

Infrastructure and software failures will happen. We idolize four 9s (99.99%) availability. We know we need to optimize and improve Recovery-Time-Objective (RTO, the time it takes to restore service after a service disruption) and Recovery-Point-Objective (RPO, the acceptable data loss measured in time). But how can we actually deliver high availability for our customers?
One of the missions of Salesforce’s engineering team is to prevent and minimize service disruptions. To achieve high availability for our customers, we design cloud-native architectural solutions that enable resilience for infrastructure failures and faster resolutions for unplanned incidents. We adopt safe deployment for non-disruptive software updates and releases.
This post will share our architectural principles for high availability that we’ve learned over the years and are applying to the Salesforce Hyperforce platform.
High Availability Architectural Principles
1. Build your services on infrastructure across multiple fault domains
2. Adopt a safe deployment strategy
3. Understand your “Blast Radius” and minimize it
4. Take advantage of the elastic capacity
5. Design to withstand dependency failures
6. Measure, learn, and improve continuously
1. Build your services on infrastructure across multiple fault domains
Salesforce Hyperforce is built natively on public cloud infrastructure. The public cloud providers operate multiple data centers in a single region. Data centers are grouped into “availability zones” (AZ) in distinct physical locations with independent power and networks to prevent correlated infrastructure failures. The availability zones are the fault domains within a region. They are connected through redundant, low-latency, and high-bandwidth networks.
Salesforce Hyperforce services are deployed across multiple availability zones (usually three) within a region. As the availability zones are isolated fault domains, Hyperforce services can continue to operate with minimal disruptions if an availability zone fails. Most of the Hyperforce services are serving actively from multiple availability zones. Some transactional systems that have a single primary database may automatically and transparently failover the primary database to the standby database in a healthy availability zone with a brief failover time. The disruption is minimal – some in-flight requests or transactions will not succeed and will be re-tried if an availability zone fails.
In addition, we adopt the static stability deployment strategy for Hyperforce services with the objective of withstanding an entire availability zone failure and one more individual component failure in another availability zone (AZ+1). We do not need to compete for public cloud resources to scale up at runtime in the event of failures.
2. Adopt a safe deployment strategy
Over the years, we have learned that changes we made to the production systems, such as releasing a new version of software or automation or changing a configuration, is a primary contributor to service disruption due to software bugs or faulty configurations.
While the best thing is to prevent it from happening (with rigorous testing, for example), we know in reality that some issues may not surface during the test due to the workload, dependent services, or use cases. We need a safe deployment strategy to minimize the risk of new software bugs and also can rapidly resolve disruptions caused by faulty software or configurations.
At Salesforce, we adopt several safe deployment patterns, including rolling upgrades, canary and staggering, and Blue-Green deployment. All of them require no downtime for customers. We also adopt the immutable deployment principle to deploy services at the instance image level to avoid any configuration drift.
Rolling upgrades are commonly used in a clustered service. We will first indicate one or a few service instances in the cluster to be in maintenance mode. The load balancer will direct traffic to other active service instances. We deploy or upgrade the software or configurations for these service instances in maintenance by recreating the instances with a new image. We then enable them for traffic and repeat the process for other service instances in batch.
For canary, we first roll out changes to a small set of service instances to validate the changes. Given enough time for validation, we then roll out to the remaining set, usually using a staggered process through different logical groups of service instances at different times to minimize any unexpected service disruptions caused by the changes.
For Blue-Green deployment, we deploy a new version (Green) of the service instances alongside the current version (Blue) with the same capacity. After testing and validation, the load balancer directs the traffic to the new version service instances and decommission the service instances with the previous version.
We have seen in some rare scenarios that a change can go through rolling upgrades or some staggering without issues until some time later. Another requirement for safe deployment is to support rapid deployment mode when we need to quickly roll back a change by deploying the last known good image or roll forward a fix by deploying a new image.
We will dive into more details on how we use the infrastructure redundancy and isolation and safe deployment for high availability in the following principle, the “Blast Radius.”
3. Understand your “Blast Radius” and minimize it
Try to answer these questions – how many customers are impacted if a software or infrastructure failure happens to my service? How can I reduce the number of customers affected if a failure happens?
The fundamental concept is to “partition” (or “shard”) your customers onto isolated and independent infrastructures and different staggered deployments.
For the Salesforce core services, in addition to adopting the availability zones, we develop a logical construct, a “cell,” to manage and reduce the blast radius for the customers. A cell is a collection of services serving a group of our customers based on Salesforce Multi-tenant Architecture. It is deployed across multiple availability zones for redundancy within the cell and is isolated from other cells. If a cell is unhealthy, it will only impact the customers on the cell, not customers on other cells.
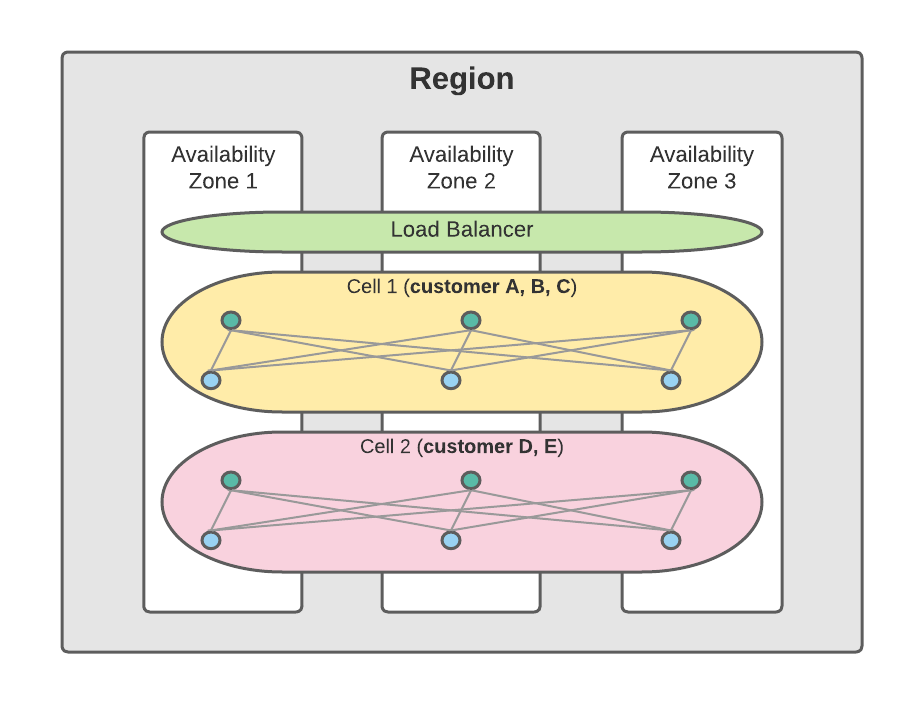
To reduce the blast radius for deploying software releases or changes to our core services, we use a combination of the deployment patterns discussed in the second principle. For example, we may adopt a rolling-upgrade or Blue-Green deploy a new release to the database cluster instances within a cell. We may canary on a small set of cells, and then stagger the deployment across other cells.
4. Take advantage of the elastic capacity
Capacity is also one major contributing factor to service disruptions. We talked about adopting static stability as our deployment and capacity principle at the macro level in the first principle. We also mentioned the Salesforce multi-tenant architecture and how customers are sharing the compute and other infrastructure capacities within a cell.
Now, let’s go further into how we manage capacity at the cell level and how we tackle challenges such as “noisy neighbors.”
For each cell, we deploy intelligent protection that can detect abnormal or excess usages, such as denial of service attacks. We can block or throttle at the level of one or more customers, requests, or resources. In addition, for organic production workload increases, we take advantage of the public cloud elasticity to automatically scale the application computing within a cell as needed. At the transactional database tier, we can automatically scale the storage throughput and space. We can scale the read requests by deploying read-only standby instances.
Another example of using the public cloud elastic capacity is the Blue-Green deployment. We deploy full capacity for the new version at the run time.
5. Design to withstand dependency failures
Ask yourself this question – what happens to my service if one of the dependent services fails?
One design goal for our services is to handle dependency failures gracefully. First of all, your service should always have an error or response code that clearly indicates the failure is caused by a specific dependent service. Be aware of the depth of the error call stacks as it may hinder the ability to pinpoint the dependent service failures.
The service should have programmatic logic, such as retry and timeout, for handling errors and exceptions when a dependent service is unavailable or is behaving unexpectedly. For example, a dependent service is returning intermittent failures or unavailable, service call hanging, etc.
The service may be able to provide reduced functionalities if a dependent service fails. For example, when an unplanned primary database incident happens in a cell, the Salesforce core application can continue to serve read requests from the cache or the read replica databases, until the failover completes to promote one of the standby databases to become the new primary database.
Another key learning is to avoid circular dependencies of services. These can be developed unintentionally over time and can be buried behind many layers of service dependencies. Create a clear dependency graph of the architecture and avoid any circular dependency.
6. Measure, learn, and improve continuously
What do we want to measure and improve?
For Salesforce Hyperforce services, we define metrics for measuring request rate, error rate, response time, availability, and saturation. For every service disruption, we measure and report the time-to-detect (TTD) and time-to-resolve (TTR). We conduct retrospective reviews for every incidents. The goal of the review is to learn the root cause of the incident, understand if we have any technical or procedural gaps, and take action to address the gaps to avoid repeating them in the future.
Conclusion
By sharing these principles and the lessons we learned, we hope to help you understand how Salesforce provides high availability for our customers on the Hyperforce platform.
Take a look at these principles and think about how they apply to your service and architecture, and join us on the journey to ever-improving service availability and trust for our customers!
Follow along with the entire series:



