpointing these errors, enabling targeted fixes. Additionally, ensuring the quality of prompts and prompt templates are vital for maintaining high-quality outputs. Our team analyzes prompt performance to enhance consistency and reliability. This level of observability provides detailed performance insights across different layers, simplifying the process of tracing and resolving failures.
How does your team support the generative AI development lifecycle?
Our team provides a comprehensive framework for overseeing the lifecycle of generative AI applications, spanning from their development to deployment and subsequent phases. We tackle various challenges including preserving accuracy, handling data variability, and maintaining ethical standards.
By integrating advanced monitoring systems, feedback mechanisms, and continuous learning processes, we empower developers to refine AI models effectively. This allows for swift resolution of performance issues and adaptation to evolving data trends. Our holistic approach enhances the reliability and efficiency of AI applications, fostering continuous improvements that lead to progressively smarter and more effective AI solutions.
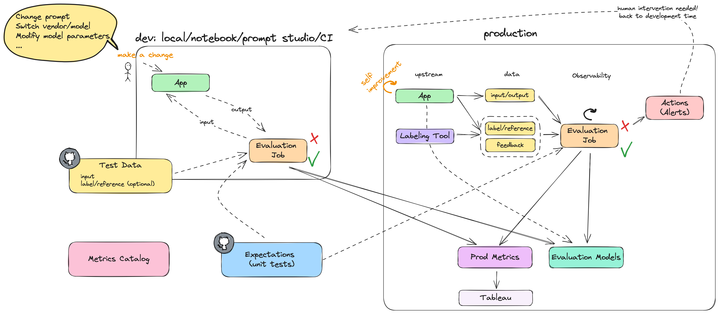
Salesforce ML Observability offers a robust framework for managing the lifecycle of generative AI applications.
What steps does your team take in the pre-deployment phase of the generative AI development lifecycle?
In the pre-deployment phase of the generative AI development lifecycle, the team follows a structured approach to ensure the effectiveness and safety of AI applications:
- Prompt Engineering: The SF Eval framework is utilized to refine and test prompts, ensuring effectiveness and consistency across different contexts.
- Action Definition: Business requirements are integrated to define clear tasks and responses, aiming for a balance between efficiency and specificity.
- Model Selection and Fine-Tuning: Models are selected and fine-tuned using domain-specific data, enhancing performance and ensuring adaptability through continuous monitoring and updates.
- Rigorous Testing: Extensive testing is conducted on prompts, actions, and models, covering edge cases and stress scenarios to guarantee comprehensive coverage and robust performance.
- Benchmarking and Ethical Standards: Baseline performance metrics are established and safety and ethical checks are implemented to prevent harmful or biased outputs. These safeguards are continuously updated to reflect evolving standards.
What steps does your team take in the post-deployment phase of the generative AI development lifecycle?
Once a generative AI application is deployed, our focus shifts to monitoring, analysis, and continuous improvement. We track key performance indicators such as response accuracy and user satisfaction, and optimize resource usage through automated alerts that facilitate rapid issue resolution.
Feedback collection is crucial, encompassing both explicit and implicit user responses. We utilize advanced analytics tools to analyze this data, identifying trends, detecting anomalies, and linking AI performance to business outcomes. When problems occur, root cause analysis pinpoints their origins. We employ A/B testing to refine the application without disrupting the user experience.
Continuous learning is integral to our process, allowing the model to adapt to new data and changing needs. Insights gained from production are fed back into development, enhancing prompt design, updating training datasets, and transitioning to more sophisticated models when necessary.
How does your team ensure continuous improvement and effective reporting?
Our approach to stakeholder reporting involves creating customized reports that cater to the unique needs of different audiences, ensuring that everyone from technical teams to executives receives clear and relevant AI performance metrics. We integrate pre-deployment and post-deployment activities, fostering a cycle of continuous improvement that enhances the performance and value of generative AI applications over time.
By adhering to this comprehensive observability framework, Salesforce guarantees that its generative AI applications not only sustain their performance but also evolve, becoming increasingly intelligent and effective at meeting business demands.
What ongoing research and development efforts are aimed at improving monitoring and observability capabilities?
We are developing advanced APIs for tech-savvy users, facilitating the integration of monitoring data into existing systems for automated alerts and custom dashboards. For non-technical users, we are crafting user-friendly interfaces like Einstein 1 Studio, which offers a low-code or no-code experience, making monitoring accessible to business analysts, project managers, and other non-technical staff.
Our dual approach ensures that everyone, regardless of technical skill, can effectively monitor and improve AI applications. We integrate these monitoring tools throughout the AI development and deployment cycle, allowing for benchmarking, testing, and fine-tuning of models both before and after launch. This integration fosters a continuous feedback loop, where production data drives development adjustments, enhancing the intelligence and reliability of AI applications. Through these initiatives, we aim to deliver smarter, more reliable AI applications for all users.
Learn More
- What’s the future of AI testing? Check out Salesforce’s next gen framework for AI model performance in this blog.
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.